A New Transformer Based Reinforcement Learning Agent Called ‘AdA’ Inhabits a Rich 3D World and Can Rapidly Adapt to Tasks It Has Never Seen Before in Minutes
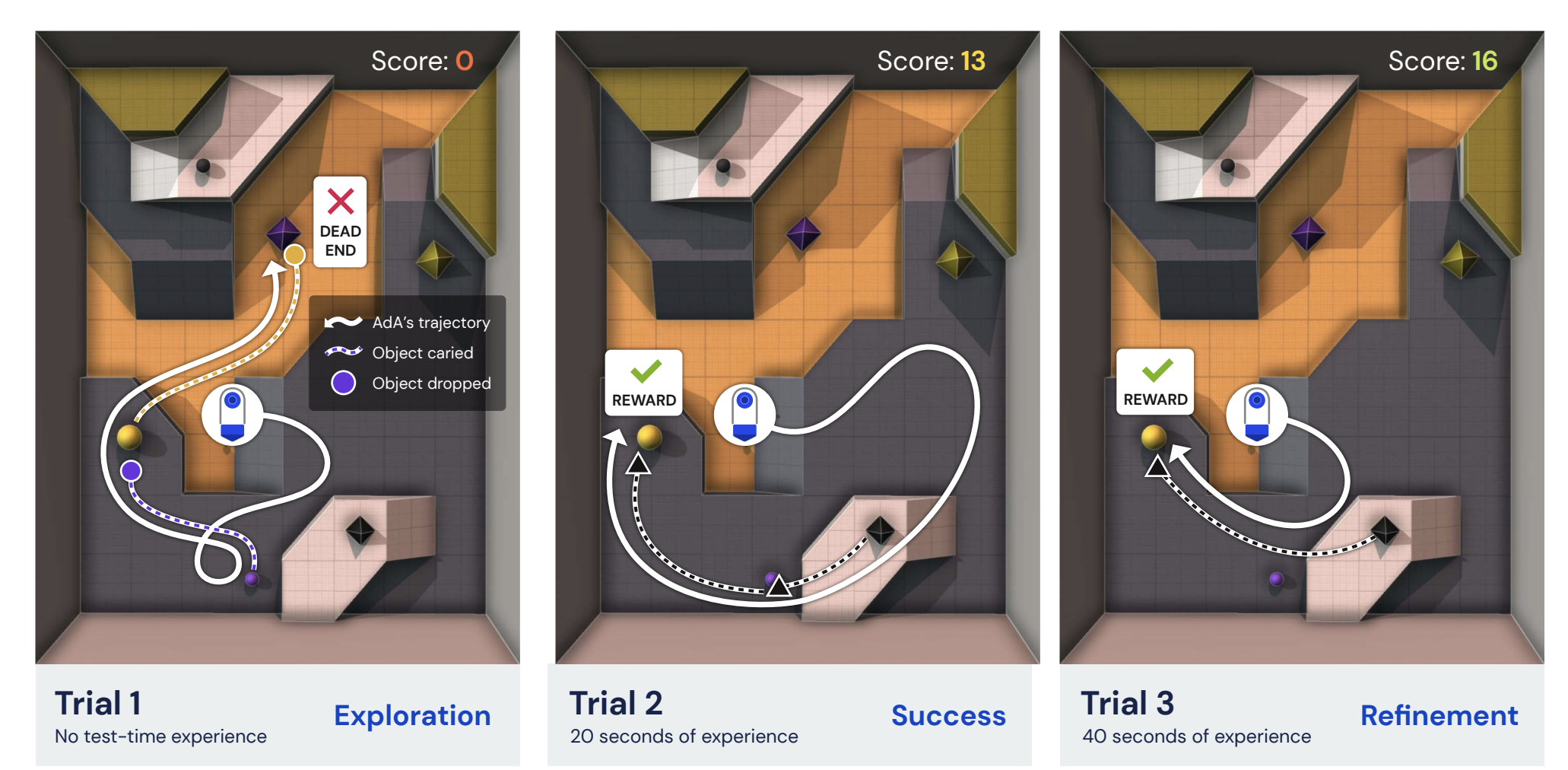
It has always been astounding how quickly humans can adjust to their environment. Artificial intelligence agents have been developed over many years to replicate this human intelligence in quick and flexible adaptability in only a few interactions. Additionally, it is believed that when more data becomes available, this capability to adjust to one’s surroundings quickly should only grow. With this objective in mind, DeepMind, a subsidiary of Alphabet, set out to train an agent capable of performing exploratory tasks given only a few episodes in an unknown environment and then improving its response in the direction of optimal behavior.
Meta-RL aims to design agents with human-level adaptability that get better with experience. For quick in-context adaptation, Meta-RL has proven to be quite effective. However, the technique has not been as successful in environments with few rewards and large, varied task spaces. The capacity of foundation models to adjust in a few shots from demonstrations over a wide range of jobs has attracted substantial interest outside of RL. Foundation models are those models that have been pre-trained with extremely large datasets spanning a wide variety of tasks. These large neural networks can be trained once and then tailored to carry out different kinds of tasks.
By combining the abilities of RL and foundation models to accomplish human timescale adaptation across a vast and varied task space, DeepMind recently suggested a scalable method for memory-based meta-RL, thus, creating Adaptive Agent (AdA). AdA engages in hypothesis-driven exploratory behavior and uses information gained on the go to modify its strategy to reach a nearly ideal performance. AdA’s uniqueness also stems from the fact that it doesn’t need offline datasets, prompts, or fine-tuning. Even a human study confirmed that AdA’s adaption time is on par with that of skilled human gamers. Similar to foundation models in the language domain, AdA can likewise boost performance by zero-shot prompting with first-person demonstrations.
Transformers were the underlying architecture of choice for the AdA research team in order to achieve in-context fast adaptation using model-based RL. The researchers decided to extend the XLand environment (XLand 2.0) because foundation models often require vast and diverse datasets to attain their generality. A mechanism known as production rules is an addition to XLand 1.0. Compared to XLand 1.0, each production rule represents an additional environment dynamic, resulting in a significantly richer and more varied set of transition functions.
AdA was trained and tested on the XLand 2.0 environment, which resulted in a massive, open-ended universe with millions of potential tasks. These tasks call for various online adaptation skills, such as coordination, experimentation, and navigation. Due to the diverse spectrum of potential tasks, the researchers decided to adopt Prioritized Level Replay, a regret-based approach that prioritizes tasks at the frontier of an agent’s capabilities. Finally, distillation allowed scaling to models with over 500M parameters! In a nutshell, the three primary parts of DeepMind’s training methodology include a curriculum to direct the agent’s learning, a model-based RL algorithm to train agents with large-scale attention-based memory, and distillation to permit scaling.
Through a series of experimental evaluations conducted by the researchers, it was concluded that AdA achieves human timescale performance. Additionally, several elements, including the underlying architecture and the choice to use auto-curriculum learning, substantially impact performance. Additionally, the team noticed advantages from scaling aspects, including the number of parameters, the size and complexity of the training challenges, and the memory length. It is safe to state that AdA can adapt to various difficult tasks in a short time, including combining objects in innovative ways, navigating uncharted territory, and even displaying emergent teamwork with partners in coordination-demanding activities. The research team is extremely excited about what the future holds when it comes to exploring the potential for scaling open-ended learning and foundation models for training increasingly general agents.
Check out the Paper and Project. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our Reddit Page, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Khushboo Gupta is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Goa. She is passionate about the fields of Machine Learning, Natural Language Processing and Web Development. She enjoys learning more about the technical field by participating in several challenges.
Credit: Source link
Comments are closed.