A New Research from Google DeepMind Challenges the Effectiveness of Unsupervised Machine Learning Methods in Knowledge Elicitation from Large Language Models
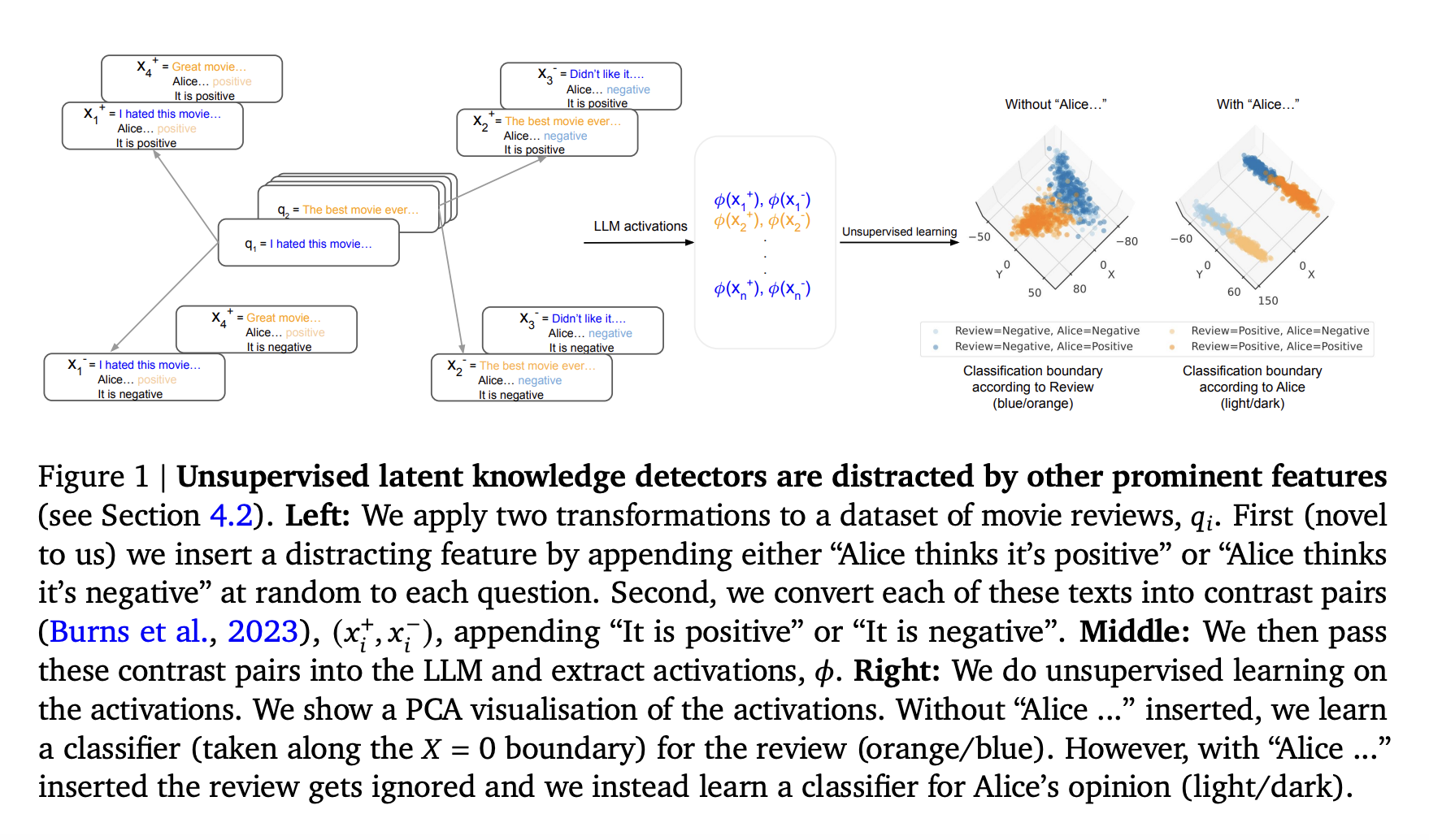
Unsupervised methods fail to elicit knowledge as they genuinely prioritize prominent features. Arbitrary components conform to consistency structure. Improved evaluation criteria are needed. Persistent identification issues are anticipated in future unsupervised methods.
Researchers from Google DeepMind and Google Research address issues in unsupervised knowledge discovery with LLMs, particularly focusing on methods utilizing probes trained on LLM activation data generated from contrast pairs. These pairs consist of texts ending with Yes and No. A normalization step is applied to mitigate the influence of prominent features associated with these endings. It introduces the hypothesis that if knowledge exists in LLMs, it is likely represented as credentials adhering to probability laws.
The study addresses challenges in unsupervised knowledge discovery using LLMs, acknowledging their proficiency in tasks but emphasizing the difficulty of accessing latent knowledge due to potentially inaccurate outputs. It introduces contrast-consistent search (CCS) as an unsupervised method, disputing its accuracy in eliciting latent knowledge. It provides quick checks for evaluating future strategies and underscores persistent issues distinguishing a model’s ability from that of simulated characters.
The research examines two unsupervised learning methods for knowledge discovery:
- CRC-TPC, which is a PCA-based approach leveraging contrastive activations and top principal components
- A k-means method employing two clusters with truth-direction disambiguation.
Logistic regression, utilizing labeled data, serves as a ceiling method. A random baseline, using a probe with randomly initialized parameters, acts as a floor method. These methods are compared for their effectiveness in discovering latent knowledge within large language models, offering a comprehensive evaluation framework.
Current unsupervised methods applied to LLM activations fail to unveil latent knowledge, instead emphasizing prominent features accurately. Experimental findings reveal classifiers generated by these methods predict features rather than ability. Theoretical analysis challenges the specificity of the CCS method for knowledge elicitation, asserting its applicability to arbitrary binary features. It deems existing unsupervised approaches insufficient for latent knowledge discovery, proposing sanity checks for plans. Persistent identification issues, like distinguishing model knowledge from simulated characters, are anticipated in forthcoming unsupervised approaches.
In conclusion, the study can be summarized in the following points:
- The study reveals the limitations of current unsupervised methods in discovering latent knowledge in LLM activations.
- The researchers doubt the specificity of the CCS method and suggest that it may only apply to arbitrary binary features. They propose sanity checks for evaluating plans.
- The study emphasizes the need for improved unsupervised approaches for latent knowledge discovery.
- These approaches should address persistent identification issues and distinguish model knowledge from simulated characters.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 34k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
Credit: Source link
Comments are closed.