According To This New AI Research At MIT, Machine Learning Models Trained On Synthetic Data Can Outperform Models Trained On Real Data In Some Cases, Which Could Eliminate Some Privacy, Copyright, And Ethical Concerns
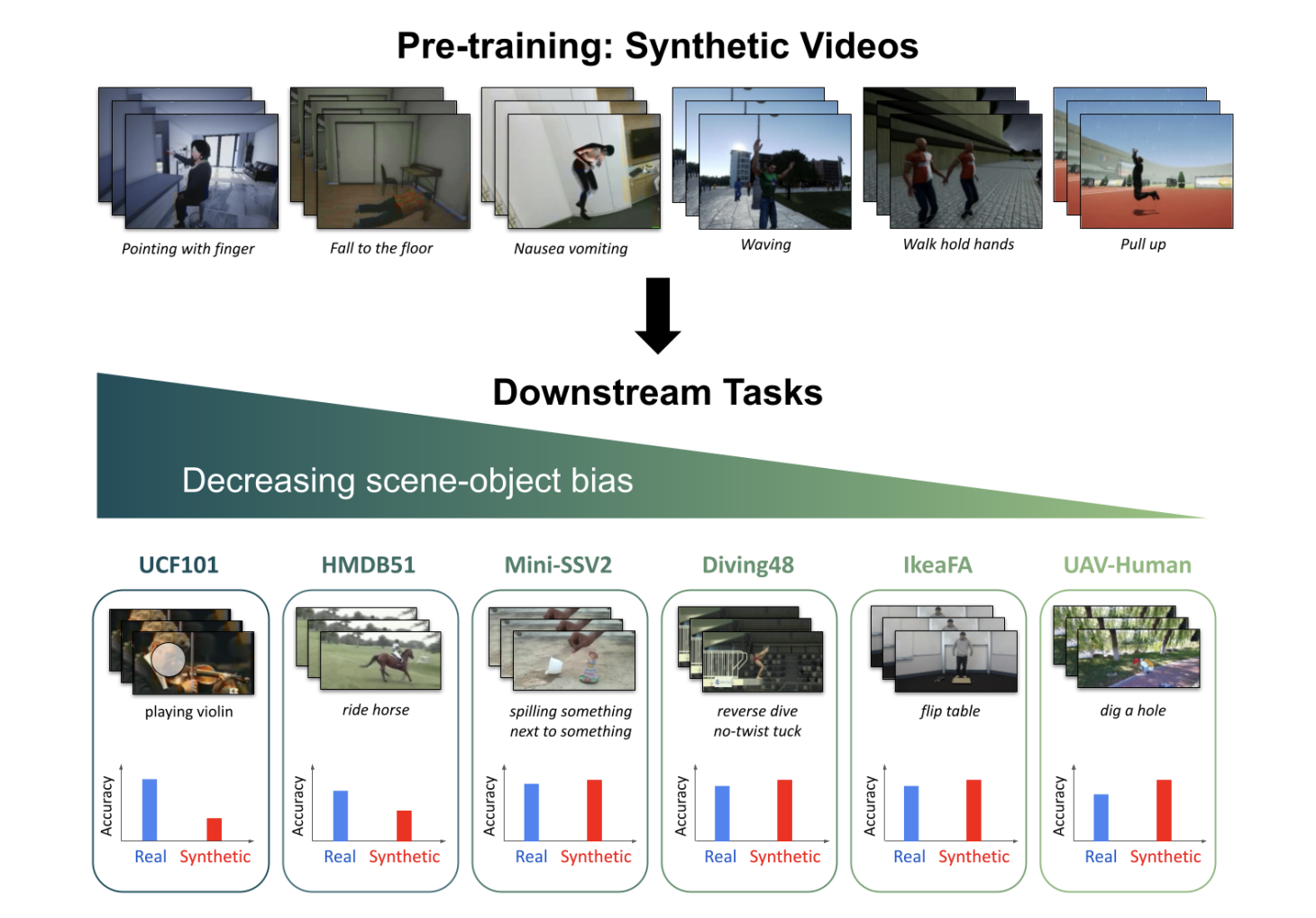
Action recognition, or teaching a machine to recognize human actions, has a wide range of potential applications. For example, it may be used to automatically detect workers who trip and fall on a construction site or teach a smart home robot to understand a user’s gestures. To do this, massive video databases, including footage of people acting naturally, are used to train machine-learning models. However, gathering and labeling millions or billions of movies is costly and time-consuming. The clips sometimes include private data like license plate numbers or the faces of real individuals. Additionally, using these videos can be against copyright and privacy laws. Furthermore, given that many datasets are held by businesses and are not available for free use, researchers must explain why such video data is publicly accessible in the first place.
Therefore, scientists are using synthetic datasets. These are created by a computer using 3D models of real-world environments, objects, and people to swiftly produce a wide range of footage of particular behaviors without the potential for copyright violations or moral ambiguities that come with using real data. Only modest attempts have been made to investigate the potential of synthetic video data compared to real-world datasets. However, certain concerns exist regarding the performance of models trained on synthetic data instead of real data.
A group of researchers from MIT, the MIT-IBM Watson AI Lab, and Boston University created a synthetic dataset of 150,000 video clips that recorded a variety of human actions in order to respond to such inquiries. In order to train machine learning models, this dataset was used. The researchers then tested their model’s capacity to learn to distinguish actions in real-world videos using six different datasets of videos. For videos with fewer background objects, the researchers discovered that the synthetically taught models outperformed those trained on real data. The research will also be presented at the Neural Information Processing Systems Conference.
The primary goal of the research is to substitute synthetic data pre-training for real data pre-training. The researchers stress that although making an action in synthetic data has a cost, once it has been done, anyone may produce an infinite number of photographs or films by altering the attitude, the lighting, etc.
The researchers began by assembling three publicly available datasets of artificial video clips that captured human actions to develop the synthetic dataset. The 150 action categories in their dataset, dubbed Synthetic Action Pre-training and Transfer (SynAPT), each featured 1,000 videos. They used the dataset to pretrain three machine-learning models to recognize the acts after they were created. The pretrained model uses the previously discovered parameters to learn a new task with a new dataset more quickly and successfully. In this step, a model was trained for a single task to give it a head start on learning further tasks by applying prior knowledge.
The researchers were shocked to find that all three synthetic models beat models trained with real video clips on four of the six real-world datasets when they tested the pretrained models using those datasets. The datasets comprised of videos with “low scene-object bias” (video clips in which the model cannot recognize the action by looking at the background or other objects in the scene but must instead concentrate on the action itself) had the most remarkable accuracy rates.
The researchers intend to expand on these findings in future work by incorporating more action classes and more synthetic video platforms. They ultimately hope to achieve a portfolio of models that have been pretrained using synthetic data and have performance extremely close to or even better than the models already existent in the literature. In order to improve the performance of the models, the team also plans to integrate its efforts with research that aims to produce more precise and realistic synthetic movies.
Future research could make better use of synthetic datasets, enabling models to perform more accurately on actual tasks. To reduce some of the ethical, privacy, and copyright concerns associated with using actual datasets, it can also assist researchers in determining which machine-learning applications are most suited for training with synthetic data.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'How Transferable are Video Representations Based on Synthetic Data?'. All Credit For This Research Goes To Researchers on This Project. Check out the paper and reference article.
Please Don't Forget To Join Our ML Subreddit
![]()
Khushboo Gupta is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Goa. She is passionate about the fields of Machine Learning, Natural Language Processing and Web Development. She enjoys learning more about the technical field by participating in several challenges.
Credit: Source link
Comments are closed.