AI Researchers From Korea Introduce ‘DailyTalk’, A High-Quality Conversational Speech Dataset Designed For Text-To-Speech
The most important thing for a Text-to-Speech TTS system is to save and communicate the context of the present discourse. Current TTS models have context representation constraints since they perceive each speech independently of the address. The lack of open-source datasets, including spoken dialogues, is one of the key reasons why most earlier studies focused on single utterances.
Many popular TTS datasets exist. However, they contain minimal conversation and comprise reading-style utterances in which speakers record audio by reading books or scripts. Some audio corpora derived from real-world conversations or behaviors are publicly accessible, although they have various drawbacks, such as background noise or uneven recording quality. Some recent research offered context-aware TTS models, although they used an internal dataset that is not available to the public.
In this study, researchers provide DailyTalk, a high-quality conversation voice dataset for text-to-speech. DailyTalk is designed to assure general and conversational speech synthesis quality: studio-quality audio, simultaneous recording of two people, and adding filling-gap words in the dataset. We create a new voice dataset for speech synthesis by analyzing and recording selected talks from the DailyDialog dataset.

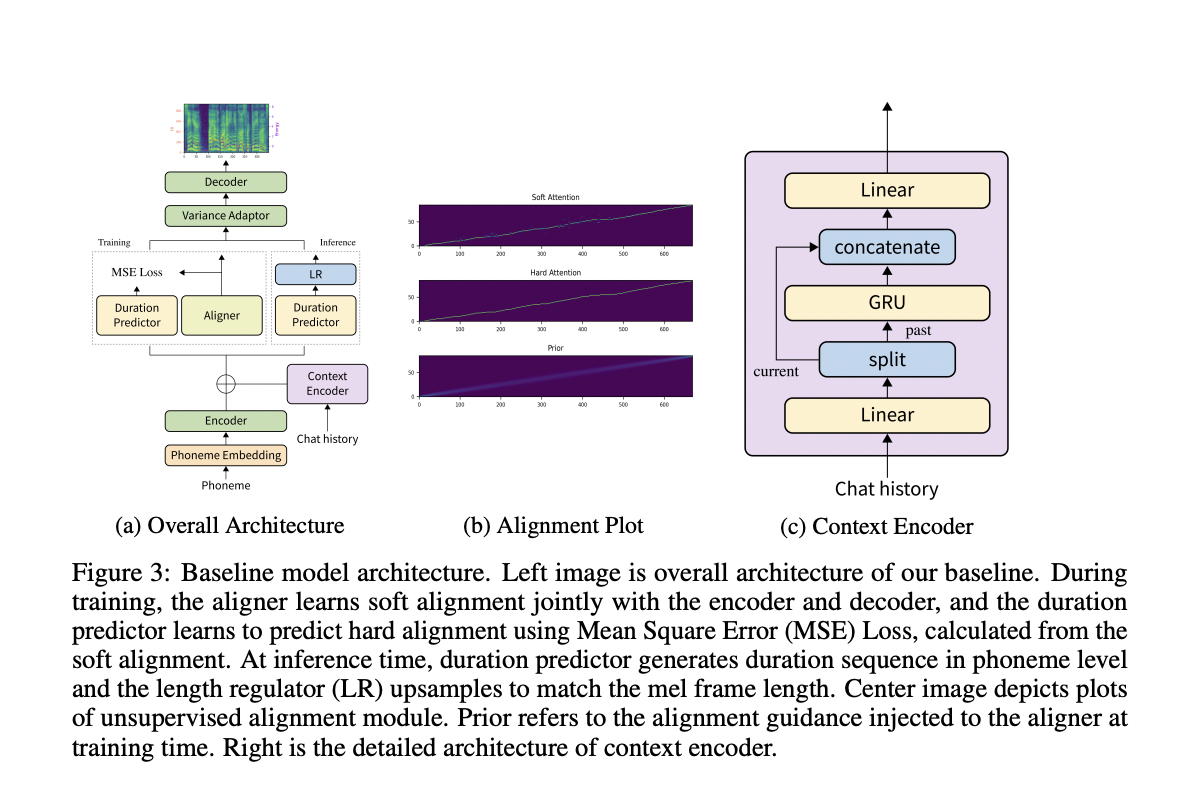
Having a baseline model for conversational TTS allows researchers to examine the influence of contextual information while synthesizing speech. The baseline consumes Dialogue history, which inherits the encoder of is expressed as an aggregation of text representation from BERT and is based on FastSpeech2 architecture. Using this baseline, the training model with the dataset can synthesize natural speech for single utterances and whole dialogues. At the same time, the DailyDialog dataset’s valuable properties, such as its academically open license and numerous discourse annotations, are preserved (emotion, speech act, topic).
The following are the significant contributions of this research:
- The first open dataset for conversational TTS is available
- A set of assessment criteria for conversational TTS
In a nutshell, DailyTalk is a text-to-speech dataset that may represent a variety of properties and circumstances, including conversation. The dataset and pretrained models are publicly available on GitHub.
This Article is written as a summary article by Marktechpost Staff based on the research paper 'DailyTalk: Spoken Dialogue Dataset for Conversational Text-to-Speech'. All Credit For This Research Goes To Researchers on This Project. Checkout the paper and github. Please Don't Forget To Join Our ML Subreddit
Credit: Source link
Comments are closed.