Amazon AI Researchers Propose A New Deep Learning-Based Method For Adapting An MDE Model Trained On One Labeled Dataset To Another, Unlabeled Dataset

Depth data is crucial for various robot uses, including navigation, mapping, and obstacle avoidance. Monocular depth estimation (MDE), which makes depth predictions using only a single image, can be more useful in particular situations. It is inexpensive, compact, power-efficient, and requires no calibration over its long service life.
Due to hardware and software variations, the photographs captured by various cameras look slightly different. To take advantage of a camera’s unique aesthetic qualities, an MDE model trained using photos from a single camera could use machine learning. As a result, the model’s applicability to photos captured by other cameras is questionable. The term “domain shift dilemma” describes this situation.
A new Amazon research offers a new deep-learning-based approach to transferring an MDE model trained on one labeled dataset to another unlabeled dataset. The method is based on the realization that depth cues are less influenced by aesthetics and more by the actual content of an image. Compared to state-of-the-art baselines, the proposed method averaged a 20% reduction in depth error rate and a 27% reduction in computing costs (as assessed by mean absolute cost of operation, or MAC).
Even with one eye closed, humans can infer a great degree of depth knowledge about a visual situation because of their vast store of stored information. To get similar results, the researchers emphasize that MDE must first learn the depth-related structure of objects and then extract some empirical information, which can be more sensitive to the specifics of the camera or the image settings. The depth estimate may become inaccurate when the imaging environment is altered, such as when there is less light or fog.
It’s time-consuming and expensive to gather accurate depth annotations from the ground for different cameras and lighting. Therefore, the researchers used unsupervised domain adaptation to develop an MDE model that generalizes well to the target data given a labeled source dataset and an unlabeled target dataset.
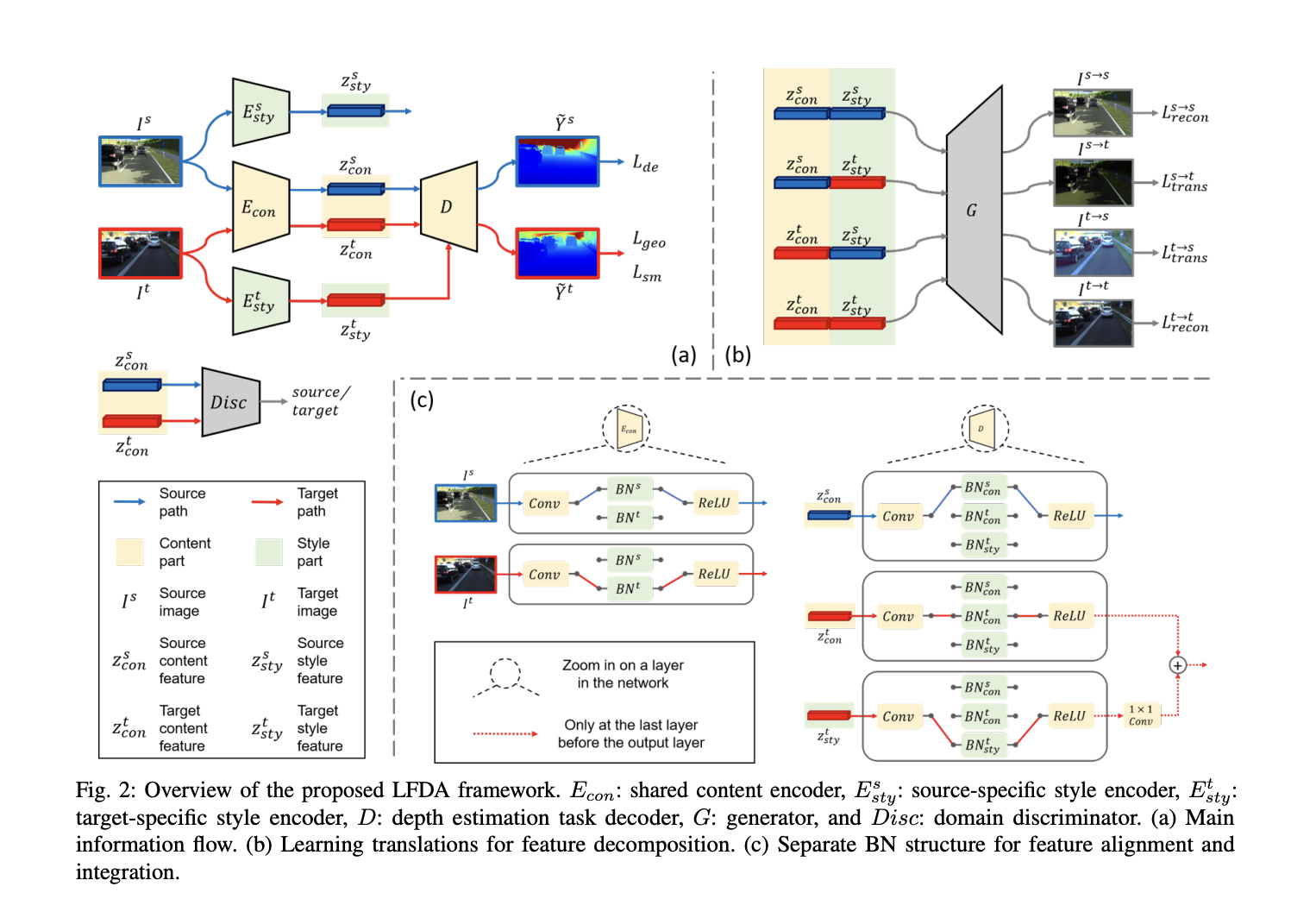
They hypothesize that the image feature space can be broken down into separate “content” and “style” layers. The semantic properties that are common between domains make up the content part. The content features of multiple domains can be more easily aligned with the help of such semantic features because they are more domain-invariant.
In contrast, the emphasis on style reflects its specialization. It may not be useful to align design elements across domains, as, for example, texture and color are specific to the sights photographed by a given camera.
To this end, they use a deep neural network with a loss function that consists of three sub-components: feature decomposition loss, feature alignment loss, and depth estimation loss.
They also trained a generator to achieve the feature decomposition loss to:
- Rebuild the original images in each dataset
- Transfer the style of one dataset to the content of the other
The feature decomposition loss takes advantage of a pretrained image recognition network’s internal representations; the network’s lower layers typically react to pixel-level image features (such as color gradations in image patches), while the network’s higher layers typically react to semantic characteristics (such as object classes).
Feature alignment loss is dependent on a secondary task, adversarial discrimination. A discriminator receives content encodings from both the source and destination datasets and attempts to distinguish which dataset the input comes from. The encoder is working to simultaneously learn embeddings that confuse the discriminator.
They use separate batch normalization during the encoding and decoding processes to better align content features. The model independently learns the source and destination data’s statistics in this method. After that, the features are standardized by the statistics of each person and aligned so that they all seem the same.
The feature decomposition loss lends more weight to the representations encoded by the network’s lower layers when comparing the styles of the generator’s outputs. When comparing the content, it gives more weight to the representations created by the network’s top layers. That way, the encoder can use embeddings that properly separate presentation from substance.
The researchers mention that the model maintains a compact structure at inference time, making it easier to implement. Also, unlike previous methods, this technique can be taught from beginning to end in a single stage, making it more convenient for deployment in real-world settings.
The researchers tested the model in three different environments: (1) cross-camera adaptation, (2) synthetic-to-real adaptation, and (3) adverse weather adaptation. According to the team, this is the first work that tries to tackle all three of these MDE task settings at once.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'Learning feature decomposition for domain adaptive monocular depth estimation'. All Credit For This Research Goes To Researchers on This Project. Check out the paper and reference article.
Please Don't Forget To Join Our ML Subreddit.
![]()
Tanushree Shenwai is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Bhubaneswar. She is a Data Science enthusiast and has a keen interest in the scope of application of artificial intelligence in various fields. She is passionate about exploring the new advancements in technologies and their real-life application.
Credit: Source link
Comments are closed.