A New Apple AI Study Investigates Whether Self-Supervised and Supervised Methods Learn Similar Visual Representations

Self-supervised learning (SSL) is an ML technique that allows computers to predict unknown inputs using observed inputs. One essential goal for self-supervised learning is to turn unsupervised learning models into supervised learning models programmatically. It does it by constructing pre-training deep learning systems that can learn to fill in missing knowledge.
In recent years, self-supervised learning (SSL) algorithms have been decreasing the performance gap with standard supervised learning (SL) approaches for performing visual problems.
A new study conducted by Apple researchers investigates whether self-supervised and supervised methods learn similar visual representations. This research reveals the similarities and differences between learned visual representation patterns of contrastive SSL algorithm (SimCLR) and SL on common model architecture.
SimCLR is a basic framework for contrastive learning of visual representations. It learns its representations using a contrastive loss to maximize the agreement between multiple augmented views of the same data.
The researchers used Centered Kernel Alignment (CKA) as a similarity metric to compare neuronal representation spaces because of the distributed nature, probable misalignment, and high dimensionality concerns.


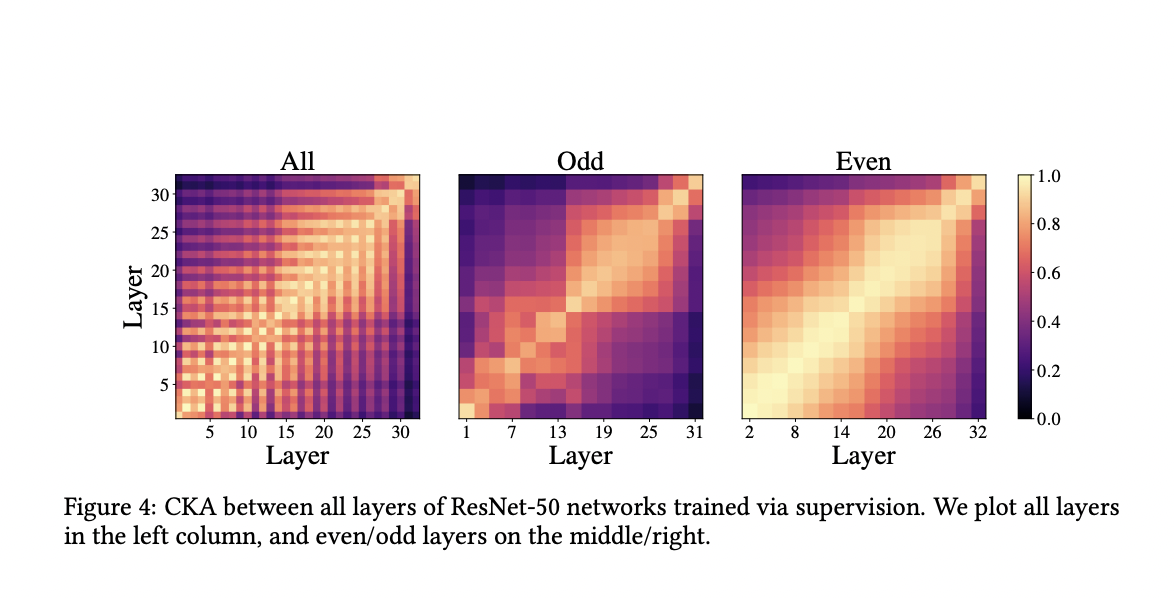
In their evaluation trials, the team used a ResNet-50 (R50) backbone for each model. They initially used CKA to investigate the internal representational similarities of network layers on R50s trained using SimCLR. They then plotted the odd and even layer CKA matrices across the learning methods to compare the representative structures created by SimCLR and SL.
In terms of SimCLR’s augmentation invariance objective, the researchers looked into what happens in the layers of both networks. They observed the degree of invariance at each layer by plotting the CKA value between the representations. Then they demonstrated the CKA similarity of class representations and learned representations across various SimCLR and SL networks layers.

The key findings of the research are mentioned below:
- Although post-residual representations are similar across methods, residual (block-interior) representations are not; a similar structure is recovered by solving different problems.
- The residual layers’ initial representations are comparable, suggesting a shared collection of primitives.
- In the final few layers, SimCLR learns augmentation invariance and SL fits the class structure, the methods strongly t to their distinct objectives.
- Although SL does not implicitly learn augmentation invariance, it does fit the class structure and induces linear separability.
- Because the representational structures vary dramatically in the final layers, SimCLR’s performance relies on class-informative intermediate representations rather than an implicit structural agreement between learned solutions to the SL and SimCLR objectives.
The research demonstrates CKA’s ability to compare learning methods and reveals that the similarity of intermediate representations, rather than the similarity of final representational structures, allows SimCLR to achieve its spectacular results. The researchers hope their findings show the relative importance of learned intermediate representations and provide significant insights for future auxiliary task design research and techniques.
Paper: https://arxiv.org/pdf/2110.00528.pdf
References: https://syncedreview.com/2021/10/08/deepmind-podracer-tpu-based-rl-frameworks-deliver-exceptional-performance-at-low-cost-120/
Suggested
Credit: Source link
Comments are closed.