A New Google AI Study Introduces A Mask R-CNN–Based Model For Solving Instance Segmentation Problem

Computer vision (CV) is transforming industries and making life easier for consumers. Many downstream applications, such as self-driving cars, robots, medical imaging, and photo editing, have grown dependent on CV tasks. One of the core CV tasks includes Instance segmentation. It involves grouping pixels in a picture into instances of particular entities and identifying them with a class label.
With Mask R-CNN architectures, deep learning has made tremendous progress in solving the instance segmentation problem in recent years. These approaches, however, need the collection of a large labelled instance segmentation dataset. Unlike bounding box labels, collecting instance segmentation labels (also known as “masks”) is time-consuming and expensive.
The partially supervised instance segmentation setting requires only a small set of labelled classes with instance segmentation masks. The remaining (majority of) classes are labelled only with bounding boxes. This method reduces reliance on manually constructed mask labels, significantly cutting the obstacles to building an instance segmentation model. However, this partially supervised approach requires a stronger model generalization to handle novel classes not observed during training.
Furthermore, naive approaches like training a class-agnostic Mask R-CNN while ignoring mask losses for all cases without mask labels have failed miserably.
A recent Google study looks into the major causes of Mask R-CNN’s poor performance on novel classes. It proposes two simple improvements (one for the training process and one for the mask-head design) that work together to reduce the gap to fully supervised performance. Their proposed Mask R-CNN–based model outperforms the existing state-of-the-art by 4.7 per cent mask mAP.
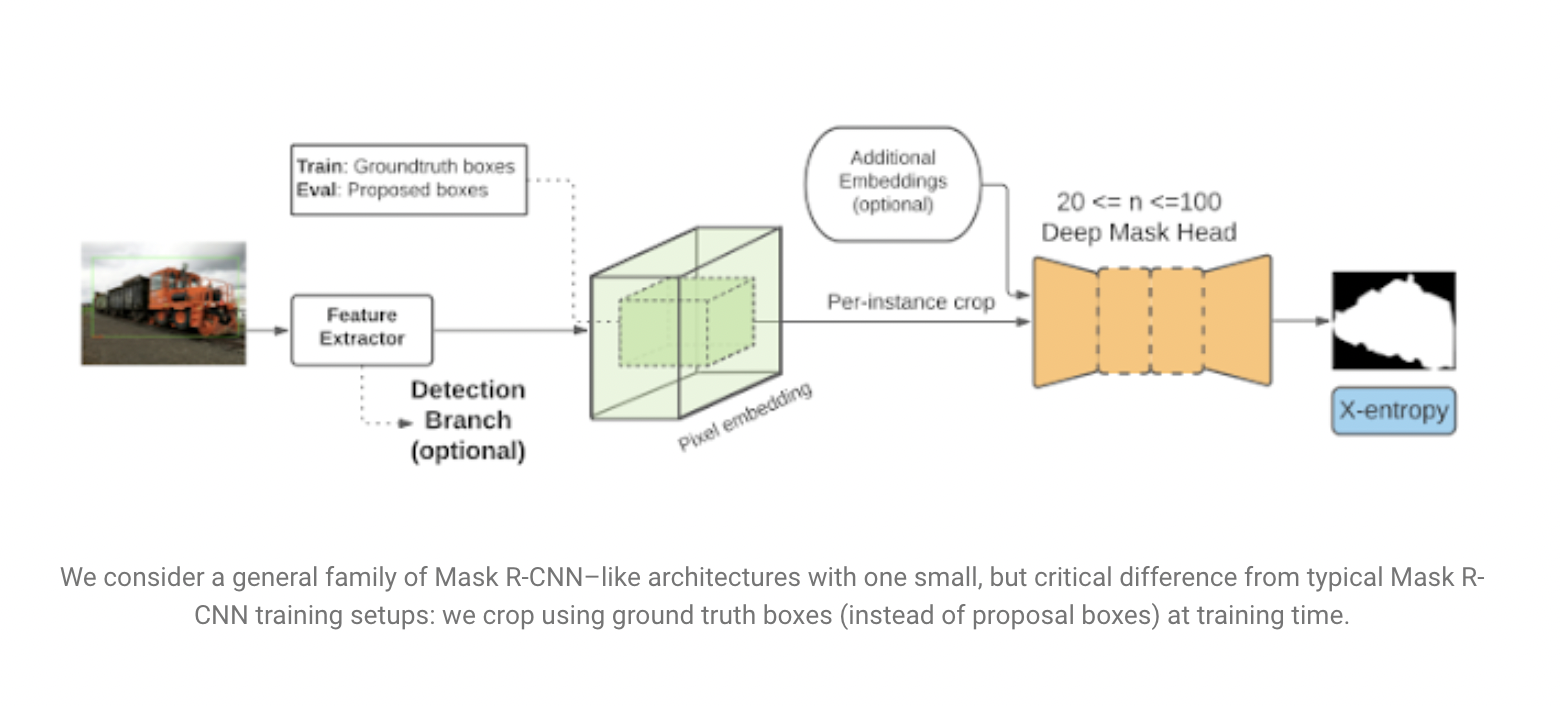
Their method can be used to any crop-then-segment model, such as a Mask R-CNN or Mask R-CNN-like architecture that computes a feature representation of the full picture before passing per-instance crops to a second-stage mask prediction network.
Consequences of Cropping Methodology in Partially Supervised Settings
The Cropping—Mask R-CNN is trained in two steps. First, it is trained by cropping a feature map and the ground truth mask to a bounding box corresponding to each instance. These cropped features are then fed into a mask-head network, which creates a final mask prediction and compares it to the ground truth crop in the mask loss function.

Cropping can be done in two ways: (1) cropping directly to an instance’s ground truth bounding box, or (2) cropping to bounding boxes predicted by the model (called proposals). Because ground truth boxes are not expected to be present at test time, cropping is always done using proposals.
Both sorts of crops are passed to the mask head in most Mask R-CNN implementations. However, because performance in the fully supervised configuration is unaffected by this choice, it is usually seen as a minor technical issue. In contrast, the researchers suggest that cropping methodology plays a significant role in partially supervised settings. While cropping solely to ground-truth boxes during training has no effect in a fully supervised situation, it significantly improves performance on unseen classes in a partially supervised setting.

Surprisingly, when cropping-to-ground truth is enabled during training, the mask head of Mask R-CNN plays a disproportionate role in the model’s capacity to generalize to unknown classes.
It’s worth noting that these distinctions between mask-head designs aren’t as noticeable in the fully supervised setting. This may also explain why prior instance segmentation work has almost exclusively used shallow (i.e., low number of layers) mask heads, as the increased complexity has provided no benefit.
The researchers examine the mask mAP of three distinct mask-head topologies on seen versus unseen classes. All three models perform equally well on the set of seen classes, but the deep hourglass mask heads stand out when used on unseen classes. The hourglass mask heads were found to be the best among all architectures, and the team employed hourglass mask heads with 50 or more layers to achieve the greatest results.

The researchers trained a Mask R-CNN model with cropping-to-ground-truth enabled and a deep Hourglass-52 mask head with a SpineNet backbone (1280×1280) on high-resolution images. This model is known as Deep-MARC (Deep Mask heads Above R-CNN), and it outperforms previous state-of-the-art models by > 4.5 per cent mask mAP without offline training or hand-crafted priors. They also see significant results using a CenterNet-based (as opposed to Mask R-CNN-based) model (named Deep-MAC) that outperforms the other state of the art, demonstrating the universal nature of this approach. The codebases for two versions of the concept, Deep-MAC and Deep-MARC, are now made open-source.
Paper: https://arxiv.org/pdf/2104.00613.pdf
Code: https://google.github.io/deepmac/#code
Source: https://ai.googleblog.com/2021/09/revisiting-mask-head-architectures-for.html
Suggested
Credit: Source link
Comments are closed.