A New Paradigm For Editing Machine Learning Models Based on Arithmetic Operations Over Task Vectors
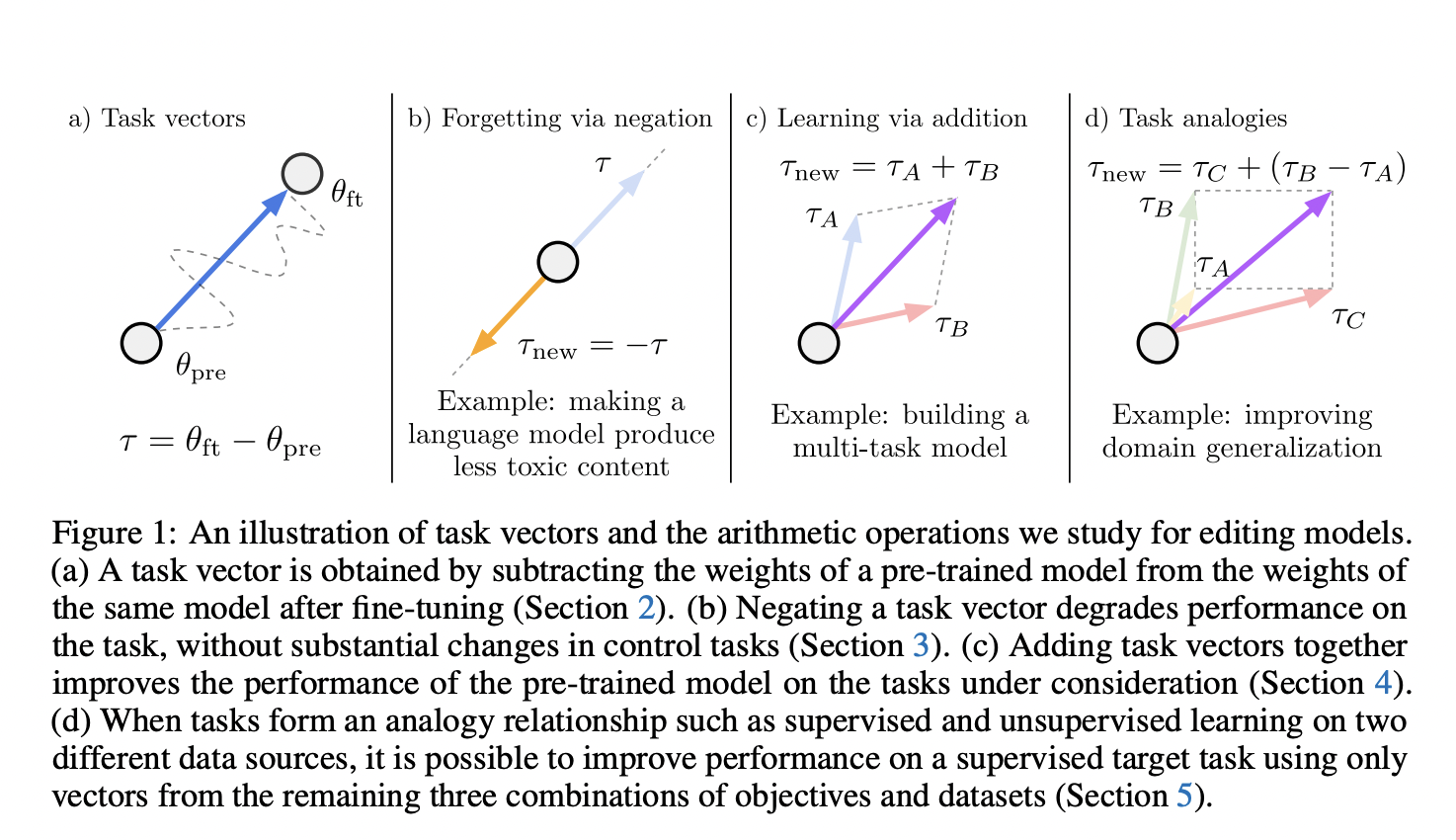
It is becoming increasingly common to use large-scale pre-training to develop models employed as the foundation for more specialized machine learning systems. From a practical point of view, it is often necessary to change and update such models after they have been pre-trained. The objectives for further processing are numerous. For instance, it is critical to enhance the pre-trained model performance on specific tasks, address biases or undesired behavior, align the model with human preferences, or incorporate new information.
The latest work from a team of researchers from the University of Washington, Microsoft Research, and Allen Institute for AI develops a clever method to stir the behavior of pre-trained models based on task vectors, which are obtained by subtracting the pre-trained weights of a model fine-tuned on a task. More precisely, task vectors are defined as the element-wise difference between the weights of pre-trained and fine-tuned models. To this end, task vectors can be applied to any model parameters using element-wise addition and an optional scaling term. In the paper, the scaling terms are determined using held-out validation sets.
The authors demonstrate that users can perform simple arithmetic operations on these task vectors to change models, such as negating the vector to remove undesirable behaviors or unlearn tasks or adding task vectors to improve multi-task models or performance on a single task. They also show that when tasks form an analogy relationship, task vectors can be combined to improve performance on tasks where data is scarce.


The authors show that the conceived approach is reliable in forgetting unwanted behavior both in the vision and text domains. They experiment with original and fine-tuned CLIP models for the vision domain on various datasets (e.g., Cars, EuroSAT, MNIST, etc.). As visible in Table 1 of the paper, the negation of task vectors is a reliable method to decrease the performance on the target task (up to 45.8 percentage points for ViT-L) and leave almost the original accuracy for the control task. For the language domain (Table 2), they show that negative task vectors decrease the number of toxic generations of a GPT-2 Large model by six times while resulting in a model with similar perplexity on a control task (WikiText-103).

The addition of task vectors can also enhance pre-trained models. In the case of image classification, adding task vectors from two tasks improves accuracy on both, resulting in a single model that is competitive with using two specialized fine-tuned models (figure 2). In the language domain (GLUE benchmark), the authors show that adding task vectors to pre-trained T5-base models is better than fine-tuning, even if improvements are more modest in this case.
Finally, performing task analogies with task vectors allow both to improve performance on domain generalization tasks and subpopulations with little data. For instance, to obtain better performance on specific rare images (e.g., lions indoors), one can build a task vector by adding to the lion-outdoor task vector the difference between task vectors of dogs indoors and outdoors. As visible in Figure 4, such modeling allows clear improvements for domains in which few images are available.
To summarize, this work introduced a new approach for editing models by performing arithmetic operations on task vectors. The method is efficient, and users can easily experiment with various model edits by recycling and transferring knowledge from extensive collections of publicly available fine-tuned models.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 13k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Lorenzo Brigato is a Postdoctoral Researcher at the ARTORG center, a research institution affiliated with the University of Bern, and is currently involved in the application of AI to health and nutrition. He holds a Ph.D. degree in Computer Science from the Sapienza University of Rome, Italy. His Ph.D. thesis focused on image classification problems with sample- and label-deficient data distributions.
Credit: Source link
Comments are closed.