Adept AI Introduces Fuyu-Heavy: A New Multimodal Model Designed Specifically for Digital Agents
With the growth of trending AI applications, Machine Learning ML models are being used for various purposes, leading to an increase in the advent of multimodal models. Multimodal models are very useful, and researchers are putting a lot of emphasis on these nowadays as they help mirror the complexity of human cognition by integrating diverse data sources such as text and images. Also, these models are valuable in various applications in multiple domains.
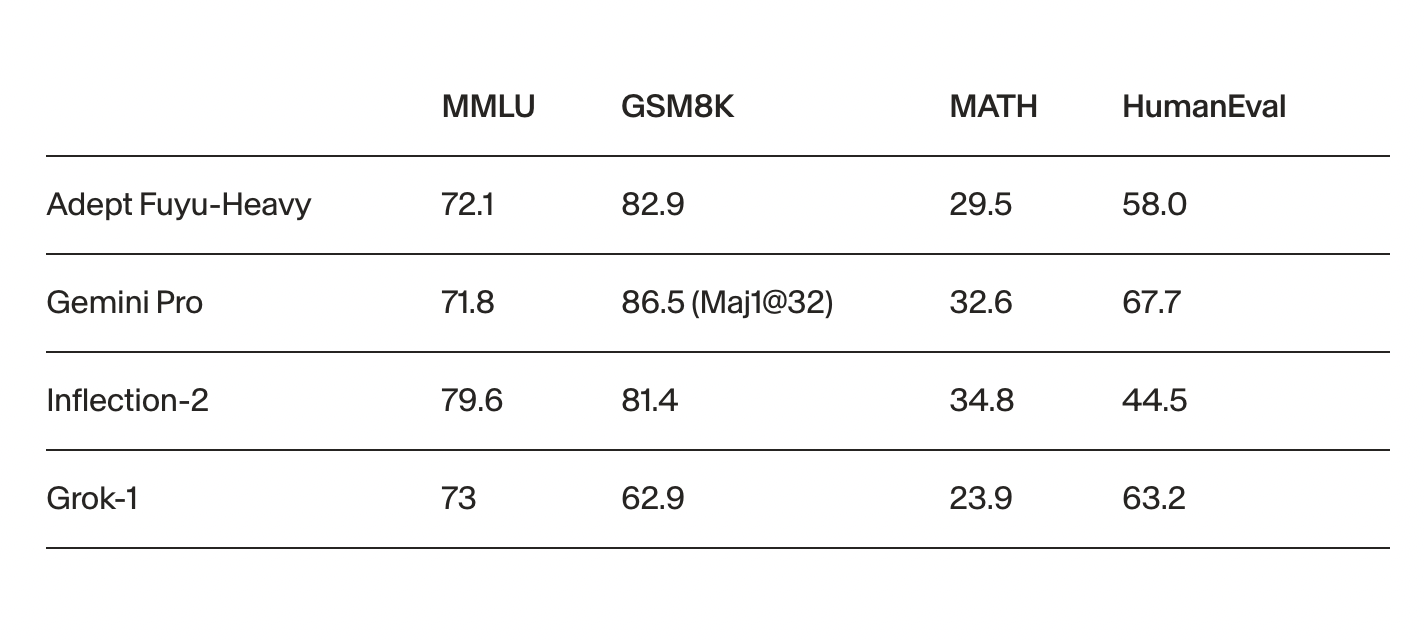
Adept AI researchers have come up with a new multimodal model named Fuyu-Heavy. It is the world’s third-most-capable multimodal model; only GPT4-V and Gemini Ultra are ahead yet surpassed Gemini Pro in Multimodal Language Understanding (MMLU) and Multimodal Model Understanding (MOU). The researchers emphasize that the model is smaller than its counterparts but demonstrates commendable performance across various benchmarks. The researchers emphasize that the development of Fuyu-Heavy needed to have a balance between language and image modeling tasks. For this, they tried and used specialized methodologies for optimal performance at scale.
In their recent blog post, the Adept AI researchers highlighted that the formulation of Fuyu-Heavy was very challenging. The very scale of developing such a large model led to many challenges. Further, the intricate task of training a novel architecture on textual and visual data caused many challenges. Also, the training image data exerted substantial stress on systems, necessitating the management of data influx, memory utilization, and cloud storage bandwidth.
Also, researchers needed more high-quality image pre-training data, which was a further challenge. This compelled researchers to formulate innovative dataset methods, and thus, they used existing resources and synthetically generated data for the model’s image-processing capabilities. Additionally, handling the coordinate systems during the training and inference stages and diverse image formats presented formidable challenges. To tackle these challenges, the researchers had to pay attention to detail and rigorous quality assurance measures.

The researchers tested the model on various benchmarks. They found that it surpasses the performance of many larger models within its computing class and performs equally well on many other large models, showing the accuracy and ability of this model. Further, they found that Fuyu-Heavy Chat proved effective in conversational AI, as it has capabilities similar to larger counterparts like Claude 2.0 on widely used chat evaluation platforms such as MT-Bench and AlpacaEval 1.0.
They emphasized that they would focus on improving the base-model capabilities in the future. As per the blog post, the research team is studying how to convert these base models into useful agents through reward modeling, self-play, and various inference-time search techniques. They also focus on connecting these models to build useful, reliable products. This model’s ability to integrate text and image processing tasks shows its potential across diverse domains. As the researchers work to improve the effectiveness and capabilities of this model, the practical applications of Fuyu-Heavy will increase.
![]()
Rachit Ranjan is a consulting intern at MarktechPost . He is currently pursuing his B.Tech from Indian Institute of Technology(IIT) Patna . He is actively shaping his career in the field of Artificial Intelligence and Data Science and is passionate and dedicated for exploring these fields.
Credit: Source link
Comments are closed.