Advancing Image Inpainting: Bridging the Gap Between 2D and 3D Manipulations with this Novel AI Inpainting for Neural Radiance Fields
There has been enduring interest in the manipulation of images due to its wide range of applications in content creation. One of the most extensively studied manipulations is object removal and insertion, often referred to as the image inpainting task. While current inpainting models are proficient at generating visually convincing content that blends seamlessly with the surrounding image, their applicability has traditionally been limited to single 2D image inputs. However, some researchers are trying to advance the application of such models to the manipulation of complete 3D scenes.
The emergence of Neural Radiance Fields (NeRFs) has made the transformation of real 2D photos into lifelike 3D representations more accessible. As algorithmic enhancements continue and computational demands decrease, these 3D representations may become commonplace. Therefore, the research aims to enable similar manipulations of 3D NeRFs as are available for 2D images, with a particular focus on inpainting.
The inpainting of 3D objects presents unique challenges, including the scarcity of 3D data and the necessity to consider both 3D geometry and appearance. The use of NeRFs as a scene representation introduces additional complexities. The implicit nature of neural representations makes it impractical to directly modify the underlying data structure based on geometric understanding. Additionally, because NeRFs are trained from images, maintaining consistency across multiple views poses challenges. Independent inpainting of individual constituent images can lead to inconsistencies in viewpoints and visually unrealistic outputs.
Various approaches have been attempted to address these challenges. For example, some methods aim to resolve inconsistencies post hoc, such as NeRF-In, which combines views through pixel-wise loss, or SPIn-NeRF, which employs a perceptual loss. However, these approaches may struggle when inpainted views exhibit significant perceptual differences or involve complex appearances.
Alternatively, single-reference inpainting methods have been explored, which avoid view inconsistencies by using only one inpainted view. However, this approach introduces several challenges, including reduced visual quality in non-reference views, a lack of view-dependent effects, and issues with disocclusions.
Considering the mentioned limitations, a new approach has been developed to enable the inpainting of 3D objects.
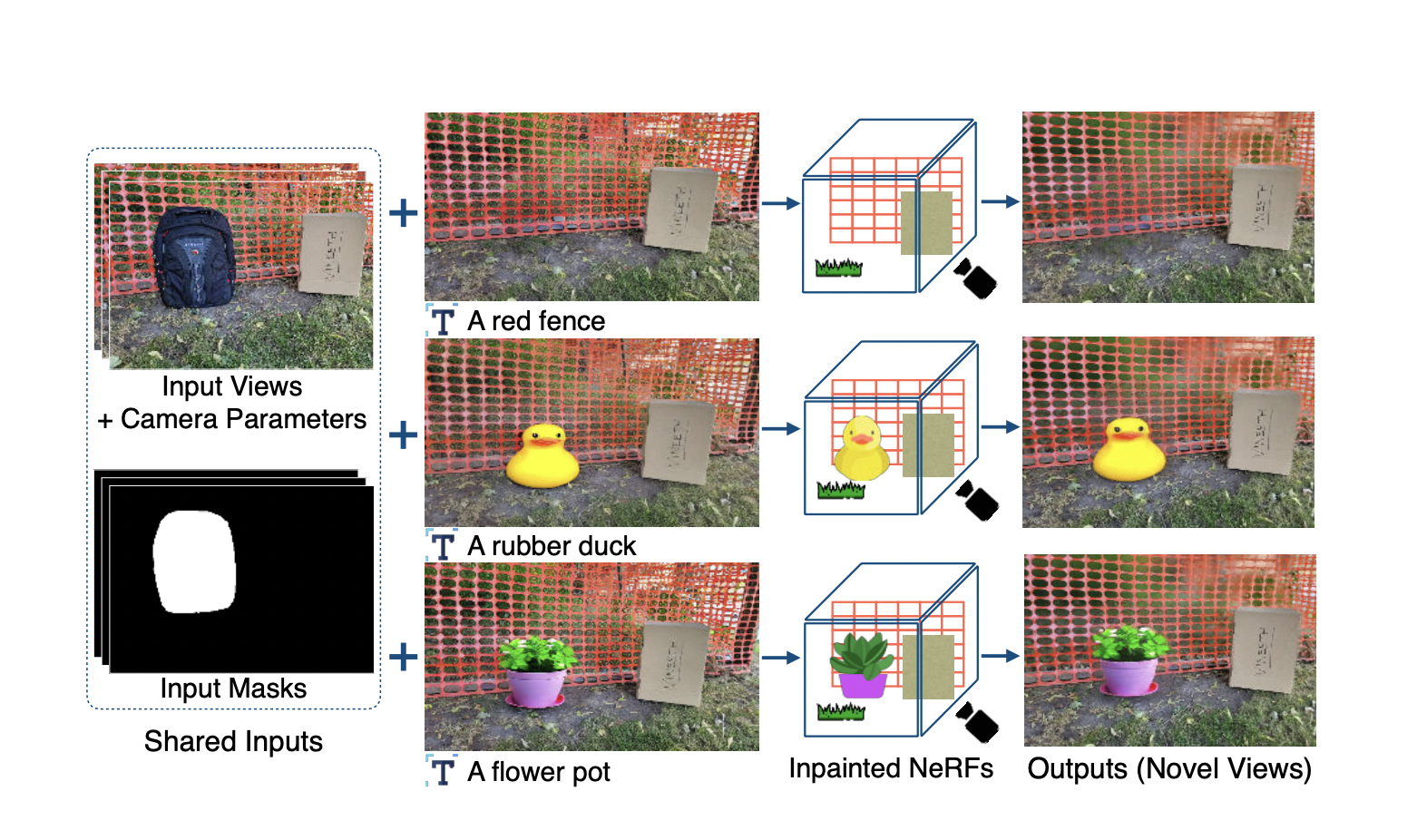
Inputs to the system are N images from different perspectives with their corresponding camera transformation matrices and masks, delineating the unwanted regions. Additionally, an inpainted reference view related to the input images is required, which provides the information that a user expects to gather from a 3D inpainting of the scene. This reference can be as simple as a text description of the object to replace the mask.

In the example reported above, the “rubber duck” or “flower pot” references can be obtained by employing a single-image text-conditioned inpainter. This way, any user can control and drive the generation of 3D scenes with the desired edits.
With a module focusing on view-dependent effects (VDEs), the authors try to account for view-dependent changes (e.g., specularities and non-Lambertian effects) in the scene. For this reason, they add VDEs to the masked area from non-reference viewpoints by correcting reference colors to match the surrounding context of the other views.
Furthermore, they introduce monocular depth estimators to guide the geometry of the inpainted region according to the depth of the reference image. Since not all the masked target pixels are visible in the reference, an approach is devised to supervise such unoccluded pixels via additional inpaintings.
A visual comparison of novel view renderings of the proposed method with the state-of-the-art SPIn-NeRF-Lama is provided below.

This was the summary of a novel AI framework for reference-guided controllable inpainting of neural radiance fields. If you are interested and want to learn more about it, please feel free to refer to the links cited below.
Check out the Paper and Project Page. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Daniele Lorenzi received his M.Sc. in ICT for Internet and Multimedia Engineering in 2021 from the University of Padua, Italy. He is a Ph.D. candidate at the Institute of Information Technology (ITEC) at the Alpen-Adria-Universität (AAU) Klagenfurt. He is currently working in the Christian Doppler Laboratory ATHENA and his research interests include adaptive video streaming, immersive media, machine learning, and QoS/QoE evaluation.
Credit: Source link
Comments are closed.