AI Researchers at Amazon Develop a Novel Technique by Training a Neural Network to Have Better Joint Representations of Image and Text
Joint image-text embedding is the foundation of most Vision-and-Language (V+L) tasks, where multimodality inputs are simultaneously processed for combined visual and textual understanding. It functions by requiring an input image and a written description of the image. The study of image-text feature alignment and the training of neural networks to generate joint representations of pictures and the words that go with them have both seen a surge in attention. These representations are helpful for various computer vision applications, including text- and picture-based image searching.
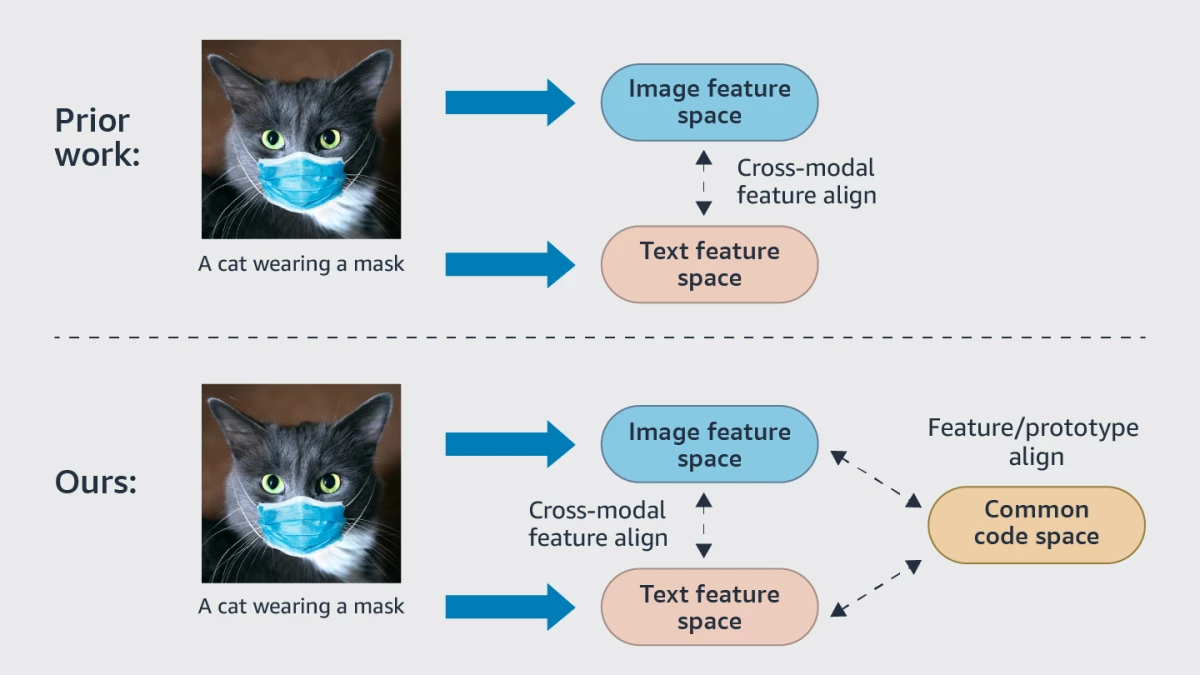
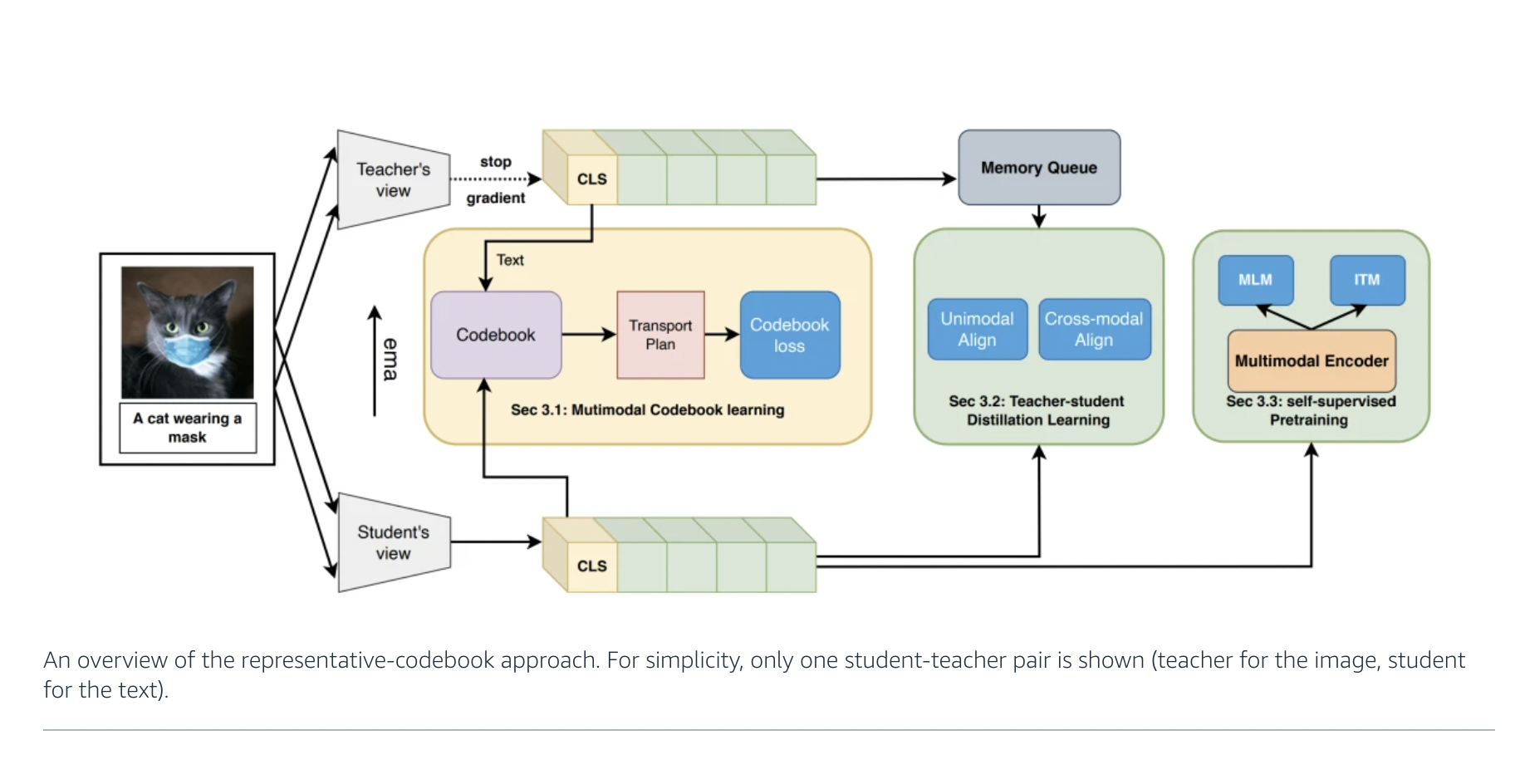
A novel method of aligning images and texts considers them as different “views” of the same thing and employs a codebook of cluster centers to cover the whole combined vision-language coding space.
Joint image-text models are often trained via contrastive learning. The model is fed training samples in pairs, one positive and one negative, and learns to push the positive and negative instances apart in the representation space. The model would then learn to link pictures with the proper labels in a standard, multimodal representative space, for instance, by being trained on pairs of photos with associated text labels, one of which was the correct label and the other was random.
Robust contrastive learning may enforce alignment across various modalities, leading to the degradation of the learned characteristics. Image-text representation learning aims to cluster pictures with their corresponding texts. In contrast, a neural network trained on multimodal input would naturally prefer to group data of the same type in the representational space. Researchers at Amazon are looking into several methods of adding more structure to the representational space to solve the issue of developing more reliable image-text alignments.
A novel method of aligning images and texts considers them different “views” of the same thing. It employs a codebook of cluster centers to cover the combined vision-language coding space. It can be thought of as depicting an image and a text as two distinct perspectives of the same object and using a codebook of cluster centers to cover the combined vision-language coding space. Whether the notions are portrayed visually or textually, each center is the anchor for a group of connected ideas. “Multimodal alignment utilizing representation codebook” suggests employing cluster representation to align pictures and text at a higher, more stable level to counteract this tendency.
Researchers contrast positive and negative data during training using their cluster assignments while optimizing the cluster centers. Additionally, these models can compete on several additional transfer tasks. The capacity of contrastive learning to optimize the mutual information between image and text pairings, or the degree to which picture features can be anticipated, has been credited with its effectiveness in training image-text alignment models. Cross-modal alignment (CMA) alone, however, misses potentially significant connections within each modality. For instance, while mapping image-text pairings closely in the embedding space, CMA does not ensure that inputs from the same modality that is comparable to one another remain so. If the pretraining data is noisy, the issue might grow even worse. Researchers use triple contrastive learning (TCL) for vision-language pretraining. This method uses cross-modal and intra-modal self-supervision or training on designed tasks such that labeled training examples are not necessary.
The method aims at maximizing the average mutual information between local sections of the image/text and their overall summary. Using localized and structural information from the input of the picture and text makes this research innovative. Experimental assessments demonstrate that this technique is competitive and reaches the new state-of-the-art on various prevalent downstream vision-language tasks, including image-text retrieval and visual question answering.
This Article is written as a summary article by Marktechpost staff based on the Amazon's research papers: Paper 1 and Paper 2. All credit for this research goes to researchers on this project. Please Don't Forget To Join Our ML Subreddit
Credit: Source link
Comments are closed.