A New Technique to Train Diffusion Model in Latent Space Using Limited Computational Resources While Maintaining High-Resolution Quality

In recent years, image synthesis has experienced exponential growth in performance. The two main approaches to this task have been autoregressive transformers (ARs) and generative adversarial networks (GANs). The firsts are trained for sequence prediction and are able to generate images, token by token, starting from the first one. The seconds are based on the famous generator-discriminator method, where the generator tries to fool the discriminator into generating reliable samples. Nevertheless, both approaches have huge limitations: in particular, ARs require billions of parameters to be trained, while GANs rely on the minimax loss which has been demonstrated to often bring to mode collapse and instability in training.
Diffusion models (DMs) have recently shown excellent results in different image synthesis tasks. They are based on two stages: in the first, noise is added to data step by step in a Markov chain modality, meaning that each step depends solely on the previous step. This process is repeated until losing the majority of the information of the original sample. Then, a denoising process is applied, aiming to reconstruct the image from the noisy version.
As they are likelihood-based (as ARs), they do not suffer from the same training instability as GANs; they can also model complex distributions while not needing the number of parameters of ARs. However, one characteristic of likelihood-based models is that they are prone to invest an insane amount of computational resources in modeling tiny details. For example, given the particular behavior of DMs, even at inference time, to produce 50k samples, they need approximately five days on a single A100 GPU.
For this reason, a group of researchers from the Ludwig Maximilian University of Munich and Runway ML proposed Latent Diffusion Model (LDM), a DM that works on a compression level and not in the pixel space, thus saving computational resources and consequently producing higher resolution images compared to the state-of-the-art.
The first step of the work was an analysis of pre-trained models in the pixel space to define two stages of the learning phase: a perceptual compression stage which removes high-frequency details, and a semantic compression stage, where the model learns the composition of the data (image below).
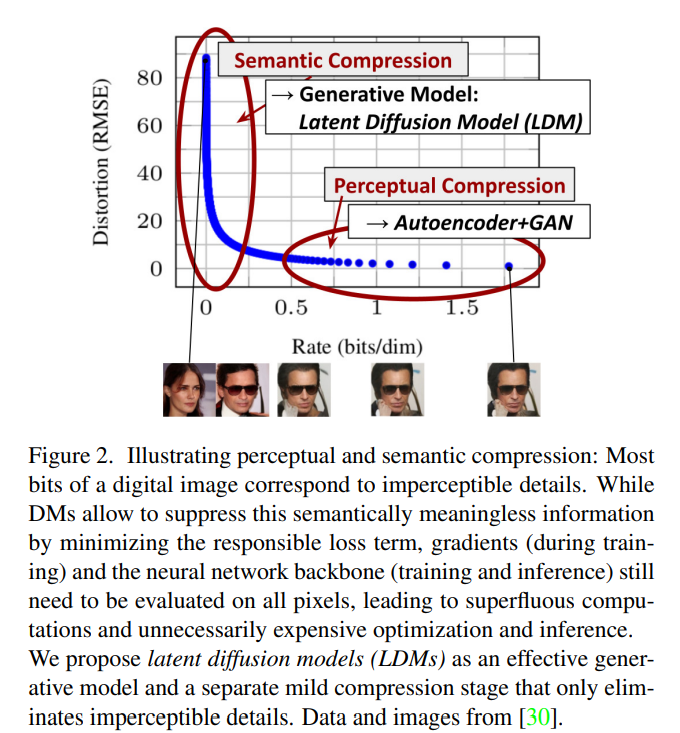
The aim is to find a perceptually equivalent representation of data that needs a minor computational effort. For this reason, they trained an autoencoder that returns a lower-dimensional representation and froze it for subsequent computation to detach the first stage from the DM training. The image below shows the encoder and decoder on the left as E and D.
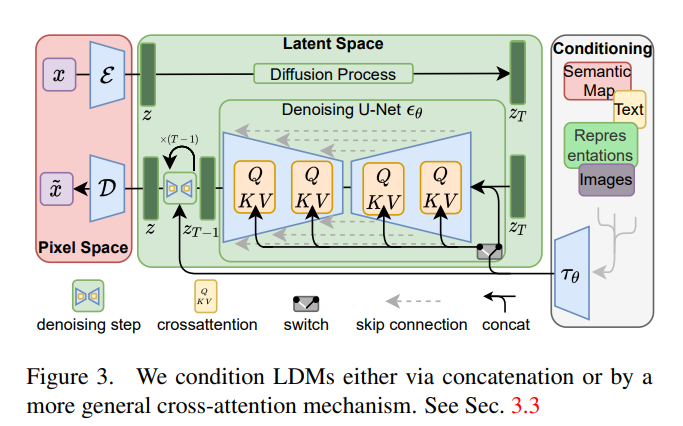
The latent representation then flows through the diffusion process, where noise is added at each step. After this process, the result is given to the denoising network, which in theory can be seen as a sequence of denoising autoencoders trained to predict a denoised variant of their input. This architecture was modeled as a U-Net and was trained not in pixel-space but in the latent representation space.
Moreover, to add some conditioning to the process (you want to be able to produce images conditioned by a text prompt or a segmentation map, for example), U-Net was modified by adding a cross-attention mechanism (an attention mechanism that mixes two different embedding sequences, usually from different modality). The additional information from various modalities (text, map, etc.) is projected to an intermediate representation and mapped to layers of U-Net with these cross-attention layers. The full pipeline is resumed below.
This model achieves new state-of-the-art scores for image inpainting and class-conditional image synthesis and highly competitive performance on various tasks, including text-to-image synthesis, unconditional image generation, and super-resolution, while significantly reducing computational requirements compared to pixel-based DMs.
This Article is written as a paper summary article by Marktechpost Research Staff based on the paper 'High-Resolution Image Synthesis with Latent Diffusion Models'. All Credit For This Research Goes To Researchers on This Project. Checkout the paper and github. Please Don't Forget To Join Our ML Subreddit
Some examples of applications are shown below (layout-to-image synthesis, semantic conditioning, and object removal).
Credit: Source link
Comments are closed.