A new AI theoretical framework to analyze and bound information leakage from machine learning models
ML algorithms have raised privacy and security concerns due to their application in complex and sensitive problems. Research has shown that ML models can leak sensitive information through attacks, leading to the proposal of a novel formalism to generalize and connect these attacks to memorization and generalization. Previous research has focused on data-dependent strategies to perform attacks rather than creating a general framework to understand these problems. In this context, a recent study was recently published to propose a novel formalism to study inference attacks and their connection to generalization and memorization. This framework considers a more general approach without making any assumptions on the distribution of model parameters given the training set.
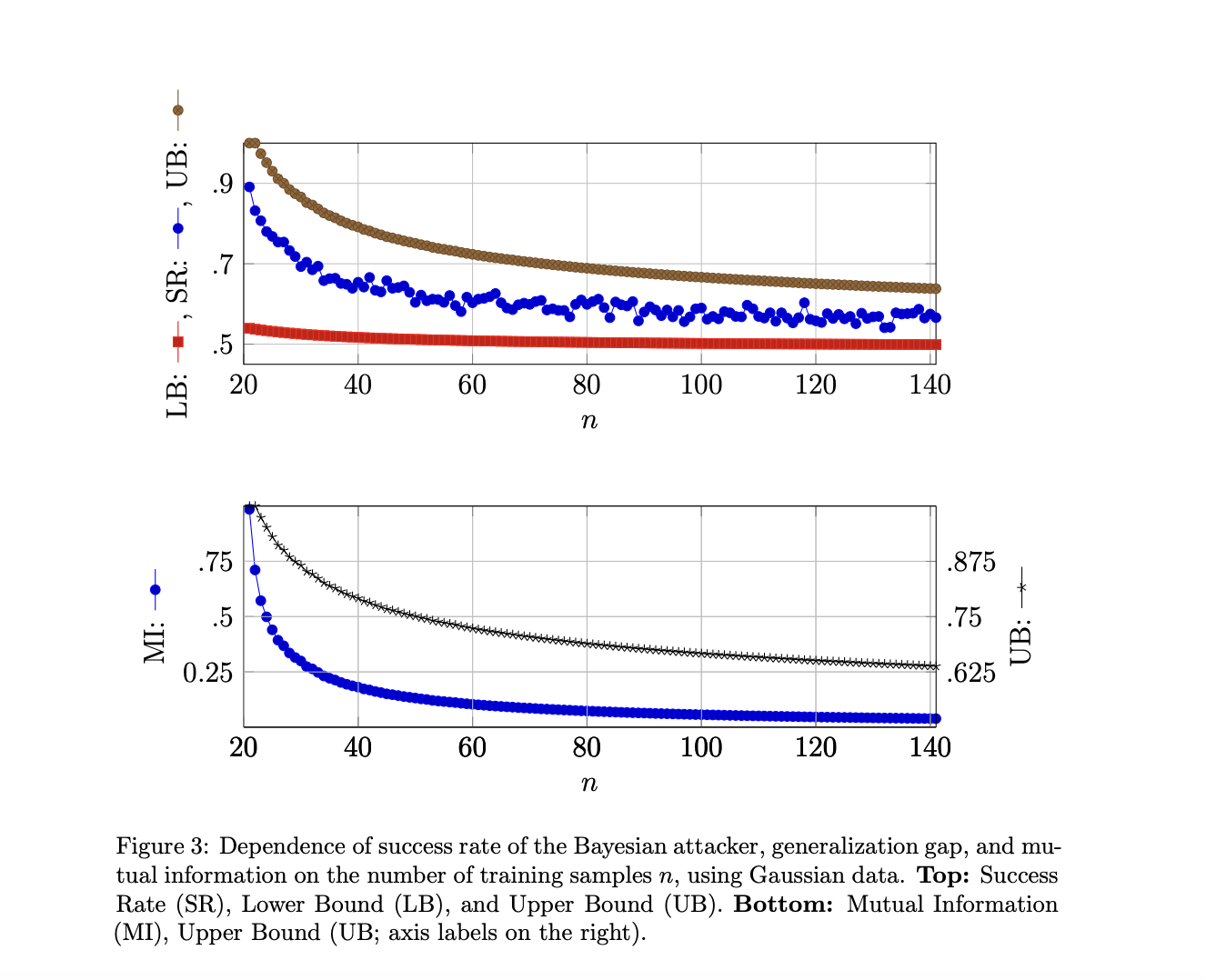
The main idea proposed in the article is to study the interplay between generalization, Differential Privacy (DP), attribute, and membership inference attacks from a different and complementary perspective than previous works. The article extends the results to the more general case of tail-bounded loss functions and considers a Bayesian attacker with white-box access, which yields an upper bound on the probability of success of all possible adversaries and also on the generalization gap. The article shows that the converse statement, ‘generalization implies privacy’, has been proven false in previous works and provides a counter-proof by giving an example where the generalization gap tends to 0 while the attacker achieves perfect accuracy. Concretely, this work proposes a formalism for modeling membership and/or attribute inference attacks on machine learning (ML) systems. It provides a simple and flexible framework with definitions that can be applied to different problem setups. The research also establishes universal bounds on the success rate of inference attacks, which can serve as a privacy guarantee and guide the design of privacy defense mechanisms for ML models. The authors investigate the connection between the generalization gap and membership inference, showing that bad generalization can lead to privacy leakage. They also study the amount of information stored by a trained model about its training set and its role in privacy attacks, finding that mutual information upper bounds the gain of the Bayesian attacker. Numerical experiments on linear regression and deep neural networks for classification demonstrate the effectiveness of the proposed approach in assessing privacy risks.
The research team’s experiments provide insight into the information leakage of machine learning models. By using bounds, the team could assess the success rate of attackers and lower bounds were found to be a function of the generalization gap. These lower bounds can’t guarantee that no attack can perform better. Still, if the lower bound is higher than random guessing, then the model is considered to leak sensitive information. The team demonstrated that models susceptible to membership inference attacks could also be vulnerable to other privacy violations, as exposed through attribute inference attacks. The effectiveness of several attribute inference strategies was compared, showing that white-box access to the model can yield significant gains. The success rate of the Bayesian attacker provides a strong guarantee of privacy, but computing the associated decision region seems computationally infeasible. However, the team provided a synthetic example using linear regression and Gaussian data, where it was possible to calculate the involved distributions analytically.
In conclusion, the growing use of Machine Learning (ML) algorithms has raised concerns about privacy and security. Recent research has highlighted the risk of sensitive information leakage through membership and attribute inference attacks. To address this issue, a novel formalism has been proposed that provides a more general approach to understanding these attacks and their connection to generalization and memorization. The research team established universal bounds on the success rate of inference attacks, which can serve as a privacy guarantee and guide the design of privacy defense mechanisms for ML models. Their experiments on linear regression and deep neural networks demonstrated the effectiveness of the proposed approach in assessing privacy risks. Overall, this research provides valuable insights into the information leakage of ML models and highlights the need for continued efforts to improve their privacy and security.
Check out the Research Paper. Don’t forget to join our 20k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Mahmoud is a PhD researcher in machine learning. He also holds a
bachelor’s degree in physical science and a master’s degree in
telecommunications and networking systems. His current areas of
research concern computer vision, stock market prediction and deep
learning. He produced several scientific articles about person re-
identification and the study of the robustness and stability of deep
networks.
Credit: Source link
Comments are closed.