AI Research Group From NVIDIA Unveils An Advanced Framework To Estimate Physically Correct Human Motions
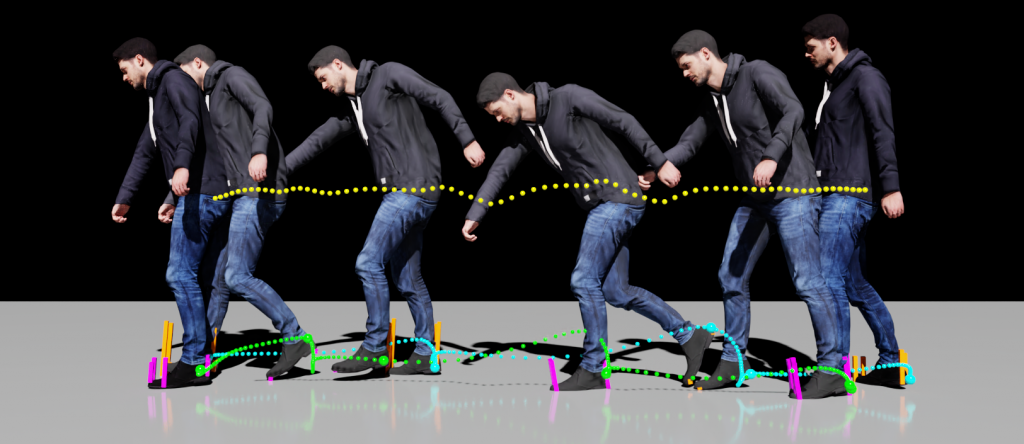

It is no secret that human motion synthesis has been a complex and, as of yet, unmet need. Existing techniques are limited by the lack in quality capture data, which can be expensive to acquire for training purposes – especially with current technology limitations such as human slow-mo videos.
A research team from NVIDIA, University of Toronto and Vector Institute developed a method for generating human motion based on monocular RGB videos that do not require expensive equipment like motion capture. The new system, which is more efficient and accurate than previous ones in its class, uses contact invariant optimization to refine noisy image-based pose estimates by enforcing physics constraints through computing forces interacting with each other naturally. The researchers refine the model by feeding it through a time-series generative network that synthesizes future motion and contact forces.
By introducing a smooth contact loss function, the team could refine pose estimates without using separately trained detectors or solving nonlinear programming problems. The study also demonstrates that when combined with the presented physics-based optimization, even without access to motion capture datasets, it is still possible and sufficient for an algorithm or model trained through visual pose estimation alone.

The referred method was validated on the Human3.6m dataset and demonstrated both qualitatively and quantitatively improved motion synthesis quality and physical plausibility achieved by the proposed model compared to prior work such as PhysCap or HMR models.
Key takeaways:
- In this research, a new framework was introduced for training motion synthesis models from raw video pose estimations without using any of the expensive and time-consuming processes.
- The proposed framework refines noisy pose estimates by enforcing physics constraints through contact invariant optimization, including the computation of contact forces.
- Time-series generative model was then trained on the refined poses, synthesizing both future motion and contact forces.
- The detailed analysis of the results demonstrated significant performance boosts in pose estimation via a physics-based refinement and motion synthesis from video.
Paper: https://arxiv.org/pdf/2109.09913.pdf
Project: https://nv-tlabs.github.io/physics-pose-estimation-project-page/
Suggested
Credit: Source link
Comments are closed.