A New Study from CMU and Bosch Center for AI Demonstrated a New Transformer Paradigm in Computer Vision

After leveraging Convolutional Neural Network (CNN) for many years, since the advent of Transformers in Natural Language Processing (NLP), the computer vision community has also focused very carefully (and sometimes trying a little too hard) on how to apply Transformers in vision. This stems primarily from the enormous success of ViT, which outperformed CNN’s state-of-the-art when trained with insanely large datasets. The authors of ViT proposed a straightforward adaptation of the original Transformer, as ViT is composed simply of a “patchify” layer, which divides the image into patches treated as tokens, followed by a linear projection and the Transformer encoder module (composed of the Self Attention and the MLP module), which remained unchanged.
The classic research approach has been to focus on different aspects of the original implementation while trying to demonstrate its pros and cons. For example, the authors of MetaFormer substituted an effortless pooling layer to the self-attention one to demonstrate that the actual power of the Transformer could only be the particular configuration of the module (consisting of the self-attention and the subsequent MLP) and not the self-attention itself. Another example can be found in the article “A ConvNet for the 2020s”, where the idea of the authors is that the power of transformers is derived solely from the many methodologies which have been introduced recently, and they managed to obtain the same results of a ViT with an up-to-date ResNet.
The hypothesis of Carnegie Mellon University and Bosch Center for AI is once again different: the superpowers of Transformers comes from the patch-based representation and not from the architecture itself (for this reason, they substituted the original name of the article, “Convolutions Attention MLPs”, with a more accurate “Patches are all you need?”). Following this intuition, they proposed ConvMixer, an architecture inspired by Transformers (it operates directly on patches and does not use downsampling) but based only on convolutions.
The architecture

ConvMixer starts with a patch embedding layer, implemented as a convolution with kernel size and stride both equal to p (to extract patches of size p x p), followed by a GELU activation and a Batch Normalization layer. Then, a series of ConvMixer layers are applied, composed of a depthwise convolution (with an unusually large kernel size, to mix distant space locations) followed by a pointwise convolution (this combination is often called depthwise separable convolutions), with a residual connection in between. The idea behind using these two operations is to mix spatial locations through depthwise convolution and channel location through pointwise convolution. Finally, global average pooling is performed before passing the information to the softmax function for classification.
Results

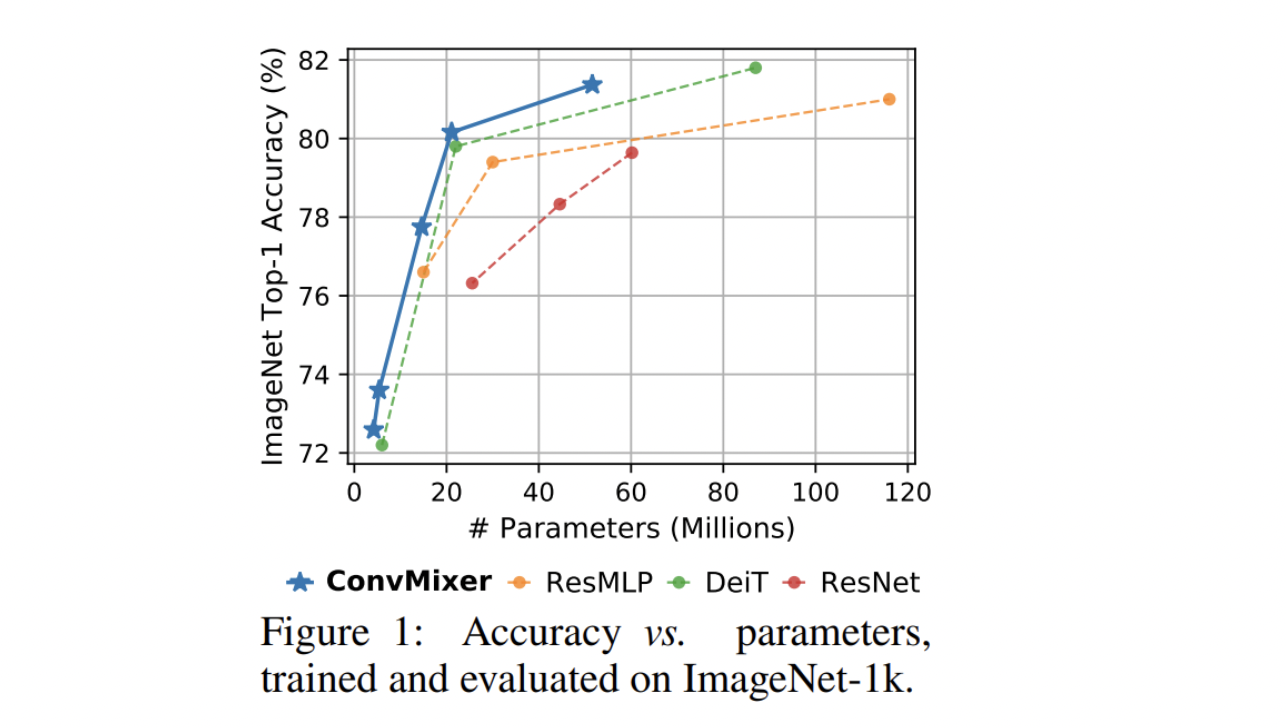
ConvMixer was then trained on ImageNet-1k, and the results in top-1 accuracy were very surprising, with an 81.37% using a kernel size of 9. It is worth saying the authors pointed out that they did not fine-tune the hyperparameters and, for this reason, the accuracy could be even higher. Compared to other architectures (using the same parameter used in ConvMixer), it achieved state-of-the-art results while using fewer parameters.
Conclusion
The key idea of this article is that a very simple architecture can compete with both standard CNN such as ResNet and Transformer-based such as DeiT. Even though this paper was not meant to maximize accuracy nor speed but to demonstrate the importance of the patch extractor, the results in terms of the number of parameters and top-1 accuracy were excellent.
Since its advent, the Transformer architecture has been analyzed very deeply, and several authors have proposed different interpretations of its efficiency. Unfortunately, it is still unclear where this power comes from, and we can’t wait to discover more about its behavior.
Paper: https://arxiv.org/pdf/2201.09792v1.pdf
Github: https://github.com/locuslab/convmixer
Suggested

Credit: Source link
Comments are closed.