A New Artificial Intelligence (AI) Study Proposes A 3D-Aware Blending Technique With Generative NeRFs
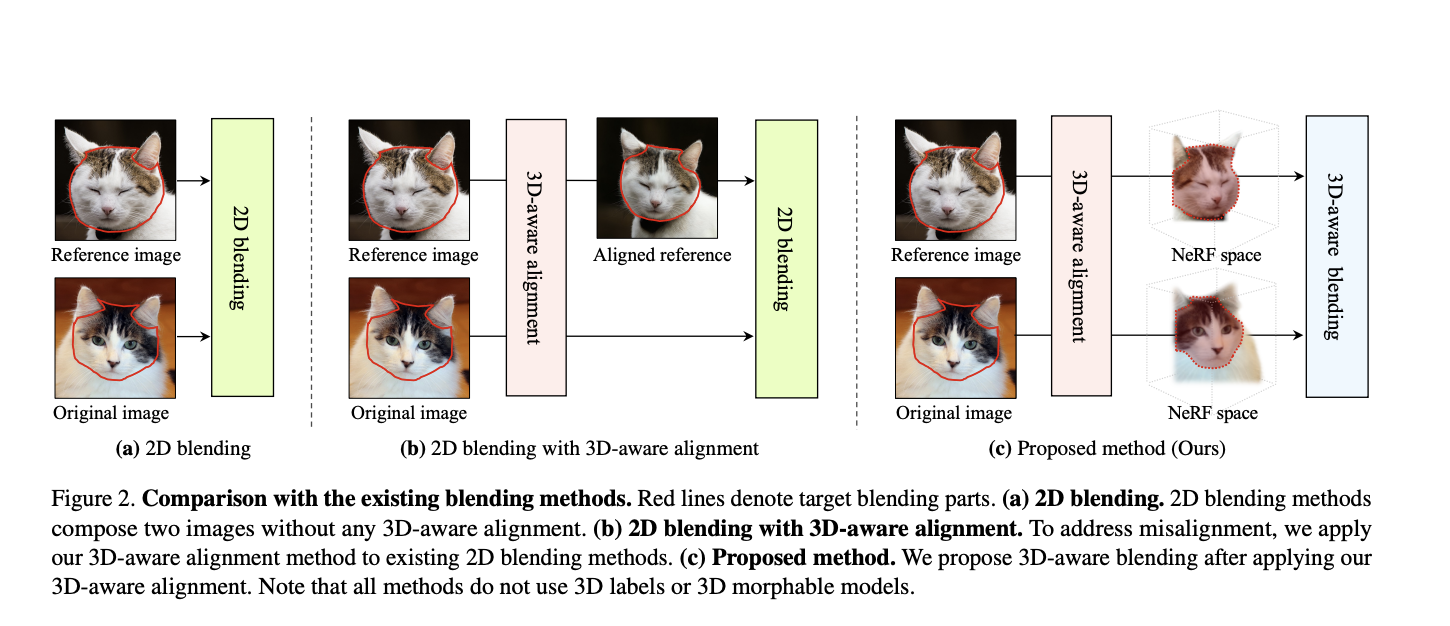
Image blending is a primary method in computer vision, one of the most known branches in the artificial intelligence component. The goal is to blend two or more images to produce a unique combination that incorporates the finest aspects of each input image. This method is extensively used in various application fields, including picture editing, computer images, and medical imaging.
Image blending is frequently used in artificial intelligence activities such as picture segmentation, object identification, and image super-resolution. It is critical in improving image clarity, which is essential for many uses, such as robotics, automated driving, and surveillance.
Over the years, several image blending techniques have been created, primarily relying on warping an image via 2D affine transformation. However, these approaches do not account for the discrepancy in 3D geometric features like pose or shape. 3D alignment is much more challenging to achieve, as it requires inferring the 3D structure from a single view.
To address this issue, a 3D-aware image blending method based on generative Neural Radiance Fields (NeRFs) has been proposed.
The purpose of generative NeRFs is to learn a strategy to synthesize images in 3D using only collections of 2D single-view images. Therefore, the authors project the input images to the volume density representation of generative NeRFs. To reduce the dimensionality and complexity of data and operations, the 3D-aware blending is then performed on these NeRFs’ latent representation spaces.
Concretely, the formulated optimization problem considers the latent code’s impact in synthesizing the blended image. The goal is to edit the foreground based on the reference images while preserving the background of the original image. For instance, if the two considered images were faces, the framework must replace the facial characteristics and features of the original image with the ones from the reference image while keeping the rest unchanged (hair, neck, years, surroundings, etc.).
An overview of the architecture compared to previous strategies is proposed in the picture below.

The first method consists of the sole 2D blending of two 2D images without alignment. An improvement can be found by supporting this 2D blending method with the 3D-aware alignment with generative NeRFs. To further exploit 3D information, the final architecture infers on two images in NeRFs’ latent representation spaces instead of 2D pixel space.
3D alignment is achieved via a CNN encoder, which infers the camera pose of each input image, and via the latent code of the image itself. Once the reference image is correctly rotated to reflect the original image, the NeRF representations of both images are computed. Lastly, the 3D transformation matrix (scale, translation) is estimated from the original image and applied to the reference image to obtain a semantically-accurate blend.
The results on unaligned images with different poses and scales are reported below.

According to the authors and their experiments, this method outperforms both classic and learning-based methods regarding both photorealism and faithfulness to the input images. Additionally, exploiting latent-space representations, this method can disentangle color and geometric changes during blending and create view-consistent results.
This was the summary of a novel AI framework for 3D-aware Blending with Generative Neural Radiance Fields (NeRFs).
If you are interested or want to learn more about this framework, you can find below a link to the paper and the project page.
Check out the Paper, Github, and Project. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 15k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Daniele Lorenzi received his M.Sc. in ICT for Internet and Multimedia Engineering in 2021 from the University of Padua, Italy. He is a Ph.D. candidate at the Institute of Information Technology (ITEC) at the Alpen-Adria-Universität (AAU) Klagenfurt. He is currently working in the Christian Doppler Laboratory ATHENA and his research interests include adaptive video streaming, immersive media, machine learning, and QoS/QoE evaluation.
Credit: Source link
Comments are closed.