Adobe AI Researchers Open-Source Image Captioning AI CLIP-S: An Image-Captioning AI Model That Produces Fine-Grained Descriptions of Images
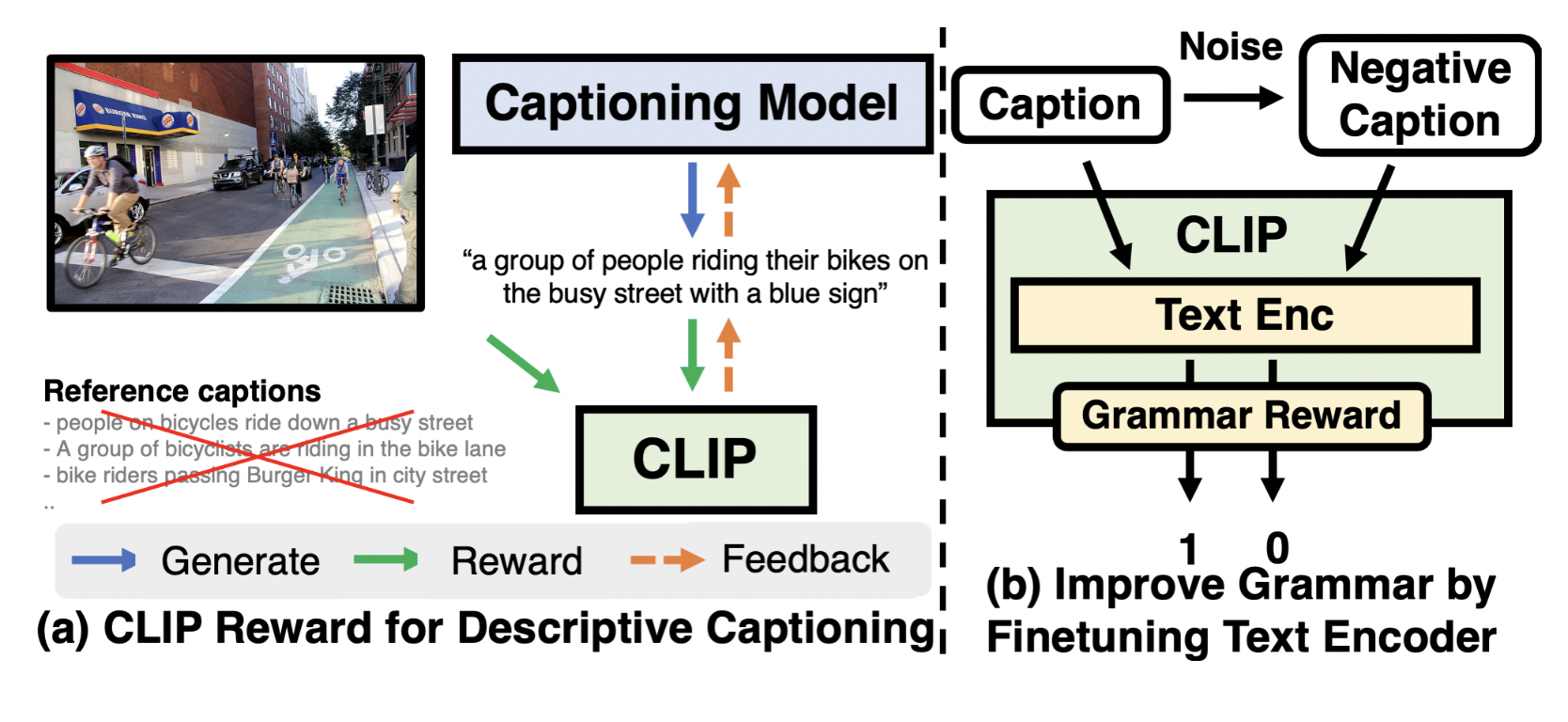
Most of the time, text similarity goals are used to train modern image captioning algorithms. However, models trained with text similarity methodology often neglect particular and intricate features of an image that set it apart from others because reference captions in public datasets frequently describe the most common things. The Adobe team decided to solve this issue by building on top of OpenAI’s existing CLIP model. CLIP is used to evaluate generated captions wherein a text string and an image is compared, and the higher the similarity, the better the text describes the image. The researchers developed the captioning model using RL training and a reward mechanism called CLIP-S. CLIP-S is a multimodal image captioning model developed by a team of researchers from Adobe and the University of North Carolina (UNC). This model generates precise descriptions of the images. The model was also recently open-sourced. Humans overwhelmingly preferred the earlier captions when comparing those produced by CLIP-S to those produced by other models. A paper for the 2022 Annual Conference of the North American Chapter of the Association for Computational Linguistics described the model and experiments in-depth (NAACL).
To create captions for an input image, CLIP-S uses a transformer-based paradigm. During training, the model uses CLIP to assess how well the generated caption describes the image. The final score serves as a signal for reinforcement learning rewards (RL). Additionally, the researchers made cautious in evaluating the generated captions’ grammar by refining CLIP using negative caption instances produced by arbitrarily changing reference captions. This demonstrated that the CLIP-S model had the flaw of frequently producing grammatically incorrect captions. By giving negative examples with randomly repeated, inserted, or jumbled tokens, they solved this problem by optimizing the text-encoder component of CLIP.
Along with the text-encoder fine-tuning, they also introduced a two-layer perceptron classifier head to determine whether a sentence is grammatically correct. The team also created a new benchmark dataset, FineCapEval, which comprises more in-depth image captions defining image backgrounds and relationships between objects to solve the inadequacies of previous image-captioning evaluation methods. Five hundred photos from the Conceptual Captions validation split and the MS COCO test split are included in this collection. Complex information about each image was manually annotated. These facts included the background, the objects in the image, the relationships between the objects, and a descriptive caption containing all three characteristics mentioned above. For each of the four criteria, there are 1 000 photos and 5000 captions in the dataset.
Using the COCO dataset as a standard, the model was compared to numerous baseline models. A baseline model fared better than CLIP-S on text-based measures like BLEU, but CLIP-S outperformed on text-to-image retrieval and image-text metrics. Additionally, it surpassed baselines on the team’s brand-new FineCapEval benchmark “substantially.” Multimodal image-text AI models are a hot research issue due to the daily significant technological advancements. The research community’s ability to use CLIP-S for assignments involving images and text excites the team.
This Article is written as a summary article by Marktechpost Staff based on the research paper 'Fine-grained Image Captioning with CLIP Reward'. All Credit For This Research Goes To Researchers on This Project. Checkout the paper, github and reference article. Please Don't Forget To Join Our ML Subreddit
Credit: Source link
Comments are closed.