A Recent AI Research Proposes IDE-3D: An Interactive Disentangled Editing Framework for High-Resolution 3D-aware Portrait Synthesis
Portrait synthesis has become a rapidly growing field of computer graphics in recent years. If you are wondering what portrait synthesis means, it is an Artificial Intelligence (AI) task involving an image generator. This generator is trained to produce photorealistic facial images that can be manipulated in several ways, such as haircut, clothing, poses, and pupil color. With the advancements in deep learning and computer vision, it is now possible to generate photorealistic 3D faces that can be used in various applications such as virtual reality, video games, and movies. Despite these advancements, existing methods still face challenges in balancing the trade-off between the quality and editability of the generated portraits. Some methods produce low-resolution but editable faces, while others generate high-quality but uneditable faces.
Existing methods using StyleGAN aim to provide editing capabilities by either learning attribute-specific directions in the latent space or by incorporating various priors to create a more controlled and separated latent space. These techniques are successful in generating 2D images, but they struggle to maintain consistency in different views when applied to 3D face editing.
Other methods focus on neural representations to construct 3D-aware Generative Adversarial Networks (GANs). Initially, NeRF-based generators were developed to generate portraits with consistency across different views by utilizing volumetric representation. However, this approach is memory-inefficient and has limitations in the resolution and authenticity of the synthesized images. The 3D-aware generative model presented in this article has been developed to overcome these issues.
👉 Read our latest Newsletter: Google AI Open-Sources Flan-T5; Can You Label Less by Using Out-of-Domain Data?; Reddit users Jailbroke ChatGPT; Salesforce AI Research Introduces BLIP-2….
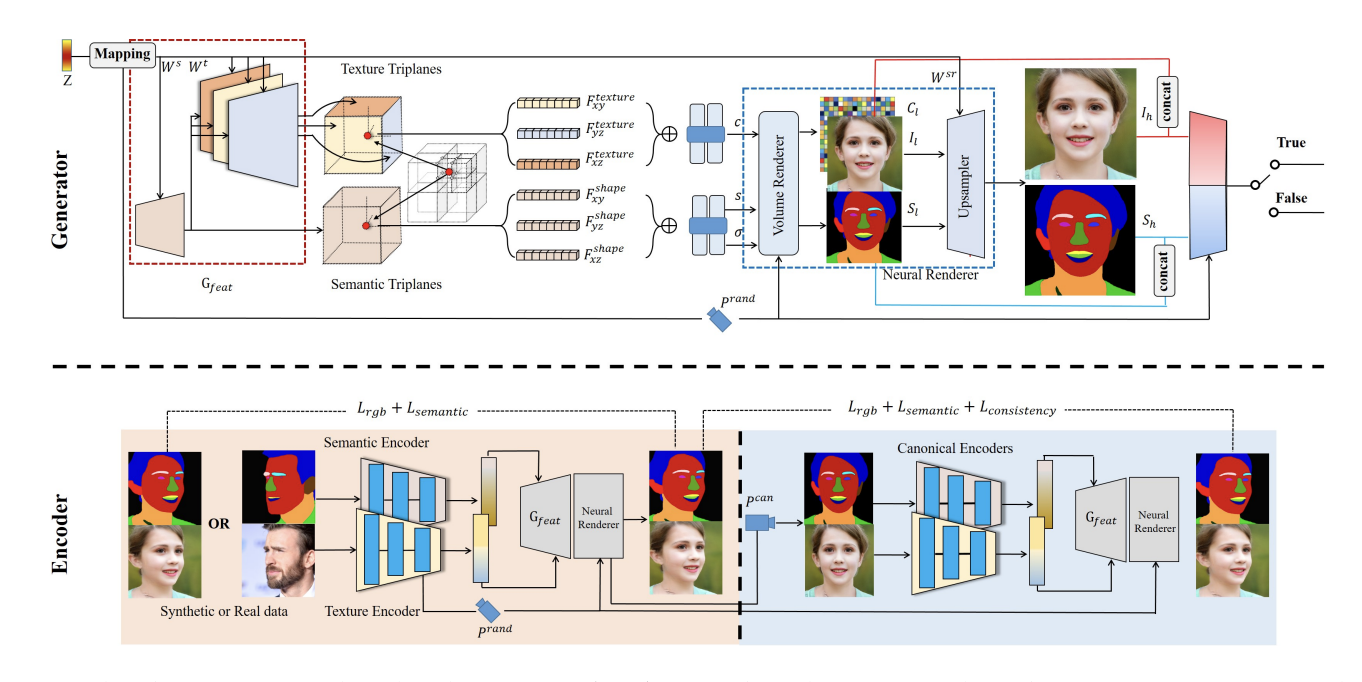
The framework is termed IDE-3D and comprises a multi-head StyleGAN2 feature generator, a neural volume renderer, and a 2D CNN-based up-sampler. An overview of the architecture is presented below.
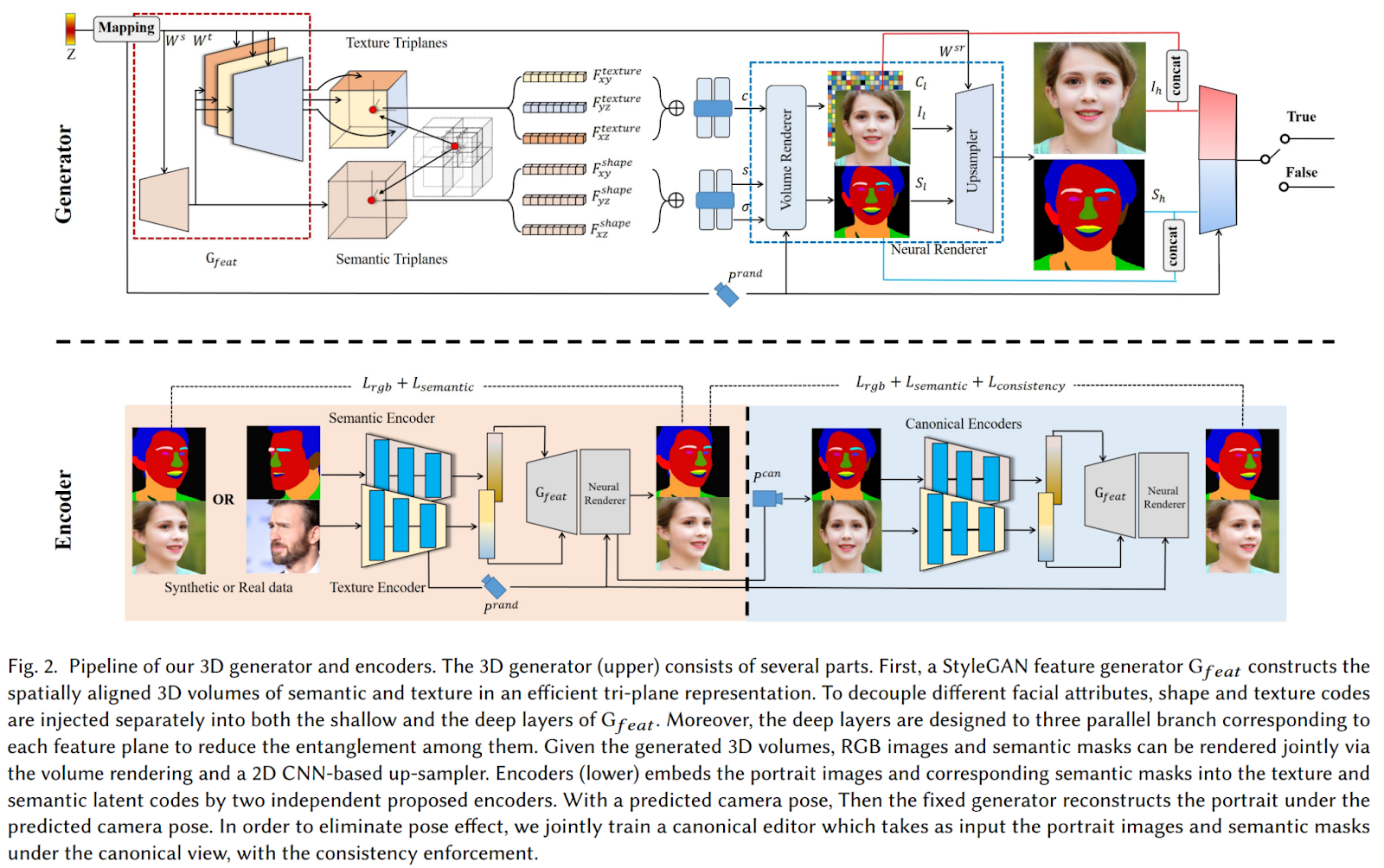
The shape and texture codes are independently fed to both shallow and deep layers of the StyleGAN feature generator to separate different facial attributes. The resulting features are used to construct 3D volumes of shape and texture, which are encoded in facial semantics and represented in an efficient tri-plane representation. These volumes can then be rendered into photorealistic, view-consistent portraits with free-view capability through the volume renderer and the 2D CNN-based up-sampler.
The authors propose a hybrid GAN inversion approach for face editing applications, which involves mapping the input image and semantic mask to the latent space and editing the encoded face. The method uses a combination of optimization-based GAN inversion and texture and semantic encoders to obtain latent codes, which are used for high-fidelity reconstruction. However, the latent output code of the encoders cannot accurately reconstruct the input images and semantic masks. To address this limitation, the authors introduce a “canonical editor” that normalizes the input image to a standard view and maps it into the latent space for real-time editing without sacrificing faithfulness.
According to the authors, the proposed approach results in a locally disentangled, semantics-aware 3D face generator, which supports interactive 3D face synthesis and editing with state-of-the-art performance (in photorealism and efficiency). The figure below offers a comparison between the proposed framework and state-of-the-art approaches.

This was the summary of IDE-3D, a novel and efficient framework for photorealistic and high-resolution 3D portrait synthesis.
If you are interested or want to learn more about this framework, you can find a link to the paper and the project page.
Check out the Paper, Code, and Project Page. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 13k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Daniele Lorenzi received his M.Sc. in ICT for Internet and Multimedia Engineering in 2021 from the University of Padua, Italy. He is a Ph.D. candidate at the Institute of Information Technology (ITEC) at the Alpen-Adria-Universität (AAU) Klagenfurt. He is currently working in the Christian Doppler Laboratory ATHENA and his research interests include adaptive video streaming, immersive media, machine learning, and QoS/QoE evaluation.
Credit: Source link
Comments are closed.