A Recent Research From Harvard and Keio University Researchers Present A New Link Between Dopamine-Based Reward Learning And Machine Learning
A recent research article found a relationship between dopaminergic activity and the TD(temporal difference) learning algorithm, giving basic insights into how the brain links signals and rewards separated in time.”
Dopamine is a common neurotransmitter, and the word “dopaminergic” implies “connected to dopamine” (literally, “acting on dopamine”). The brain’s dopamine-related activity is increased by dopaminergic drugs or behaviors. Dopamine-related action is facilitated by dopaminergic brain circuits.
Research in neuroscience and psychology has consistently shown how essential incentives are in helping people and other animals learn habits that will help them survive. It is well recognized that dopaminergic neurons, neurons in the mammalian central nervous system that release dopamine, are primarily in charge of reward-based learning in mammals. When a mammal receives an unexpected reward, these neurons quickly react through a process known as phasic excitement.
To develop effective machine learning models that can handle challenging tasks, computer scientists have recently started attempting to artificially reproduce the neurological foundations of reward learning in mammals. The so-called temporal difference (TD) learning algorithm is a well-known machine learning technique that mimics the operation of dopaminergic neurons.
The researcher explored a potential connection between the computational TD learning approach and incentives-based human learning. Their study, released in the journal Nature Neuroscience, may provide fresh insight into how the brain creates links between stimuli and rewards spaced out in time.
A family of reinforcement learning techniques known as “TD learning algorithms” can learn to generate predictions based on environmental changes over time rather than using a model. TD approaches can modify their estimations more than other machine learning techniques before revealing their final forecast.
The parallels between TD learning algorithms and reward-learning dopamine neurons in the brain have recently come to light in several research. However, one specific component of the algorithm’s operation has only sometimes been considered in neuroscience studies.
The timing of dopamine signals should gradually shift backward from the time of the reward to the time of the cue over several trials when an agent associates a cue and reward that are separated in time, according to previous studies that failed to observe this algorithm’s key prediction.
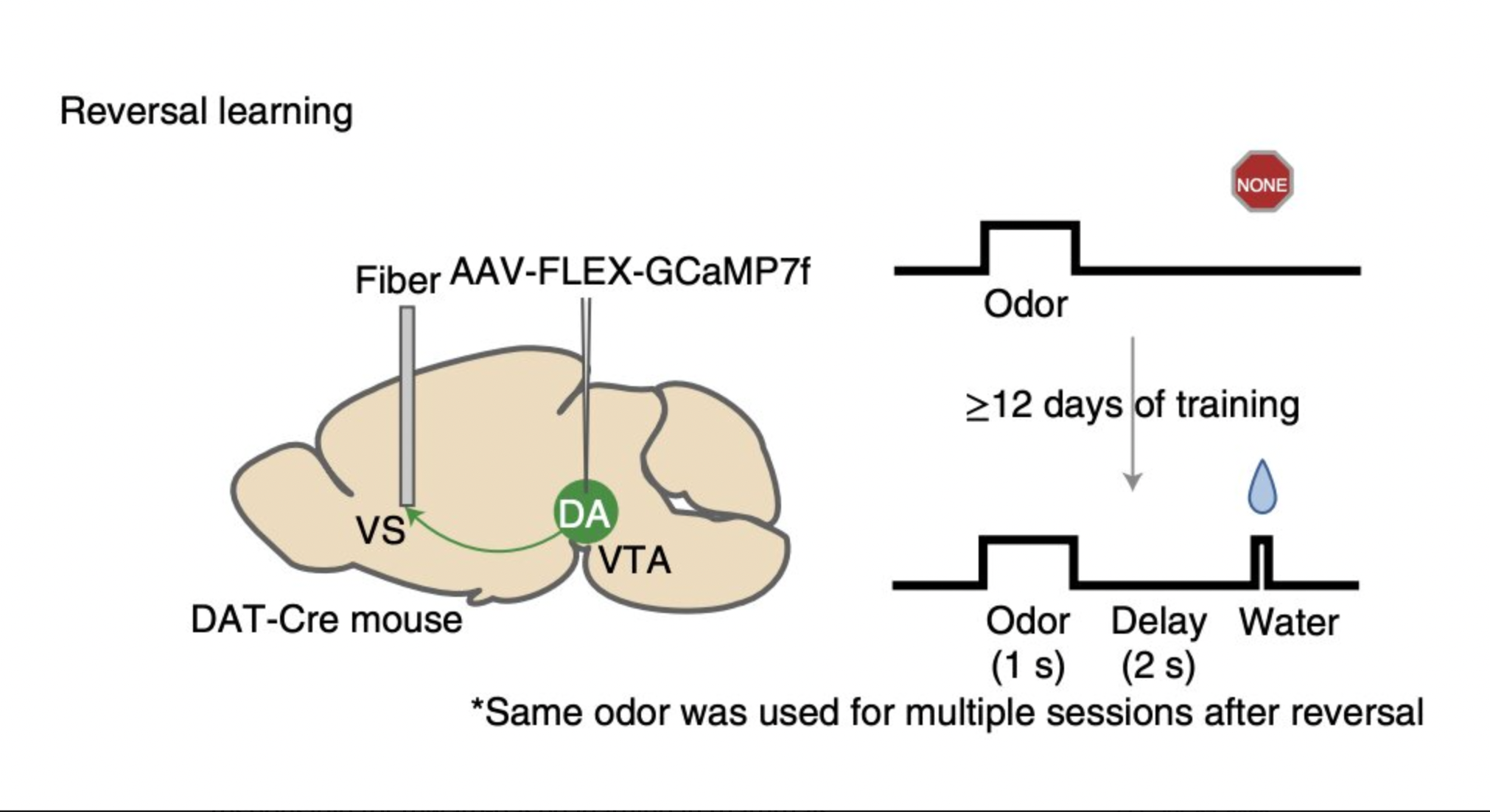
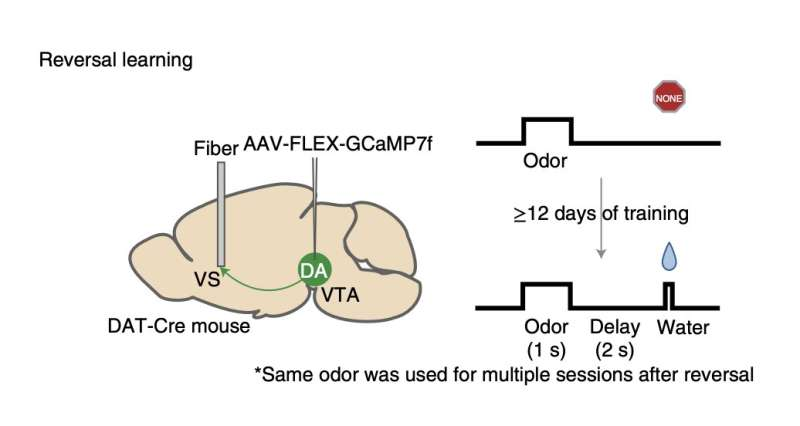
The researcher examined their studies’ findings on untrained mice developing the ability to link olfactory cues with water rewards in their publication. The rats showed licking activity that suggested they anticipated obtaining water after they had only scented the relevant odor when they first started connecting particular fragrances with receiving it.
The mice were exposed to the pre-reward odor and the reward at different times during the studies. To put it another way, they altered the interval between the mice’s exposure to the odor and their receipt of the water reward.
They discovered that dopamine neurons were initially less active when the reward was delayed but eventually became more active. This demonstrated that the timing of dopamine responses in the brain may change as mice learn connections between scents and rewards for the first time, as shown in TD learning techniques.
The scientists conducted further studies to determine if this change also happened in rats that had already been trained to generate similar odor-reward linkages during reversal tasks. During the waiting phase, they saw a temporal change in the animal’s dopamine signals comparable to when animals were learning connections for the first time but occurred more quickly.
Overall, the data show that several associative learning tests resulted in a backward shift in the timing of dopamine activity in the mouse brain. This temporal shift discovered is very similar to the mechanics behind TD learning techniques.
Future studies on the possible parallels between reward learning in the mammalian brain and TD reinforcement learning strategies may be aided by the information obtained by this team of scientists. This could contribute to advancing our understanding of how the brain learns rewards and may also serve as motivation for new TD learning algorithms.
This Article is written as a summary article by Marktechpost Staff based on the research paper 'A gradual temporal shift of dopamine responses mirrors the progression of temporal difference error in machine learning'. All Credit For This Research Goes To Researchers on This Project. Checkout the paper and reference article. Please Don't Forget To Join Our ML Subreddit
![]()
I am consulting intern at MarktechPost. I am majoring in Mechanical Engineering at IIT Kanpur. My interest lies in the field of machining and Robotics. Besides, I have a keen interest in AI, ML, DL, and related areas. I am a tech enthusiast and passionate about new technologies and their real-life uses.
Credit: Source link
Comments are closed.