A novel family of auxiliary tasks based on the successor measure to improve the representations that deep reinforcement learning agents acquire
In deep reinforcement learning, an agent uses a neural network to map observations to a policy or return prediction. This network’s function is to turn observations into a sequence of progressively finer characteristics, which the final layer then linearly combines to get the desired prediction. The agent’s representation of its current state is how most people view this change and the intermediate characteristics it creates. According to this perspective, the learning agent carries out two tasks: representation learning, which involves finding valuable state characteristics, and credit assignment, which entails translating these features into precise predictions.
Modern RL methods typically incorporate machinery that incentivizes learning good state representations, such as predicting immediate rewards, future states, or observations, encoding a similarity metric, and data augmentation. End-to-end RL has been shown to obtain good performance in a wide variety of problems. It is frequently feasible and desirable to acquire a sufficiently rich representation before performing credit assignment; representation learning has been a core component of RL since its inception. Using the network to forecast additional tasks related to each state is an efficient way to learn state representations.
A collection of properties corresponding to the primary components of the auxiliary task matrix may be demonstrated as being induced by additional tasks in an idealized environment. Thus, the learned representation’s theoretical approximation error, generalization, and stability may be examined. It may come as a surprise to learn how little is known about their conduct in larger-scale surroundings. It is still determined how employing more tasks or expanding the network’s capacity would affect the scaling features of representation learning from auxiliary activities. This essay seeks to close that information gap. They use a family of additional incentives that may be sampled as a starting point for their strategy.
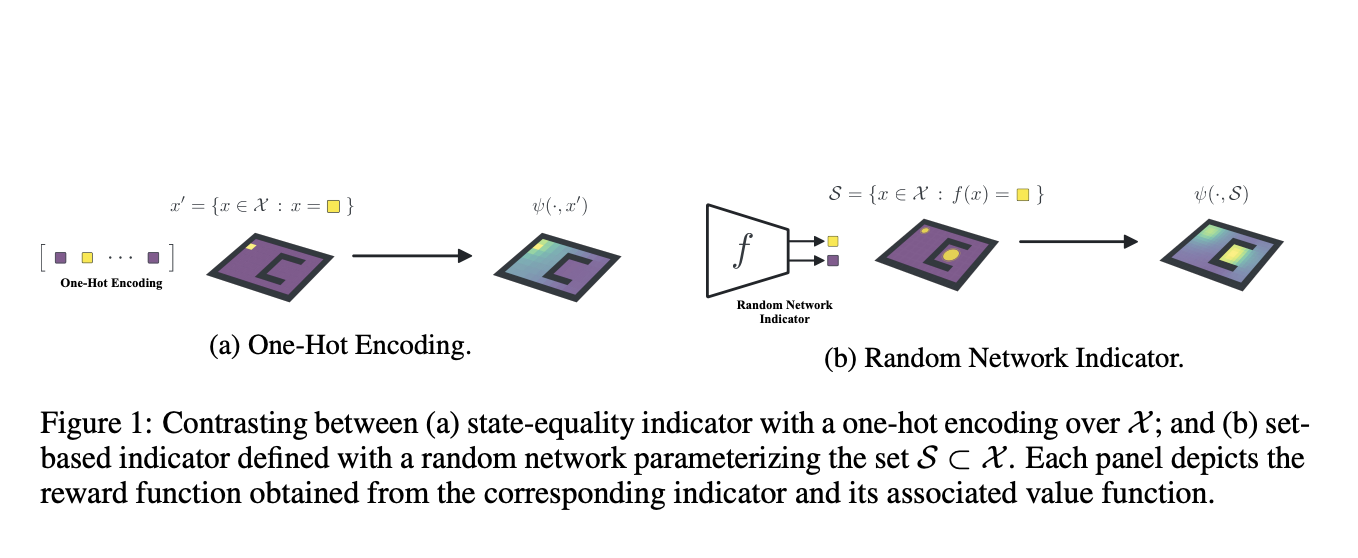
Researchers from McGill University, Université de Montréal, Québec AI Institute, University of Oxford and Google Research specifically apply the successor measure, which expands the successor representation by substituting set inclusion for state equality. In this situation, a family of binary functions over states serves as an implicit definition for these sets. Most of their research is focused on binary operations obtained from randomly initialized networks, which have already been shown to be useful as random cumulants. Despite the possibility that their findings would also apply to other auxiliary rewards, their approach has several advantages:
- It can be easily scaled up using additional random network samples as extra tasks.
- It is directly related to the binary reward functions found in deep RL benchmarks.
- It is partially understandable.
Predicting the predicted return of the random policy for the relevant auxiliary incentives is the real additional task; in the tabular environment, this corresponds to proto-value functions. They refer to their approach as proto-value networks as a result. They research how well this approach works in the arcade learning environment. When utilized with linear function approximation, they examine the characteristics learned by PVN and demonstrate how well they represent the temporal structure of the environment. Overall, they discover that PVN only needs a small portion of interactions with the environment reward function to yield state characteristics rich enough to support linear value estimates equivalent to those of DQN on various games.
They discovered in ablation research that expanding the value network’s capacity significantly enhances the performance of their linear agents and that larger networks can handle more jobs. They also discover, somewhat unexpectedly, that their strategy works best with what may appear to be a modest number of additional tasks: the smallest networks they analyze create their best representations from 10 or fewer tasks, and the biggest, from 50 to 100 tasks. They conclude that specific tasks may result in representations that are far richer than anticipated and that the impact of any given job on fixed-size networks still needs to be fully understood.
Check out the Paper. Don’t forget to join our 21k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.