A New Google Research Introduces ALX For Large Scale Matrix Factorization on TPUs

One of the most important approaches in recommender systems and graph analysis is matrix factorization. Alternating least squares (ALS) is a basic approach for learning matrix factorization parameters. This method is noted for its excellent efficiency, scaling linearly in rows, columns, and non-zero numbers, making it suitable for large-scale challenges.
Deep learning’s recent success has sparked a new surge of research and development in hardware accelerators. Novel ways for allocating computation and model weights have been investigated as the training set and model sizes rise.
A new Google study presents ALX, an open-source library developed in JAX that uses Tensor Processing Unit (TPU) hardware accelerators to enable efficient distributed matrix factorization using Alternating Least Squares. WebGraph is a large-scale, link-prediction dataset created by the team to stimulate more study into strategies for dealing with very large-scale sparse matrices.
The suggested matrix factorization method is inspired by TPUs’ appealing features, which the team characterizes as follows:
- A TPU pod has adequate distributed memory to accommodate sharded embedding tables that are very large.
- TPUs are designed for tasks that benefit from data parallelism. For example, solving a big batch of the system of linear equations is a key process in Alternating Least Squares.
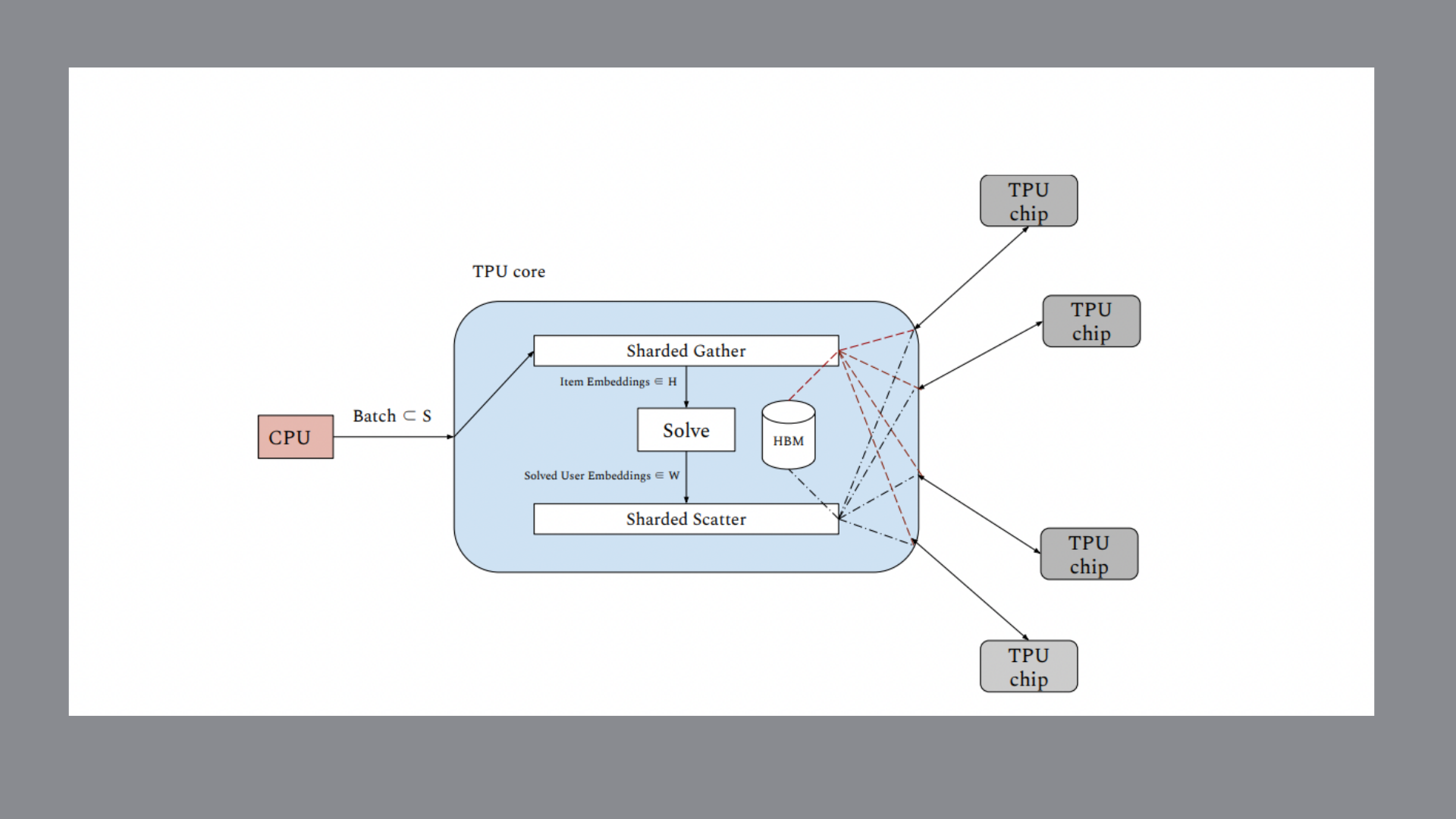
- TPU chips are directly coupled via specialized, high-bandwidth, low-latency interconnects. This allows gather and scatter operations to be performed over a large distributed embedding table stored in TPU memory.
- Traditional ML workloads need a highly dependable distributed arrangement because any node failure can cause the training process to halt. A cluster of TPUs can fulfill this.
All these properties allow the sharding of a large embedding table among all available devices without worrying about replication or fault tolerance.
The team proposes a distributed matrix factorization technique that uses the Alternating Least Squares (ALS) approach for learning matrix factorization parameters to fully utilize available TPU memory. Both user and item embedding tables are uniformly sharded among TPU cores using this manner. Many hosts (each connected to 8 TPU cores) are used in a pod configuration process when a data batch is fed from the host CPU to the attached TPU devices. They ensure that the computational flow is identical and parallelized across multiple batches transmitted to the TPU devices.
To evaluate their work at scale, the team developed WebGraph. This includes a large-scale link prediction dataset comprised of Common Crawl data collected from the Internet and multiple WebGraph variations based on location and sparsity qualities of sub-graphs.
As the number of accessible TPU cores grew, the team looked at the scalability properties of WebGraph variations in terms of training time. According to the experimental data, one epoch of the largest WebGraph version, WebGraph-sparse (365M x 365M sparse matrix), takes roughly 20 minutes to complete with 256 TPU cores, indicating that ALX may safely scale to matrices up to 1B × 1B in size.
The team hopes that their work will spur more research and development into scalable large-scale matrix factorization algorithms and implementations.
Paper: https://arxiv.org/pdf/2112.02194.pdf
Suggested
Credit: Source link
Comments are closed.