A New Artificial Intelligence Research Proposes ExaRanker: Exploring the Role of Natural Language Explanations in Improving Information Retrieval Models
Information retrieval (IR) problems saw considerable improvements to trained transformers like BERT and T5, refined on millions of cases. A model is expected to perform better than unsupervised models when the queries and documents from a job of interest are comparable to those in the fine-tuning data. For instance, in 15 of 18 datasets of the BEIR benchmark, a monoT5 reranked outperforms BM25 after being fine-tuned on 400k positive query-passage pairs from MS MARCO. However, the model’s performance drastically declines when the number of labeled examples is constrained.
For instance, in the MS MARCO passage ranking benchmark, a BERT reranker that was fine-tuned using 10k query-relevant passage pairs only slightly outperforms BM25. The requirement for more fine-tuning data can be reduced at the price of greater processing resources by growing the model’s size or pretraining it on IR-specific targets. They contend that categorical labels (such as true/false) are used to fine-tune neural retrievers, which is one reason they require large numbers of training samples. These labels need more context for the job that has to be learned, making it harder for the model to understand its subtleties.
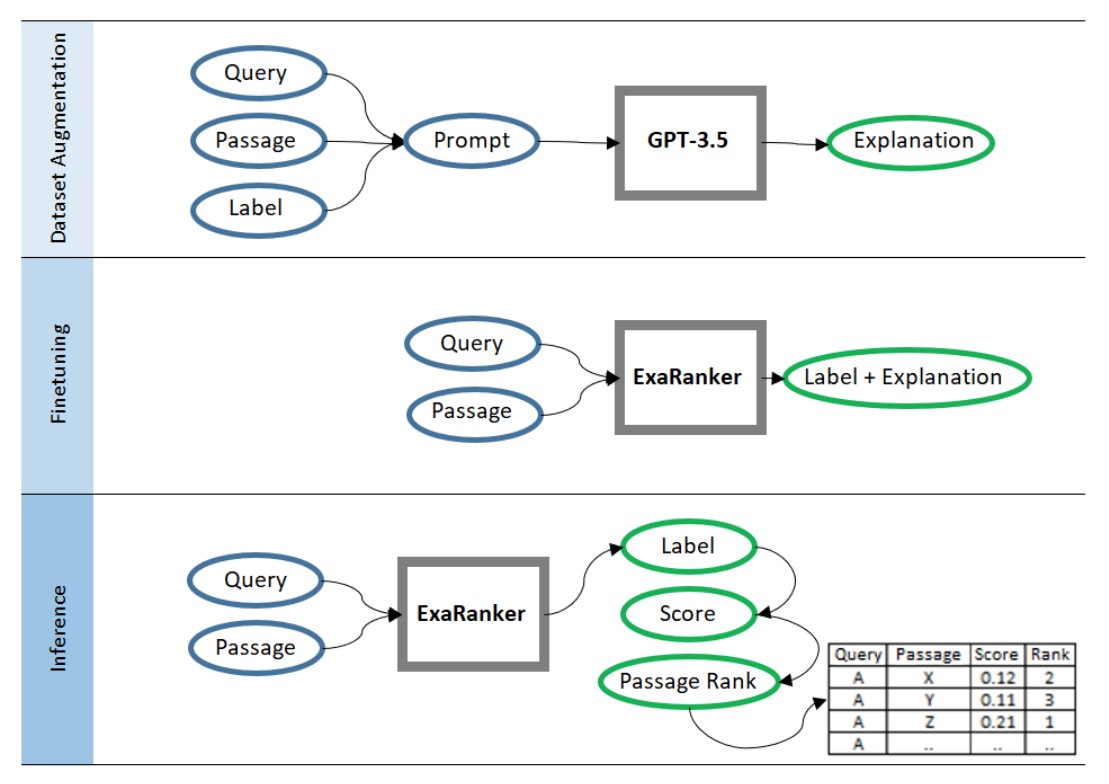
Consider the scenario where you are trying to educate a person to assess the relevance of passages to queries. Still, you can only convey “true” or “false” for each query-passage pair. The learning process would be more effective if justifications for why a paragraph is relevant or not to a certain inquiry were supplied in straightforward terms. This study provides a technique for training retrieval models that eliminates the requirement for training instances by employing natural language explanations as extra labels. It starts by using an LLM model with in-context examples to provide explanations for query-passage-label triples. Figure 1 depicts the suggested method.
After adding the created explanations to these training triples, a sequence-to-sequence model is adjusted to produce the target label followed by the explanation. Based simply on the probability given to the label token, the fine-tuned model is utilized to calculate the relevance of a query-passage combination during the inference phase. Additionally, they demonstrate how few-shot LLMs like GPT-3.5 can be successfully used to automatically add justifications to training examples, allowing IR experts to adapt their approach to additional datasets without needing manual annotation.
Their findings suggest that as the quantity of training instances rises, the usefulness of integrating explanations declines. Furthermore, their research shows that when a model is tuned to create a label before an explanation, performance is greater than when an explanation is generated before the target label. This result may need to be more logical and at odds with earlier findings in chain-of-thought studies.
Finally, they demonstrated that these explanations could be efficiently produced using large language models, opening the door for implementing their approach in various IR domains and activities. Importantly, our technique dramatically reduces the time needed to rerank passages because just the true/false token is employed during inference. The accompanying repository makes the source code and data sets used in this study accessible to the public for subsequent analyses and improvements of the ExaRanker algorithm. They have shared a repository with the code implementation and dataset.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 13k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.