A Research Group from Stanford Studied the Possible Fine-Tuning Techniques to Generalize Latent Diffusion Models for Medical Imaging Domains
Latent diffusion models have greatly increased in popularity in recent years. Because their outstanding generating capabilities, these models can produce high-fidelity synthetic datasets that can be added to supervised machine learning pipelines in situations when training data is scarce, like medical imaging. Moreover, such medical imaging datasets often need to be annotated by skilled medical professionals who are able to decipher small but semantically significant image aspects. Latent diffusion models may be able to give an easy method for producing synthetic medical imaging data by eliciting pertinent medical keywords or concepts of interest.
A Stanford research team investigated the representational limits of large vision-language foundation models and evaluated how to use pre-trained foundational models to represent medical imaging studies and concepts. More particularly, they investigated the Stable Diffusion model’s representational capability to assess the effectiveness of both its language and vision encoders.
Chest X-rays (CXRs), the most popular imaging technique worldwide, were used by the authors. These CXRs came from two publicly accessible databases, CheXpert and MIMIC-CXR. 1000 frontal radiographs with their corresponding reports were randomly selected from each dataset.
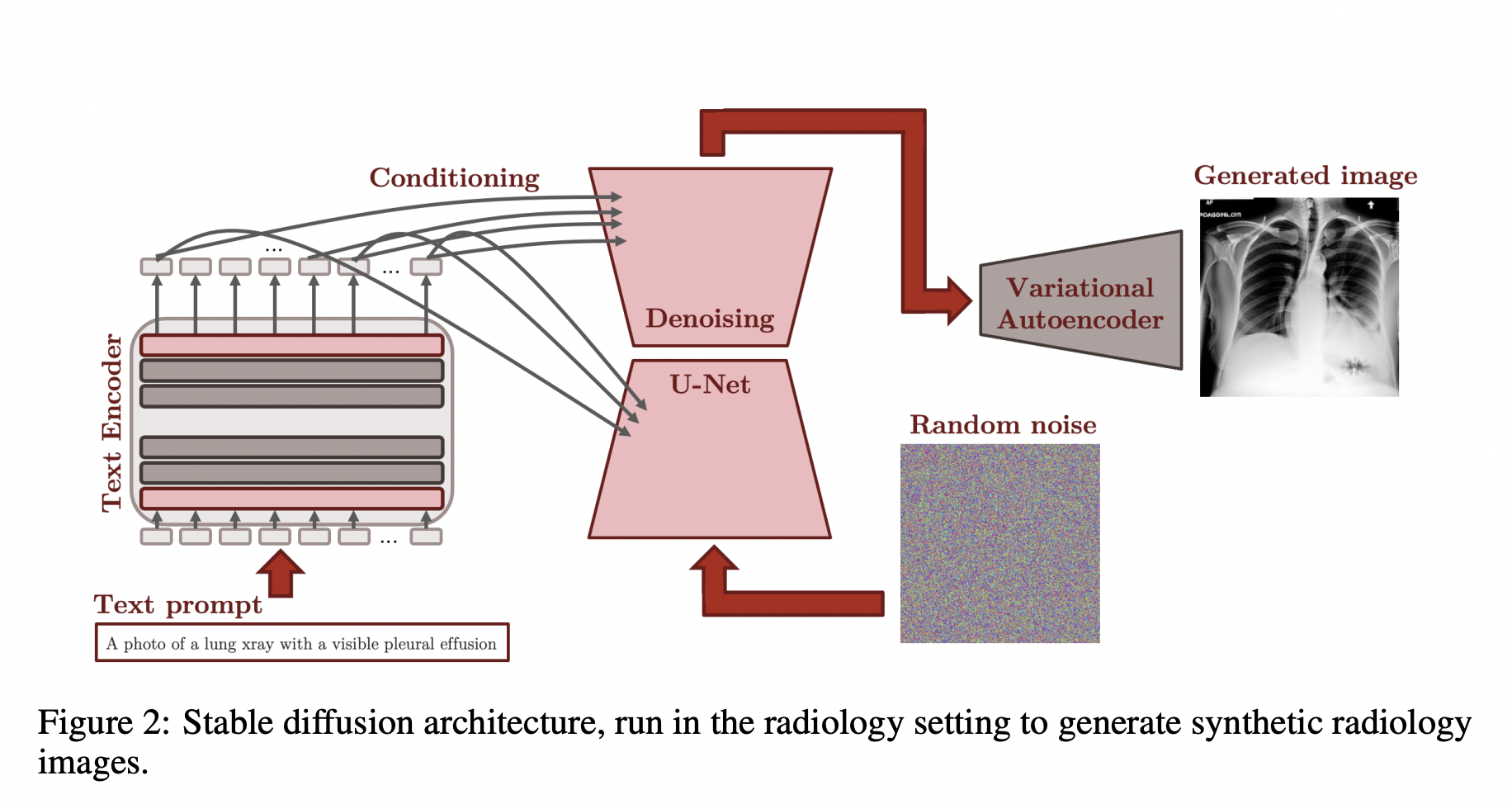
A CLIP text encoder is included with the Stable Diffusion pipeline (figure above) and parses text prompts to produce a 768-dimensional latent representation. This representation is then used to condition a denoising U-Net to produce images in the latent image space using random noise as initialization. Eventually, this latent representation is mapped to the pixel space via a variational autoencoder’s decoder component.
The authors first investigated whether the text encoder alone is capable of projecting clinical prompts to the text latent space while maintaining clinically significant information (1) and whether the VAE alone is capable of reconstructing radiology images without losing clinically significant features (2). Lastly, they proposed three techniques for fine-tuning the stable diffusion model in the radiology domain (3).
1.VAE
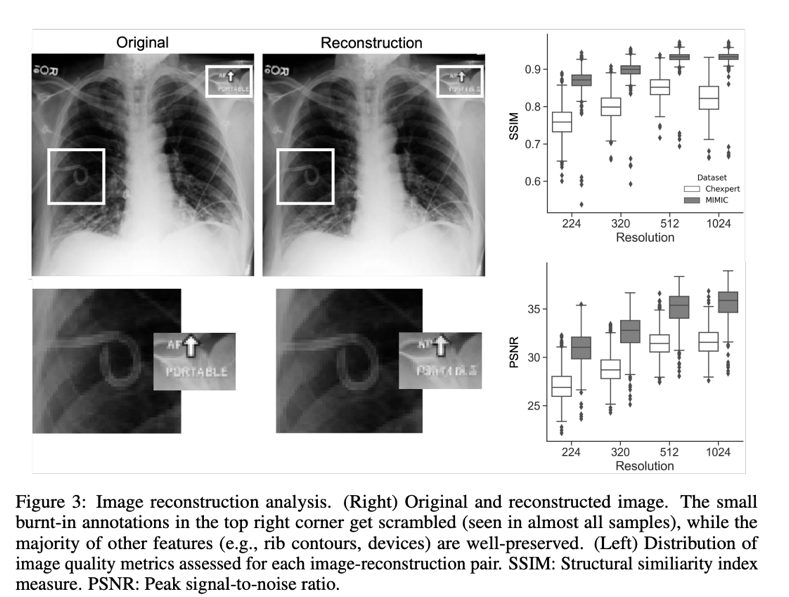
Stable Diffusion, a latent diffusion model, uses an encoder trained to exclude high-frequency details that reflect perceptually insignificant characteristics to transform picture inputs into a latent space before completing the generative denoising process. CXR pictures sampled from CheXpert or MIMIC (“originals”) were encoded to latent representations and rebuilt into images (“reconstructions”) to examine how well medical imaging information is preserved while passing thorugh the VAE. The root-mean-square error (RMSE) and other metrics, such as the Fréchet inception distance (FID), were calculated to objectively measure the reconstruction’s quality, while a senior radiologist with seven years of expertise evaluated it qualitatively. A model that had been pretrained to recognize 18 distinct diseases was used to investigate how the reconstruction procedure affected classification performance. The image below is a reconstruction example.
2.Text Encoder
The objective of this project is to be able to condition the generation of images on linked medical problems that can be communicated through a text prompt in the context-specific setting of radiology reports and images (e.g., in the form of a report). Since the rest of the Stable Diffusion process depends on the text encoder’s capacity to accurately represent medical features in the latent space, the authors investigated this issue using a technique based on previously published pre-trained language models in the area.
3.Fine-tuning
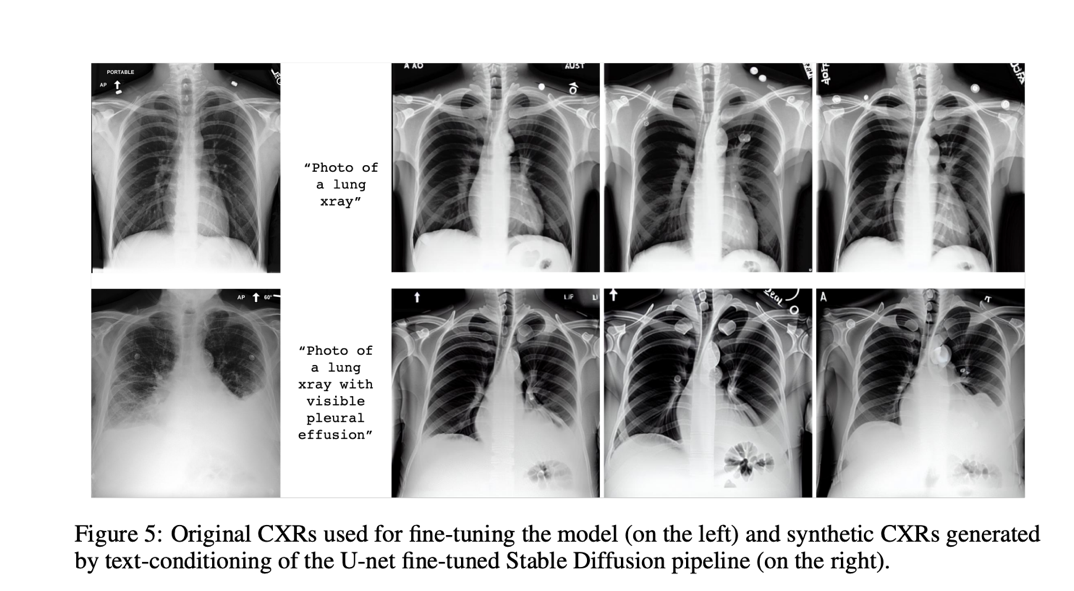
To create domain-specific visuals, various strategies were tried. In the first experiment, the authors swapped out the CLIP text encoder—which had been kept frozen throughout the initial Stable Diffusion training—for a text encoder that had already been pre-trained on data from the biomedical or radiology fields. In the second, the text encoder embeddings were the primary emphasis while the Stable Diffusion model was adjusted. In this situation, a new token is introduced that can be used to define features at the patient, procedure, or anomaly levels. The third one uses domain-specific images to fine-tune all components besides the U-net. After possible fine-tuning by one of the scenarios, the different generative models were put to the test with two straightforward prompts: “A photo of a lung x-ray” and “A snapshot of a lung x-ray with a noticeable pleural effusion.” The models produced synthetic images only based on this text-conditioning. The U-Net fine-tuning method stands out among the others as the most promising because it achieves the lowest FID-scores and, unsurprisingly, produces the most realistic results, proving that such generative models are capable of learning radiology concepts and can be used to insert realistic-looking abnormalities.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 17k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Leonardo Tanzi is currently a Ph.D. Student at the Polytechnic University of Turin, Italy. His current research focuses on human-machine methodologies for smart support during complex interventions in the medical domain, using Deep Learning and Augmented Reality for 3D assistance.
Credit: Source link
Comments are closed.