AI Researchers At Amazon Develop GIT: Generative Insertion Transformer For Controlled Data Generation Via Insertion Operations

This Article Is Based On The Research 'Controlled Data Generation via Insertion Operations for NLU'. All Credit For This Research Goes To The Researchers Of This Paper 👏👏👏 Please Don't Forget To Join Our ML Subreddit
Natural language processing (NLP) is a computer science paradigm concerned with computers’ capacity to understand the text and spoken words in a way that humans can.
The requirement for annotation of user input continuously is one of the most common obstacles in deploying natural language understanding algorithms at scale in commercial applications. This procedure is costly, time-consuming, and labor-intensive.
Manual inspection of user data, which is generally necessary for such annotation, becomes increasingly unattractive at a time when user privacy is becoming a growing problem in all AI applications. As a result, a number of attempts are underway to reduce the number of human annotations required to train NLU models.

Data augmentation (DA) is a term used to describe ways to boost the diversity of training samples without gathering new data. Amazon researchers recently proposed a generative technique for generating tagged synthetic data in a paper. The goal was to build synthetic utterances and augment the original training data with a collection of utterance templates that the team built from a limited quantity of labeled data.
Researchers focused on the unique scenario where synthesized data must retain a certain fine-grained interpretation of the original utterance. For example, while extending to new features, researchers wished to retain NLU model performance while controlling the composition of entities in the training data.
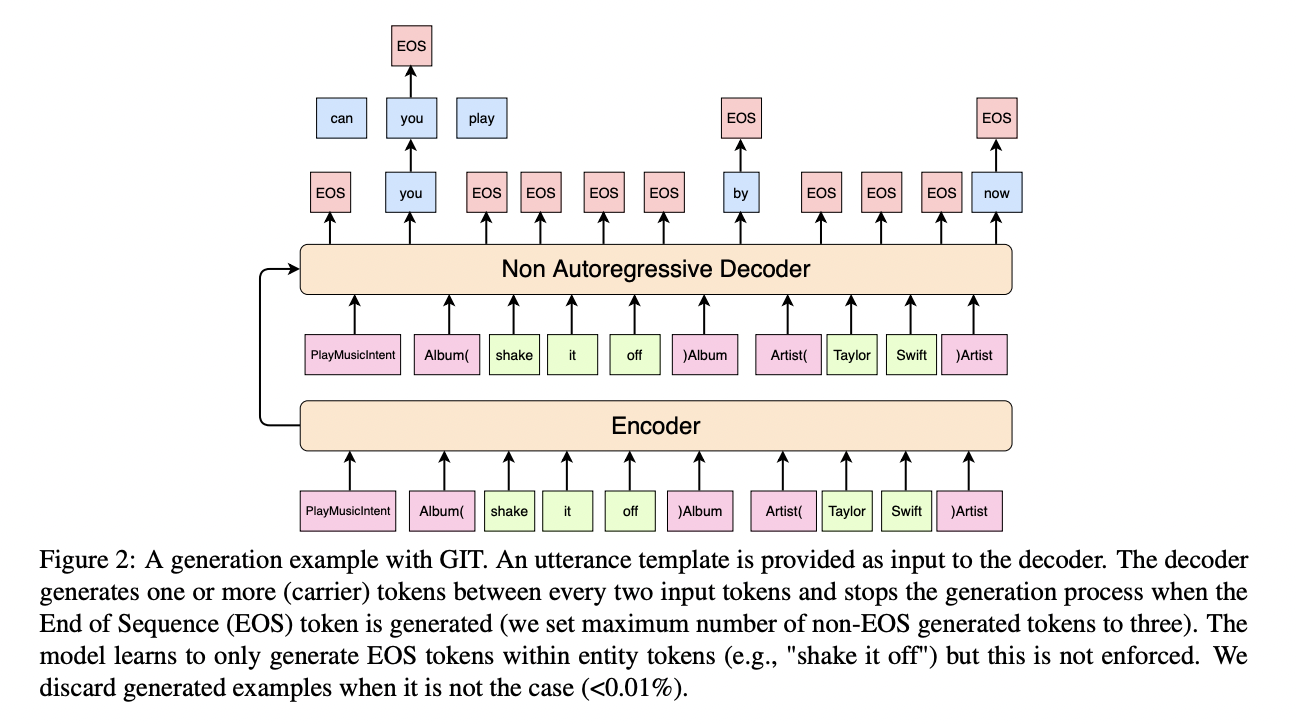
By re-framing the generation process as insertion rather than generation, the team was able to control the intended annotation. The desired entities in the synthetic example were kept by putting them in the model’s input during creation, and they introduced ways to explicitly prevent entity corruption throughout the generation process.
NLU models trained on 33 percent actual data and synthetic data perform similarly to models trained on full real data, according to the researchers. The team also improved the quality of synthetic data by filtering it with model confidence scores. The researchers demonstrated that suitable token insertion improves the semantics of utterances and their utility as training examples.
Conclusion
In a recent publication, Amazon researchers demonstrated Data Augmentation using the Generative Insertion Transformer as a viable data production strategy for intent classification and named entity recognition model workloads to counteract decreasing annotation volumes due to privacy issues. This greater control over entities makes it easier to add new features and protects client privacy. Researchers would be further working on improving the model performance and adding new domains to the research.
Paper: https://assets.amazon.science/88/66/9bdacd4c48bd84c61f5e52070783/controlled-data-generation-via-insertion-operations-for-nlu.pdf
Source: https://www.amazon.science/publications/controlled-data-generation-via-insertion-operations-for-nlu
Credit: Source link
Comments are closed.