AI Researchers from China Suggest a Robust Foundation for Multimodal Connection Extraction Based on an Implicit Fine-Grained Multimodal Alignment and Transformer
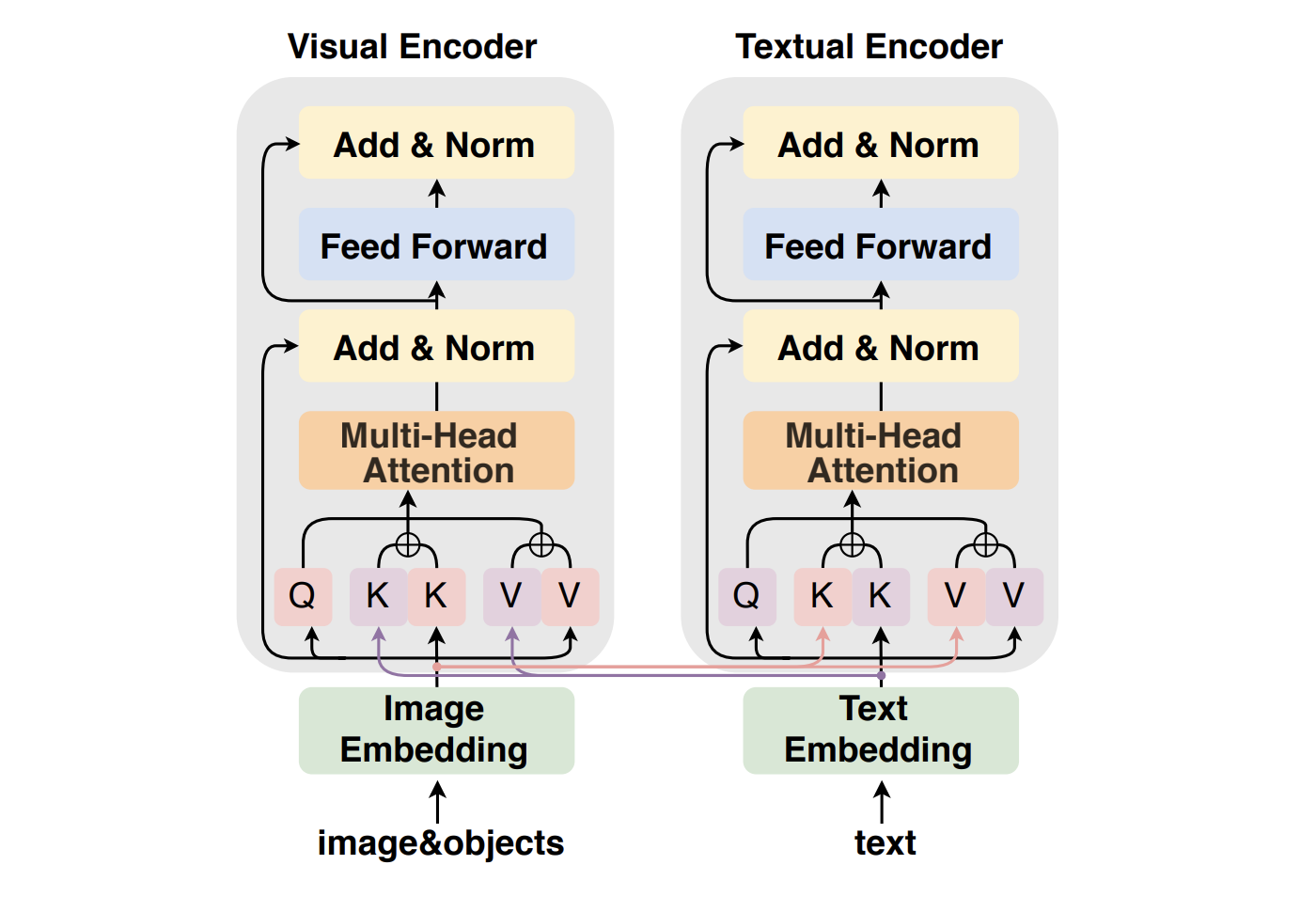
The goal of relation extraction (RE), which is helpful for many knowledge-driven activities, is to determine the semantic relationships between two elements in a phrase. However, because social media texts lack context, they may perform noticeably worse than traditional RE approaches because they are text-based. Textual material is frequently combined with visual content, such as Twitter image postings. It makes sense to include visual material to fill in the gaps when semantic information is lacking to boost performance.
Visual-enhanced relation extraction, or MRE as often called, tries to categorize relationships between two entities using visual components. Zheng and colleagues recently introduced it. The SOTA technique MEGA effectively determines the mapping from visual to textual contents based on syntactic dependency trees and visual scene graphs, thereby enhancing MRE performance. In this research, they examine the internal workings of MRE in greater detail and produce some intriguing empirical results. They discover that not all visual information enhances performance.
Additionally, the empirical research shows that the model performs less well for specific relations than pure text-based RE models due to the missing and misleading information in the scene graph. They build a more accurate visual-enhanced RE model based on the discovery mentioned above. They provide an Implicit Fine-grained Multimodal Alignment technique using a Transformer (IFAformer), which aligns textual and visual items in relational representation space. They build a more accurate visual-enhanced RE model based on the discovery mentioned above.
Visual and textual items are aligned in representation space using the Implicit Fine-grained Multimodal Alignment method with Transformer (IFAformer) that they suggest. They thus examine the importance of visual information in the MRE task in more detail. To compare the results with the benchmark dataset, they execute visual shuffle experiments in which they randomly mix the image-text pairs.
Researchers study the structural alignment map of MEGA’s objects and text words, as shown in the figure below. They suggest the analysis and debate that follows: Valid or unstable performance? Their findings cast doubt on the model’s ability to use matching visual elements and direction. Even if the image-text combinations are misaligned, MEGA performs flawlessly, as shown in the table that follows. Additionally, they observe that the original MEGA, which was trained on standards, may achieve steady performance for image-text mismatches.
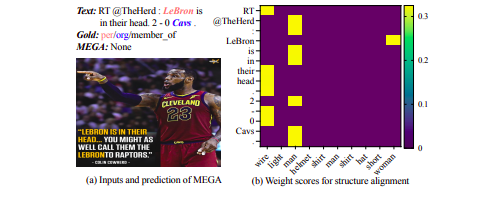

Does the scene graph match the tokens? They claim two reasons behind these: (1) While entities in the text are specific, visual objects produced by scene graphs are universal and straightforward; (2) coarse-grained alignment cannot bridge the semantic gap between visual and text. Some visual items, such as the guy and shirt in Figure 1, are duplicated, and others are drawn incorrectly (wire), leading to inaccurate MEGA alignment weights. Overall, the coarse-grained scene graph alignment may not effectively use visual cues for RE. One can use the trained model for predictions using the code that has been made available on GitHub.

Check out the paper and code. All Credit For This Research Goes To Researchers on This Project. Also, don’t forget to join our Reddit page and discord channel, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.