AI Researchers From China Designed An Image Classification Algorithm, FGVC, Based On Self-Attention Feature Fusion And Graph-Propagation
Analyzing images from subordinate categories such as airplane models or bird species is fine-grained image classification’s main goal (FGVC) goal. Due to the fine-grained nature of the problem, the small inter-class variations, and the large intra-class variations, FGVC is a very challenging task.
Generally, the methods dealing with this subject are divided into two categories: Localization methods and Feature-encoding methods. The first approach consists of using bounding boxes during the training phase to detect the discriminating objects and compare the bounding boxes of the different images. The second approach focuses on feature extraction from images to improve learned features’ relevance. This is often achieved through the use of the bilinear pooling operation to take into account the relationships between the different features. Unfortunately, Localization methods require additional manual work, which consists of creating bounding boxes, whereas Feature-encoding methods are generally not easy to interpret.
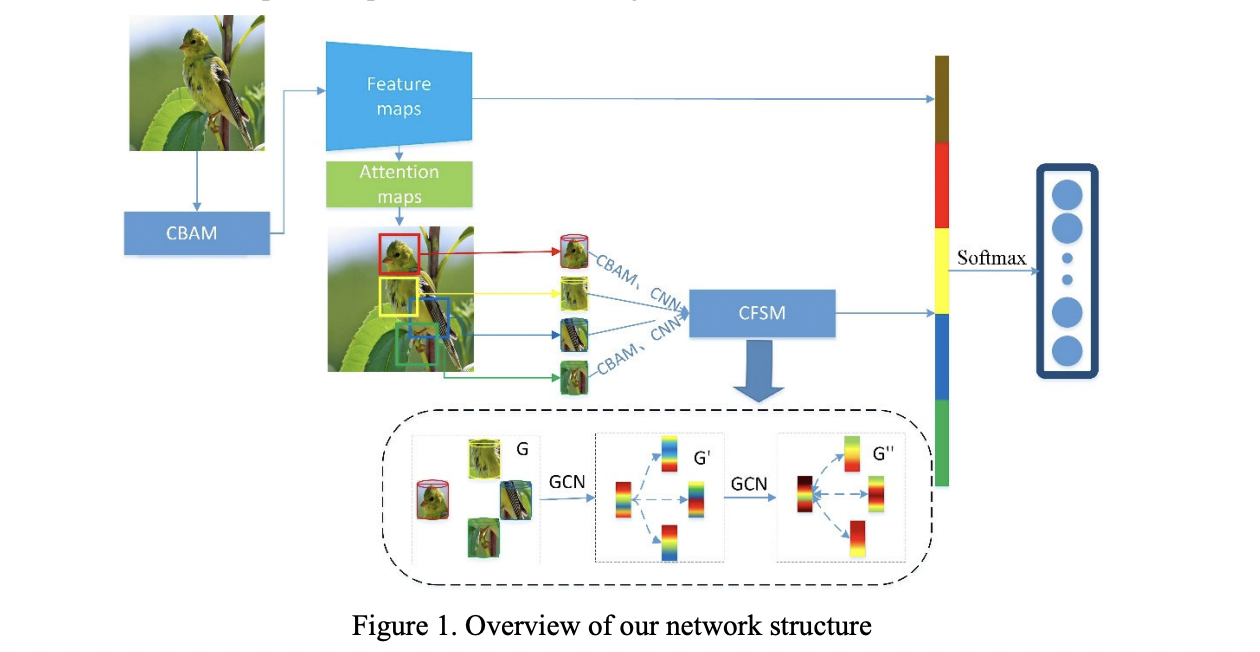
Researchers at the Wuhan University of Technology propose a novel end-to-end image classification algorithm based on self-attention feature fusion and graph propagation by the use of CBAM and CFSM. The proposed network aims to detect and combine local and global feature information and to capture the spatial relationship of the fine-grained detected regions intelligibly.
Concretely, CBAM, an attention block that combines channel and the spatial domain, is applied to focus on both location information and the content of features. In addition, three different feature figure scales are used to generate different feature regions in the image and different scale information. This way, large-scale images will provide global information, while small-scale images will provide local information. Those different features are then combined to make the overall network able to make classification-based global and local features and to achieve better accuracy. Then, the feature map obtained from the feature extraction module, which is based on resnet50 and CBAM, is converted into the attention map. Each attention map represents a visual feature or a part of an object such as a car’s wheel or a bird’s tail. Next, multi-scale regions are found using a top-down, horizontally connected structure, and several convolution layers’ feature vectors are calculated layer by layer. Finally, thanks to the CFSM, a graph is constructed to mine the correlation between selected objects (patches). CFSM allows the network to explore the internal semantic correlation between region feature vectors to obtain a better discriminative ability.

To ensure the smooth running of the training phase, the authors have introduced a new loss function called focal loss, which is based on the center loss function and aims to solve the imbalance in the number of hard and easy samples.
The approach proposed in this paper was evaluated through three datasets (CUB200, Stanford Cars, and FGVC Aircraft). The results obtained show that the proposed network outperforms several state-of-the-art structures. This is shown through a performance comparison as well as through visualization results.
We have seen in this article a new method to solve the problem of FGVC, which allows both to find the fine discriminating parts and the global information as well as the spatial relations between the different detected parts. The framework created by this research team has achieved excellent classification performance. Unfortunately, it is not yet suitable for large-scale practical applications because of its multi-channel characteristics. In future work, authors will improve the proposed network so it can be applied in real life.
This Article is written as a paper summary article by Marktechpost Research Staff based on the paper 'Fine-Grained Image Classification based on Self-attention Feature Fusion and Graph-Propagation'. All Credit For This Research Goes To Researchers on This Project. Checkout the paper. Please Don't Forget To Join Our ML Subreddit
Credit: Source link
Comments are closed.