Allen Institute For AI Researchers Propose GPV-2: A Webly Supervised Concept Expansion For General Purpose Vision Models
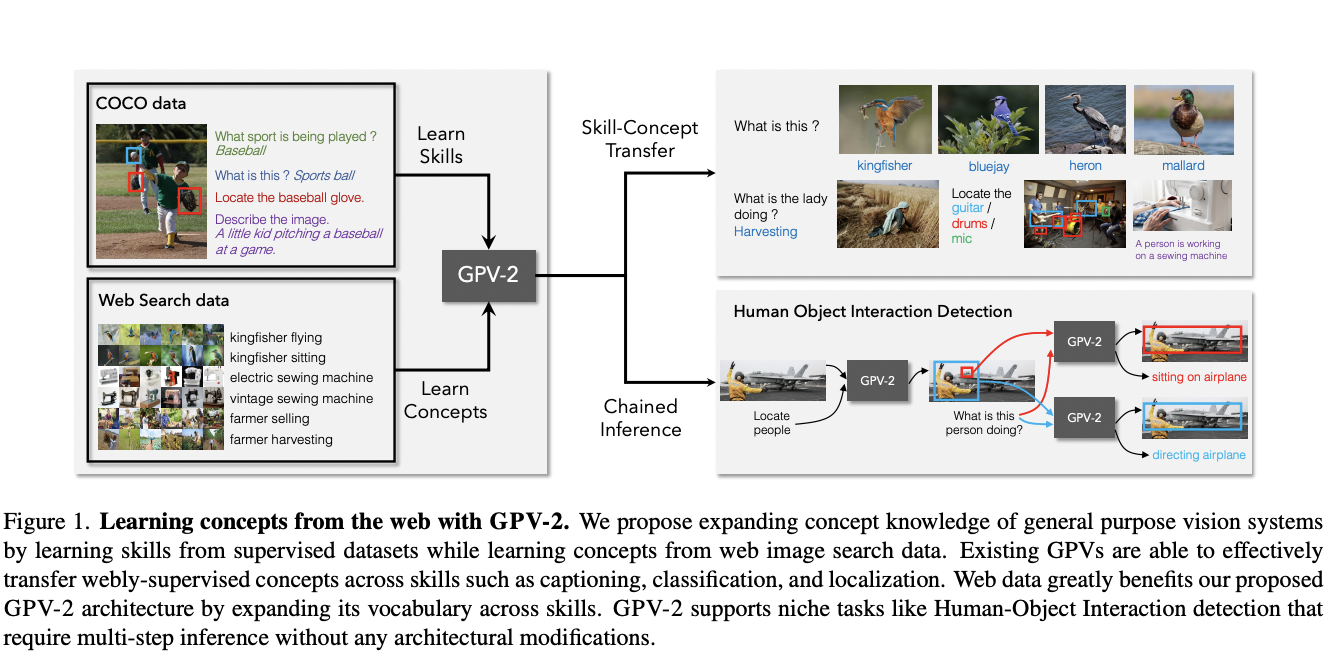

While much of the work in computer vision has been focused on developing task-specific models, there has recently been a drive to develop vision systems that are more generic in nature. GPVs (General purpose vision) or general-purpose vision systems, unlike specialized models, attempt to facilitate learning a wide range of tasks natively, generalize learned skills and concepts to novel skill-concept combinations and learn new tasks quickly.
GPVs are currently trained and evaluated on datasets that are heavily supervised, such as COCO and VISUALGENOME, and expose models to a variety of skill-concept combinations. Learning localization from COCO, for example, exposes the models to 80 ideas in that skill. Expanding the model’s conceptual vocabulary to include new ideas in this paradigm necessitates collecting fully-supervised task data for each of those concepts.
Scaling today’s manually annotated datasets to cover 10,000+ concepts is infeasible due to the high expense of developing high-quality datasets. Learn skills like localization and VQA from today’s vision datasets; learn a massive number of concepts using data from image search engines; and use architectures that can effectively transfer learned concepts across acquired skills, according to a recent study from Allen Institute for AI and the University of Illinois.
Image search engines employ text from associated websites, visual attributes extracted from photos, and click data collected from millions of users searching and picking relevant results every day to offer astonishingly good results for millions of searches. They frequently provide high-quality, distraction-free object and action-centric visuals that can be utilized to develop effective visual representations for topics.
Significantly, searches may scale to thousands of questions quickly and cheaply. The researchers spent just over $150 to collect a dataset with over 1 million photos, dubbed WEB10K, that spans about 10,000 words, 300 verbs, and 150 adjectives, as well as thousands of noun-verb and noun-adj pairings.
Despite the fact that search engine data only provides significant supervision for the task of categorization, the research shows that current GPVs, the GPV-1, and VL-T5, can learn concepts from web data and improve on other skills like captioning. They extend these models by proposing GPV-2, a powerful general-purpose vision system that supports a wider range of modalities (and hence tasks).
GPV-2 may take an image, a task description, and a bounding box (which allows the user to point at a specific object or region of interest) as inputs and output text for any bounding box or the full image. GPV-2 can support a wide range of abilities, including classification and localization in vision, vision-language skills like VQA and captioning, and specialty skills like categorization in context and human-object interaction detection, thanks to its multiple input and output modalities.
All tasks in GPV-2 are based on scoring, ranking, and creation utilizing the same text decoder applied to one or more image areas, ensuring that all tasks have the same weights and representations. The researchers also offer a simple re-calibration approach to reduce the weighting of labels that are overrepresented in training.

The team assesses these GPVs using three criteria: (i) the COCO-SCE and COCO benchmarks, which are designed to test skill-concept ability to transfer and overall skill competency on 80 primary COCO concepts across five skills; (ii) a new benchmark, DCE, which is based on the OPENIMAGES and VISUALGENOME datasets for broader concept evaluation for the same five skills but now across 492 OPENIMAGES concepts instead of the 80 in COCO; and the WEB10K dataset, which is made up of images.
The results suggest that online data benefits all three GPVs. Furthermore, GPV-2 beats both GPV-1 and VL-T5 in all of these tasks and exhibits significant gains when using online data, especially for captioning and categorization. In a 0-shot situation, GPV-2 also performs well on downstream tasks such as action and visual attribute detection. Finally, the researchers show how GPV-2 may be chained to perform niche tasks such as human-object interaction detection without requiring any task-specific design changes.
In summary, the main contributions are (a) WEB10K, a new web data source for learning over 10k visual concepts with an accompanying human-verified VQA benchmark; (b) demonstration of concept transfer from WEB10K to other tasks; (c) DCE, a benchmark spanning five tasks and approximately 500 concepts to evaluate GPVs; and (d) GPV-2, an architecture that supports both box and text modalities in both input and output, improves skill-concept
GPV-2 facilitates concept transfer from online data to skills, but the results also show that additional work is needed, especially for jobs like VQA or localization, which might be accomplished through new architectures or training protocols. The capacity to handle other modalities (e.g., video) and outputs (e.g., segmentation) would allow GPV-2 to serve even more tasks. Recent work in this area has shown promise, and it offers the possibility of translating principles from online data to a broader range of jobs.
Conclusion
As the vision community develops more generic models, finding efficient means to master a wide range of skills and concepts becomes increasingly important. The proposed work revisits the concept of webly-supervised learning in the context of GPVs, demonstrating that learning abilities from eight task-specific datasets and concepts from the web are a cost-effective and efficient way to expand concepts.
The code to download the Web10K dataset is on Github.
Project: https://prior.allenai.org/projects/gpv2
Paper: https://arxiv.org/pdf/2202.02317.pdf
Github: https://github.com/allenai/gpv2
Suggested

Credit: Source link
Comments are closed.