A New Generative Model for Videos in Projected Latent Space Improves SOTA Score and Reduces GPU Memory Use
Deep generative models have recently made advancements that have demonstrated their potential to create high-quality, realistic samples in various domains, including photos, audio, 3D sceneries, natural languages, etc. Several studies have been actively concentrating on the more difficult job of video synthesis as a following step. Because of the great dimensionality and complexity of videos, which contain intricate spatiotemporal dynamics in high-resolution frames, the generation quality of videos still needs to be improved from that of real-world videos, in contrast to the success in other fields. Recent efforts to create diffusion models for videos have been motivated by the success of diffusion models in managing large-scale, complicated picture collections.
These techniques, similar to those used for picture domains, have shown significant promise for modeling video distribution considerably more accurately with scalability (spatial resolution and temporal durations), even obtaining photorealistic generation outcomes. Unfortunately, as diffusion models need several repeated processes in input space to synthesize samples, they need better computing and memory efficiency. Due to the cubic RGB array construction, such bottlenecks in the video are considerably more accentuated. Nevertheless, new efforts in picture production have developed latent diffusion models to get around the computing and memory inefficiencies of diffusion models.
Contribution. Instead of training the model in raw pixels, latent diffusion approaches train an autoencoder to quickly learn a low-dimensional latent space parameterizing images, then model this latent distribution. It’s fascinating to remark that the technique has significantly improved sample synthesis effectiveness and even attained cutting-edge generation results. Despite their appealing potential, videos have yet to receive the consideration they merit in creating a latent diffusion model. They provide a novel latent diffusion model for movies called projected latent video diffusion (PVDM).
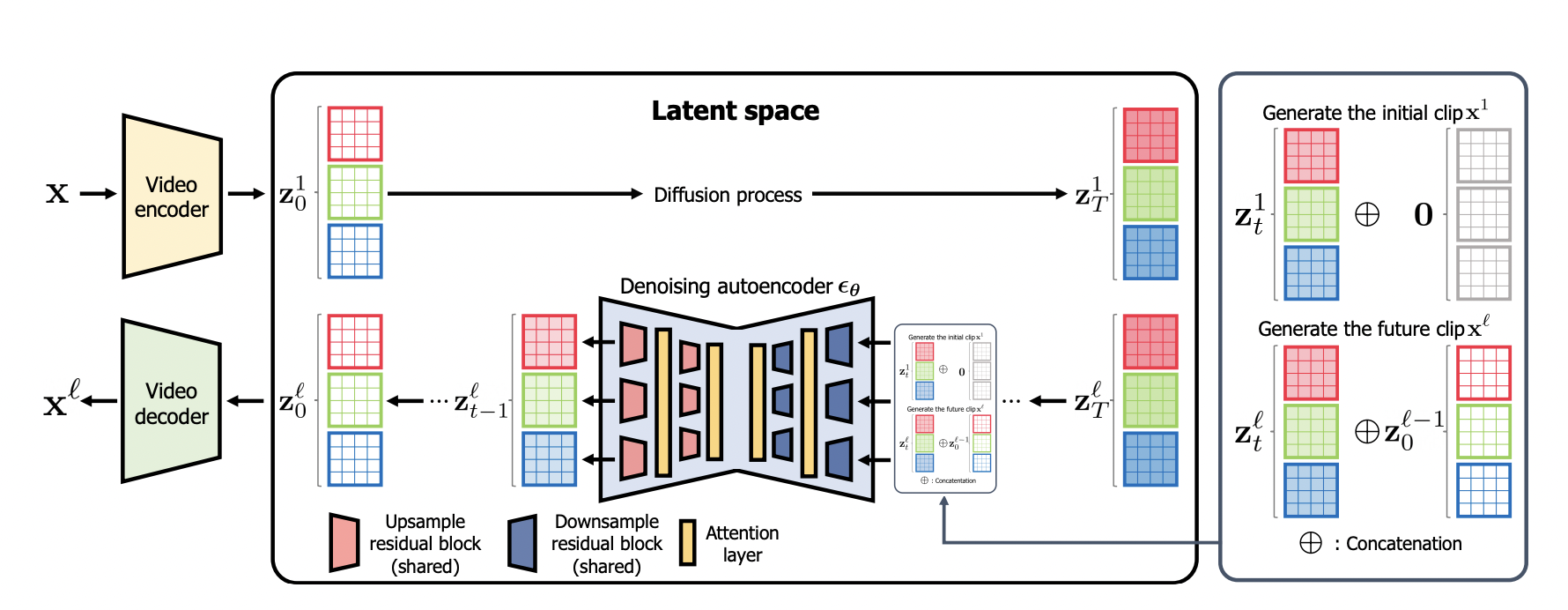
It has two stages specifically (see Figure 1 below for a general illustration):
• Autoencoder: By factorizing the intricate cubic array structure of movies, they describe an autoencoder that depicts a video with three 2D imagelike latent vectors. To encode 3D video pixels as three condensed 2D latent vectors, they specifically propose 3D 2D projections of films at each spatiotemporal direction. To parameterize the common video components (such as the backdrop), they create one latent vector that spans the temporal direction. The last two vectors are then used to encode the motion of the video. Due to their imagelike structure, these 2D latent vectors are useful for attaining high-quality and concise video encoding and creating a computation-efficient diffusion model architecture.
• Diffusion model: To represent the distribution of videos, they create a new diffusion model architecture based on the 2D imagelike latent space created by their video autoencoder. They avoid using the computationally intensive 3D convolutional neural network architectures often utilized for processing movies because they parameterize videos as imagelike latent representations. Their design, which has demonstrated its power in processing pictures, is instead based on a 2D convolution network diffusion model architecture. To create a lengthy film of any duration, they also provide a combination training of unconditional and frame conditional generative modeling.

They use UCF101 and SkyTimelapse, two well-liked datasets for assessing video creation techniques, to confirm the efficacy of their method. The inception score (IS; greater is better) on UCF-101, a sample measure for total video production, shows that PVDM generates films with 16 frames and 256256 resolution at a state-of-the-art score of 74.40. In terms of Fréchet video distance (FVD; lower is better), it dramatically raises the score from 1773.4 of the previous state-of-the-art to 639.7 on the UCF-101 while synthesizing lengthy films (128 frames) of 256256 quality.
Additionally, their model exhibits great memory and computing efficiency compared to prior video diffusion models. For instance, a video diffusion model needs practically the whole memory (24GB) on a single NVIDIA 3090Ti 24GB GPU to train at 128128 resolution with a batch size of 1. On the other hand, PVDM can only be trained on this GPU with 16-frame movies at 256×256 resolution and a batch size of no more than 7. The suggested PVDM is the first latent diffusion model created specifically for video synthesis. Their work will help video generation research move towards effective real-time, high-resolution, and lengthy video synthesis while working within the limits of low computational resource availability. PyTorch implementation will be made open source soon.
Check out the Paper, Github and Project Page. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 14k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.