AI Researchers Propose An Easy-To-Use Federated Learning Framework Called ‘FedCV’ For Diverse Computer Vision Tasks
")
Federated Learning (FL) is a distributed learning paradigm that can learn a global or a personalized model for each user relying on decentralized data provided by edge devices. Since these edge devices do not need to share any data, FL can handle privacy issues that make centralized solutions unusable in specific domains (e.g., medical). You can think about a machine learning model for facial recognition. A centralized approach requires uploading the local data of each user externally (e.g., on a server), a solution that cannot ensure data privacy.
Considering FL in the Computer Vision (CV) domain, currently, only image classification in small-scale datasets and models has been evaluated, while most of the recent works focus on large-scale supervised/self-supervised pre-training models based on CNN or Transformers. At the moment, the research community lacks a library that connects different CV tasks with FL algorithms. For this reason, the researchers of this paper designed FedCV, a unified federated learning library that connects various FL algorithms with multiple important CV tasks, including image segmentation and object detection. To lighten the effort of CV researchers, FedCV provides representative FL algorithms through easy-to-use APIs. Moreover, the framework is flexible in exploring new protocols of distributed computing (e.g., customizing the exchange information among clients) and defining specialized training procedures.
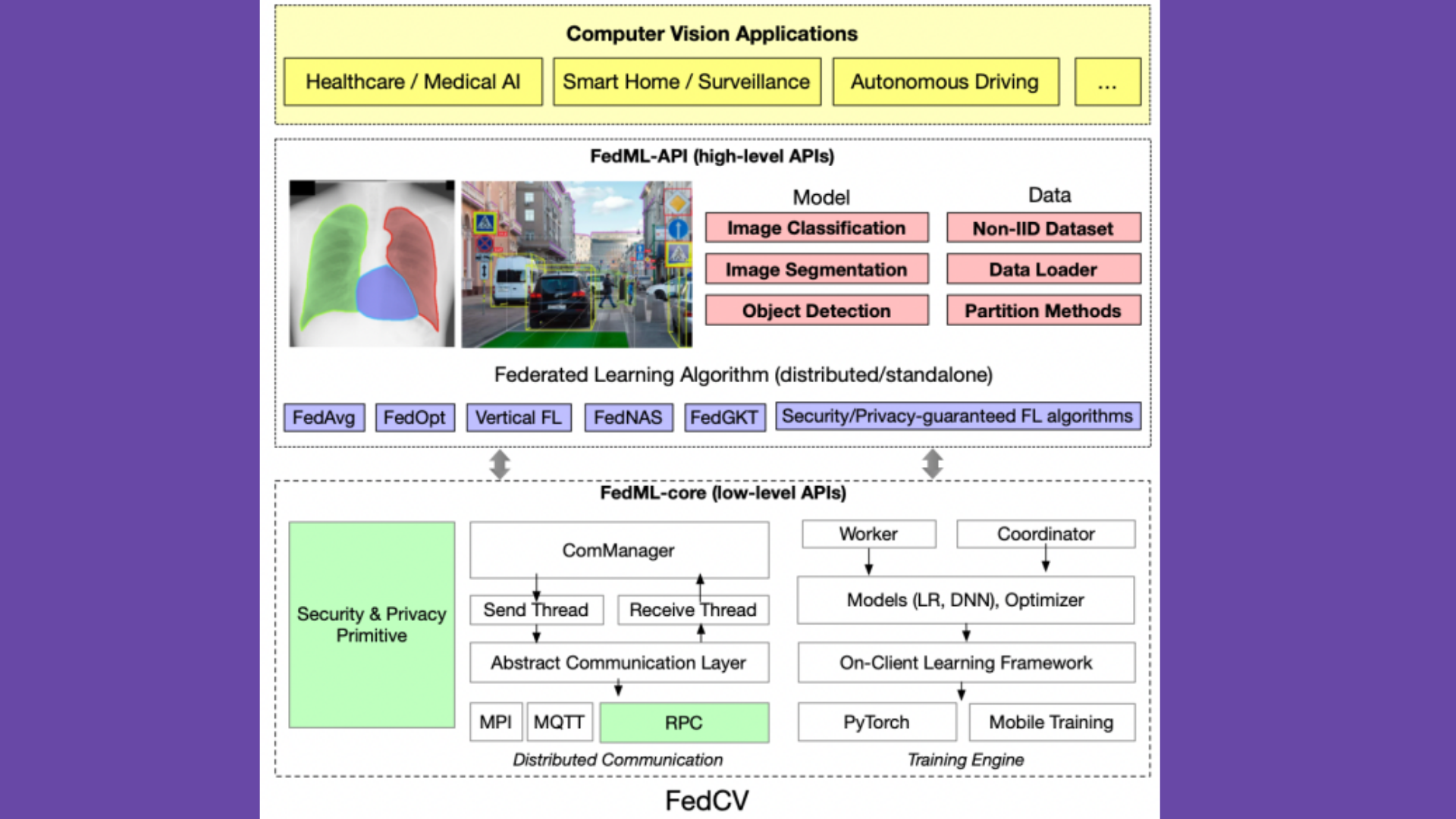
FedCV is built based on the FedML research library, an FL library that only supports image classification, ResNet, and simple CNN models. The figure above illustrates the architecture of FedCV, where the modules specifically provided by FedCV are highlighted through colors. The contributions provided by FedCV are the following:
1. It supports three computer vision tasks, providing related datasets and data loaders: image classification, image segmentation, and object detection. Users can either reuse the data distribution provided by FedCV or partition the available datasets into a non-identical and independent distribution (non-I.I.D.) by setting specific hyper-parameters.
The non-I.I.D. approach is essential to obtain more realistic federated datasets: for instance, in the CV domain, the smartphone of the different users provide images or videos with different resolutions, qualities, and contents because of differences in their hardware and in user behaviors.
2. it includes the standard implementations of multiple state-of-the-art FL algorithms (e.g. FederatedAveraging (FedAvg)) as well as novel algorithms with diverse training paradigms and network types (e.g., Decentralized FL). All these algorithms support multi-GPU distributed training.
3. based on the FedML API design, FedCV enables different networks and training procedures, and flexible information exchange among clients.
4. in the lowest layer, FedCV reuses FedML-core APIs. However, it further supports tensor-aware RPC (remote procedure call) which enables the communication between servers located at different data centers (e.g., different medical institutes). Furthermore, enhanced security and privacy primitive modules are added as well.
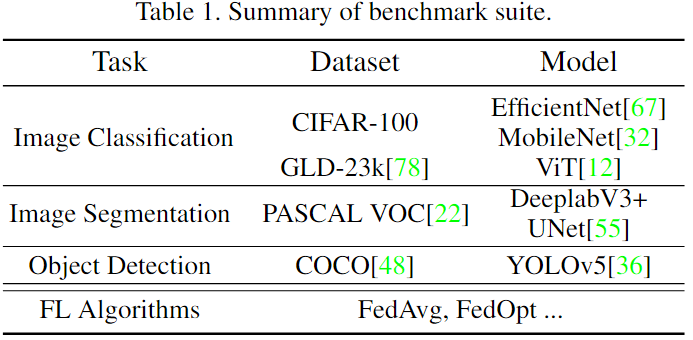
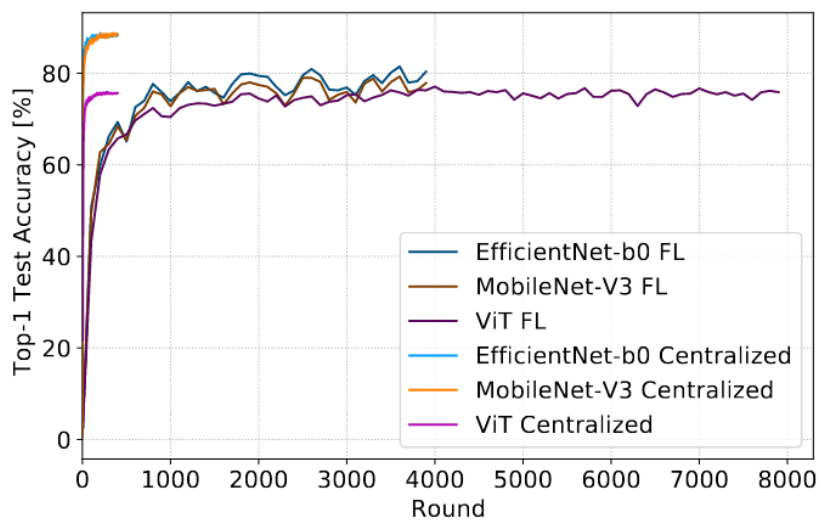
The table above summarizes the benchmark suite provided by FedCV. The benchmark study presented in this paper suggests that improving the system efficiency of federated training is challenging given the huge number of parameters and the per-client memory cost. The recognition rate of FL solutions is sometimes far from the results obtained through centralized approaches. We can consider, for example, the image classification task applied to the Google Landmarks Dataset 23k (GLD-23K). The figure below compares the test accuracy obtained with three models (EfficientNet, MobileNet, and ViT), considering both a centralized and an FL scenario. We can notice how, for instance, the test accuracy of centralized training with EfficientNet and MobileNet outperforms FedAvg training by about ten percent.
To sum up, this paper proposes FedCV, an easy-to-use federated learning framework for different computer vision tasks such as image classification, image segmentation, and object detection. The researchers provide several non-IID benchmarking datasets, models, and FL algorithms. We hope that the research community can use FedCV to explore and develop novel federated algorithms for different computer vision tasks.
Paper: https://arxiv.org/pdf/2111.11066.pdf
GitHub: https://github.com/FedML-AI/FedCV
Suggested
Credit: Source link
Comments are closed.