Amazon Researchers Develop A New Way To Rewrite Database Queries To Eliminate Redundancies
This Article Is Based On The Research Paper 'Computation Reuse via Fusion in Amazon Athena'. All Credit For This Research Goes To The Researchers of This Project Please Don't Forget To Join Our ML Subreddit
As databases grow in size, queries become slower. Database queries frequently contain multiple repetitive procedures that can be eliminated. To discover a full name record in a database for a specific individual, database queries to fetch all entries for the first name, then all entries for the second name, and compute their intersection. This requires accessing the database twice, which is a duplication that can be eliminated to save data retrieval time.
Amazon researchers present a method for rewriting complicated SQL queries to eliminate redundancy. It requires more computation after retrieval but is more efficient than doing numerous queries on the same table. Testing on the TPC-DS benchmark database with 3TB of data, their approaches reduced overall execution time by 14% compared to the baseline. When they limited their analysis to queries directly changed by their rewrite rules, they saw a 60% boost in speed, with some queries processing more than six times faster.
To enhance queries, it is critical to understand what the entire query is attempting to accomplish. A query plan generates this blueprint. A query plan is a series of actions used to perform a query, such as data scans and aggregations. Selecting the most efficient query plan from a vast number of feasible possibilities is known as query plan optimization.
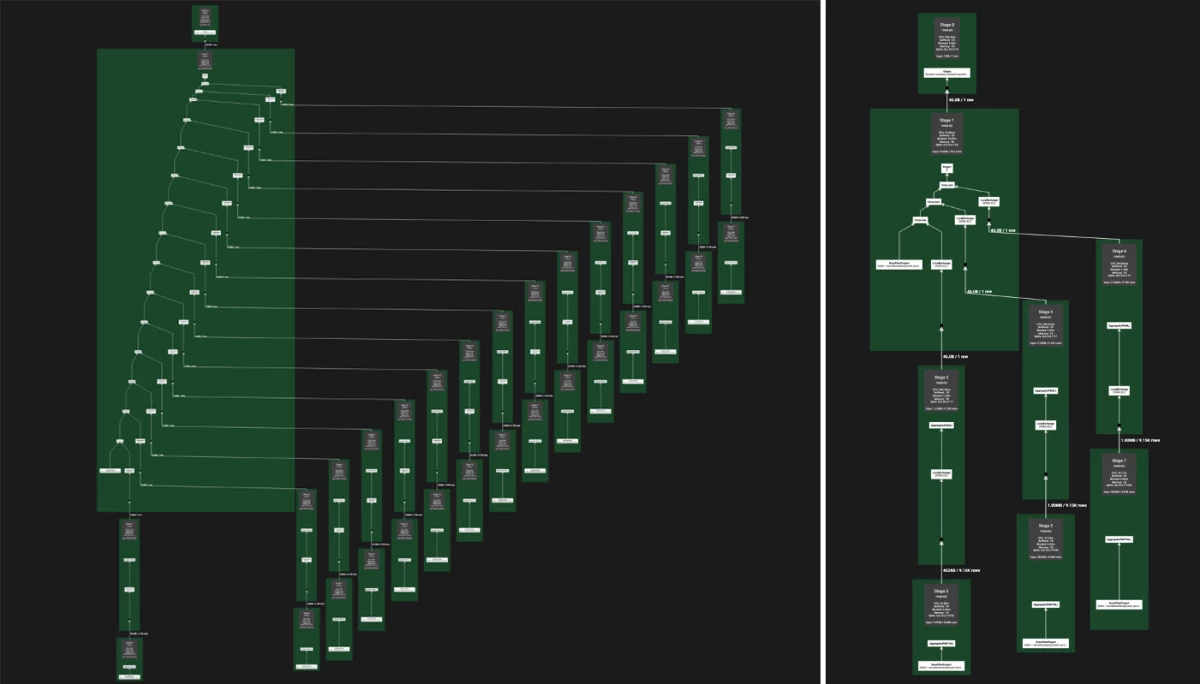
A query plan is the steps needed to run a SQL query. The figure on the left depicts the usual query strategy for a problematic query in the TPC-DS dataset. The query plan developed by the Amazon researchers’ new rewriting rules is shown on the right.
Their study identifies subqueries that compute overlapping data and fuse them into a single computation with compensatory actions (post-retrieval computations) to recover the original findings. The subqueries don’t have to be syntactically identical or give the same result.
Take the following query as an example:
WITH cte as (...complex_subquery...)
SELECT customer_id FROM cte WHERE fname="John"
UNION ALL
SELECT customer_id FROM cte WHERE lname="Smith"In the FROM clause, the query uses the block cte twice, making it inefficient, especially if the duplicated calculation is costly. Their method can detect and rewrite such patterns. For example, the preceding query becomes
WITH cte as (...complex_subquery...)
SELECT customer_id FROM cte, (VALUES (1), (2)) T(tag)
WHERE (fname="John" AND tag=1)
OR (lname="Smith" AND tag=2)Although the common expressions are not the same (there are different filter conditions in the WHERE clause), we can rewrite the query into a fragment that generates a superset of the required rows and columns and handles the differences via compensating actions.
Note that, in general, not all queries with repeated expressions can be rewritten by eliminating the duplicated work. However, beyond the query pattern shown here, several scenarios in which rewrites are applicable.
A function is the fundamental building component of this new query plan optimization. A defined function called Fuse accepts two input plans and returns either (when fusion is not achievable) or a fused 4-tuple outcome. If Fuse(P1, P2) equals (P, M, L, R),
- P is the final fused plan. P’s schema includes all output columns from P1 and possibly extra output columns from P2.
- M is a mapping from P2’s output columns to P’s output columns.
- L and R are two filter conditions set over P’s output columns to recover P1 and P2.
Fuse is a recursive function that can handle many operators such as table scan, filter, projection, join, aggregation, and distinct aggregation.
Their work has already been used in production. Although Amazon Athena benefits from it, the same approaches are adaptable to other database systems since they do not require additional operators or execution models. Customers benefit from this because their queries are executing faster, and their costs are cheaper due to less scanned data.
Source: https://www.amazon.science/blog/speeding-database-queries-by-rewriting-redundancies
Paper: https://assets.amazon.science/1b/08/6545f27b48248c08fdafb8d43055/computation-reuse-via-fusion-in-amazon-athena.pdf
Credit: Source link
Comments are closed.