A New Machine Learning Research from MIT Shows How Large Language Models (LLMs) Comprehend and Represent the Concepts of Space and Time
Large Language Models (LLMs) have shown some incredible skills in recent times. The well-known ChatGPT, which has been built on the GPT’s transformer architecture, has gained massive popularity due to its human-imitating capabilities. From question answering and text summarization to content generation and language translation, it has a number of use cases. With their excessive popularity, what these models have truly learned during their training has come into question.
According to one theory, LLMs are excellent at spotting and forecasting patterns and correlations in data but fall short in their comprehension of the fundamental mechanisms that produce data. They resemble very competent statistical engines in principle, albeit they might not actually have comprehension. Another theory states that LLMs learn correlations and grow more condensed, coherent, and understandable models of the generative processes underlying the training data.
Recently, two researchers from the Massachusetts Institute of Technology have studied Large Language Models to understand better how they learn. The research particularly explores whether these models actually construct a cohesive model of the underlying data-generating process, frequently referred to as a “world model,” or if they merely memorize statistical patterns.
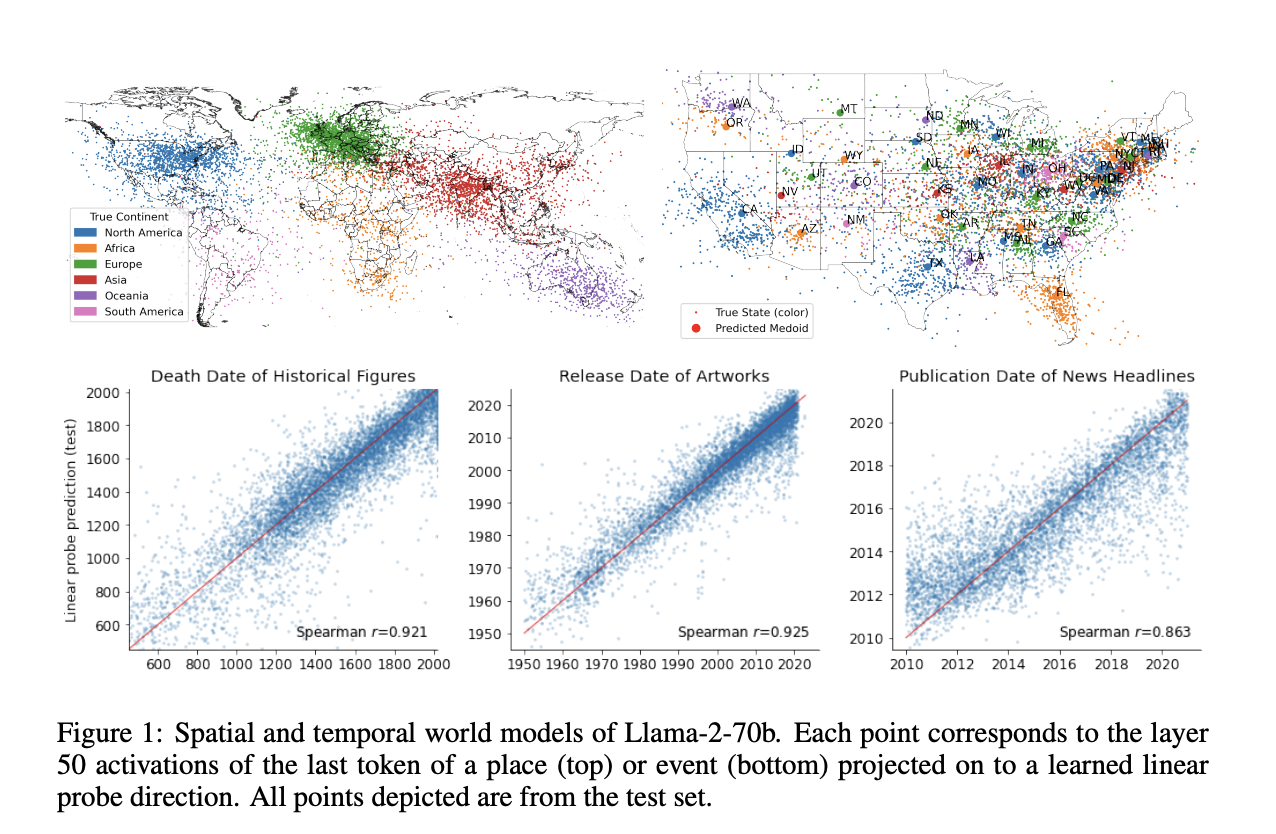
The researchers have used probing tests with a family of LLMs Llama-2 models by creating six datasets that cover different spatiotemporal scales and comprise names of places, events, and the related space or time coordinates. The locations in these databases span the entire world, including the United States New York City, the dates on which works of art and entertainment were first released, and the dates on which news headlines were first published. They have used linear regression probes on the internal activations of the LLMs’ layers to look into whether LLMs create representations of space and time. These probes forecast the precise position or time in the real world corresponding to each dataset name.
The research has shown that LLMs learn linear representations of both space and time at different scales. This implies that the models learn about spatial and temporal aspects in a structured and organized manner. They grasp the relationships and patterns throughout space and time in a methodical way rather than just memorizing data items. It has also been discovered that LLMs’ representations are resilient to changes in instructions or prompts. Even when the manner in which the information is provided differs, the models consistently demonstrate a good understanding and representation of spatial and temporal information.
According to the study, the representations are not restricted to any one particular class of entities. Cities, landmarks, historical individuals, pieces of art, or news headlines are all represented uniformly by LLMs in terms of space and time, by which it can be inferred that the models produce a comprehensive comprehension of these dimensions. The researchers have even recognized particular LLM neurons they describe as ‘space neurons’ and ‘time neurons.’ These neurons accurately express spatial and temporal coordinates, demonstrating the existence of specialized components in the models that process and represent space and time.
In conclusion, the results of this study have reinforced the notion that contemporary LLMs go beyond rote memorizing of statistics and instead learn structured and significant information about important dimensions like space and time. It is definitely possible to say that LLMs are more than just statistical engines and can represent the underlying structure of the data-generating processes they are trained on.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 31k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on WhatsApp. Join our AI Channel on Whatsapp..
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.