A New AI Research Proposes VanillaNet: A Novel Neural Network Architecture Emphasizing the Elegance and Simplicity of Design while Retaining Remarkable Performance in Computer Vision Tasks
Artificial neural networks have advanced significantly over the past few decades, propelled by the notion that more network complexity results in better performance. These networks may carry out a range of human-like activities, including face recognition, speech recognition, object identification, natural language processing, and content synthesis, which include several layers and a lot of neurons or transformer blocks. Modern technology has amazing processing capacity, enabling neural networks to perform these jobs excellently and efficiently. As a result, AI-enhanced technology, such as smartphones, AI cameras, voice assistants, and autonomous cars, is increasing in their daily lives.
Undoubtedly, one significant accomplishment in this area is the creation of AlexNet, a neural network with 12 layers that performs at the cutting edge on the large-scale image recognition benchmark. ResNet expands on this achievement by including identity mappings through shortcut connections, enabling the training of deep neural networks with good performance across various computer vision applications, including image classification, object identification, and semantic segmentation. The representational capabilities of deep neural networks have unquestionably been improved by the inclusion of human-designed modules in these models and the ongoing rise in network complexity, sparking a flurry of research on how to train networks with more complex architectures to achieve even higher performance.
Previous research included transformer topologies to image recognition tasks in addition to convolutional structures, showcasing its potential for using massive amounts of training data. With an outstanding 90.45% top-1 accuracy on the ImageNet dataset, some explored the scaling laws of vision transformer topologies. This result shows that deeper transformer architectures, like convolutional networks, often display greater performance. For even more precision, some further suggested extending the depth of transformers to 1,000 layers. By revisiting the design space for neural networks and introducing ConvNext, and were able to match the performance of cutting-edge transformer topologies. Deep and complicated neural networks with good optimization can function satisfactorily, but deployment becomes more difficult as complexity rises.
For instance, ResNets shortcut procedures that combine features from many levels significantly use off-chip memory traffic. Furthermore, technical implementation, including rewriting CUDA codes, is needed for complex operations like the axial shift in AS-MLP and shift window self-attention in Swin Transformer. These difficulties need a paradigm change in neural network design toward simplicity. However, neural networks with only convolutional layers (and no additional modules or shortcuts) have been abandoned in favor of ResNet. This is mostly because the performance improvement brought about by including convolutional layers fell below expectations. According to, a 34-layer plain network performs worse than an 18-layer one due to gradient vanishing, a problem with plain networks without shortcuts.
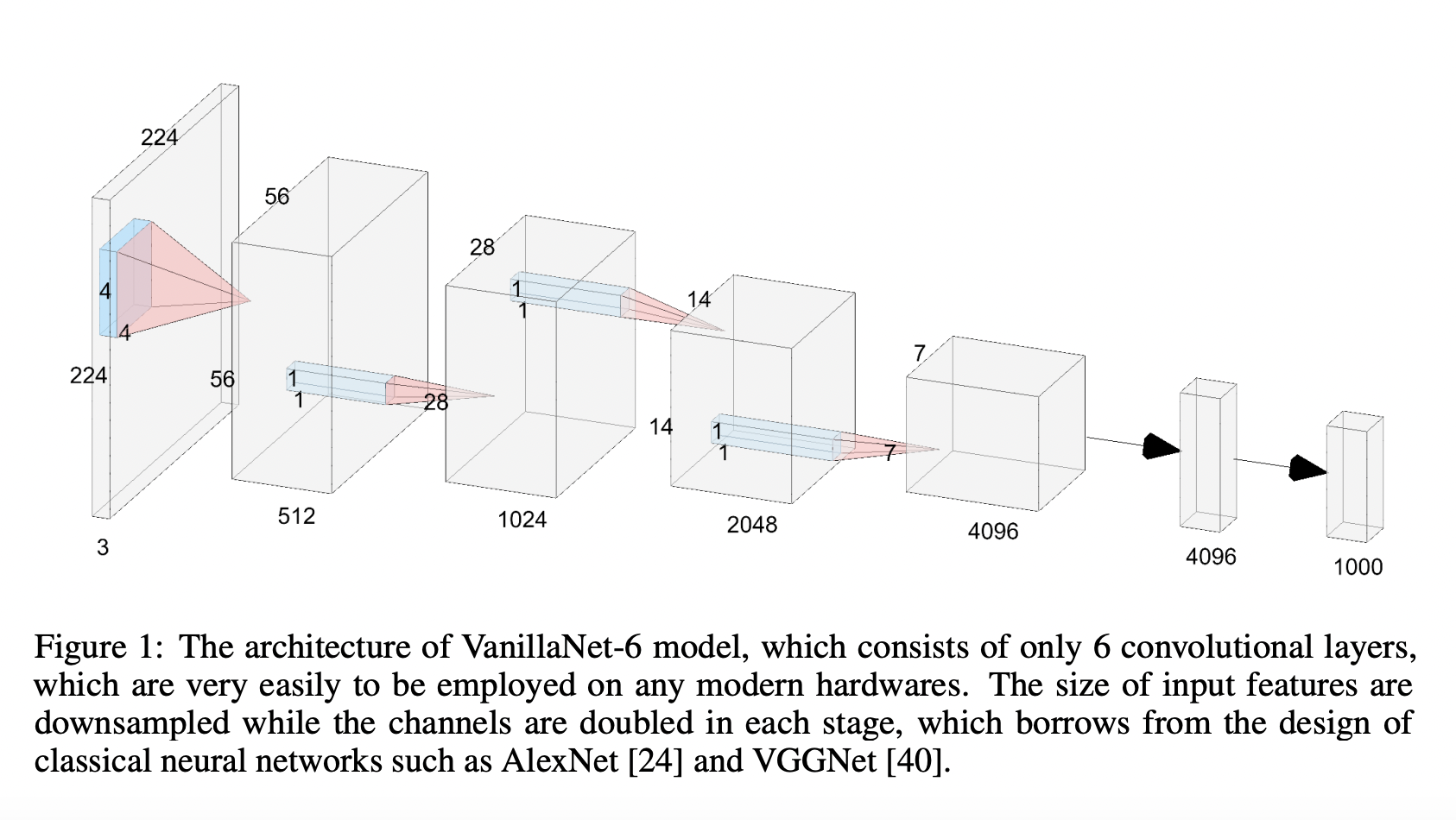
Deep and sophisticated networks, including ResNets and ViT, have also significantly outperformed simpler networks like AlexNet and VGGNet in terms of performance. As a result, the design and optimization of neural networks with basic topologies have received less attention. It would be very beneficial to address this problem and create efficient models. To achieve this, researchers from Huawei Noah’s Ark Lab and University of Sydney suggest VanillaNet, a cutting-edge neural network architecture that emphasizes design’s beauty and simplicity while achieving outstanding performance in computer vision applications. VanillaNet accomplishes this by avoiding excessive depth, shortcuts, and difficult procedures like self-attention. As a result, several streamlined networks are created that handle the problem of inherent complexity and are suitable for contexts with low resources.
They thoroughly examine the issues brought on by their reduced designs and develop a “deep training” technique to train their suggested VanillaNets. This method begins with several layers that have non-linear activation functions. They gradually remove these non-linear layers throughout training, making merging simple while maintaining inference speed. They propose an effective, series-based activation function with several learnable affine modifications to increase the networks’ non-linearity. It has been shown that using these strategies considerably improves the performance of less sophisticated neural networks. VanillaNet outperforms modern networks with complex topologies in effectiveness and precision, demonstrating the promise of a straightforward deep-learning strategy. By questioning the accepted standards of foundation models and charting a new course for developing precise and efficient models, this groundbreaking examination of VanillaNet opens the door for a new approach to neural network architecture. The PyTorch implementation is available on GitHub.
Check out the Paper and Github Link. Don’t forget to join our 26k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 800+ AI Tools in AI Tools Club
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.