Amazon Uses Machine Learning to Improve Video Quality on Prime Video

Because streaming video might be harmed by flaws introduced during recording, encoding, packing, or transmission, most subscription video services, such as Amazon Prime Video, monitor the quality of the content they stream regularly.
Manual content review, often known as eyes-on-glass testing, doesn’t scale well and comes with its own set of issues, such as discrepancies in reviewers’ quality judgments. The use of digital signal processing to detect anomalies in the video signal, which are typically associated with faults, is becoming more popular in the business.
To validate new program releases or offline modifications to encoding profiles, Prime Video’s Video Quality Analysis (VQA) division began employing machine learning three years ago to discover faults in collected footage from devices such as consoles, TVs, and set-top boxes. More recently, Amazon has used the same techniques to solve problems like real-time quality monitoring of our thousands of channels and live events, as well as large-scale content analysis.
The Amazon team at VQA trains computer vision models to watch a video and detect flaws like blocky frames, unexpected dark frames, and audio noise that could degrade the customer-watching experience. This allows Amazon to process video on a massive scale, allowing them to process hundreds of thousands of live events and catalog items.
Due to the extremely low occurrence of audiovisual errors in Prime Video offers, one fascinating difficulty they confront is a paucity of good cases in training data. The team approaches this problem by using a dataset that mimics faults in pristine content. After developing detectors using this dataset, they test them on a collection of real flaws to ensure that they transfer to production material.
Amazon has created detectors for 18 distinct types of defects, including video freezes and stutters, video tearing, audio-video synchronization issues, and caption quality concerns. Three types of faults are examined in detail below: block corruption, audio artifacts, and audiovisual synchronization issues.
One drawback of employing digital signal processing for quality analysis is that it can have difficulty discriminating between certain types of content and content with flaws. Crowd pictures or scenes with a lot of motion, for example, can appear to a signal processor as scenes with block corruption, in which poor transmission causes the displacement of blocks of pixels inside the frame or causes blocks of pixels to all to have the same color value.
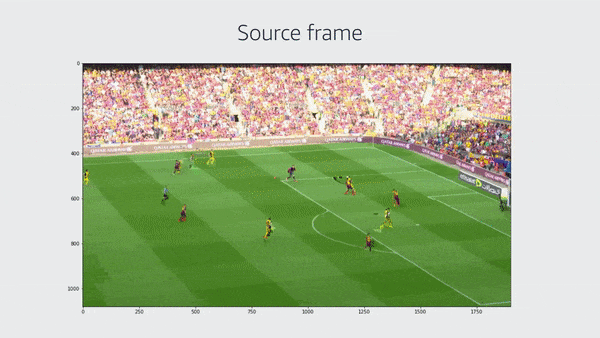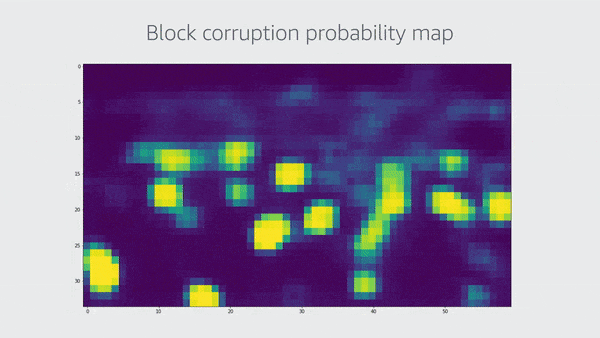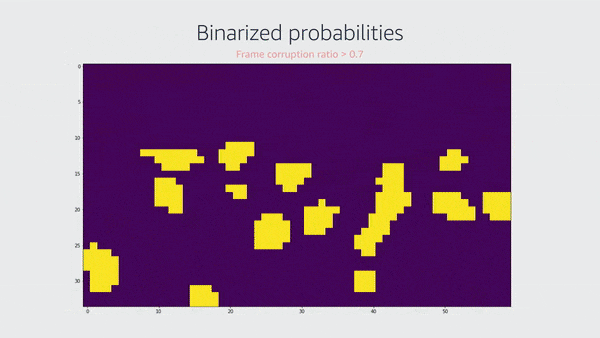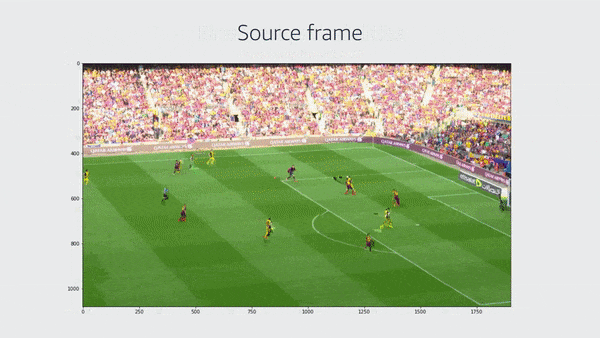
Amazon employs a residual neural network to identify block corruption, which is a network structured so that upper levels explicitly repair faults overlooked by lower layers (the residual error). A 1×1 convolution is used to replace the final layer of a ResNet18 network.
This layer produces a 2-D map, with each element representing the chance of block corruption in a specific image location. The size of the input image determines the size of this 2-D map. The team binarizes the map in the first version of this program and calculates the corrupted-area ratio. They mark the frame as having block corruption if this ratio surpasses a certain threshold.
Unwanted sounds in the audio stream are known as “audio artifacts,” and they can be created during the recording process or during data compression. This is the audio equivalent of a corrupted block in the latter situation. However, artifacts are occasionally used for creative purposes.
Amazon utilizes a no-reference model to detect audio artifacts in video, which means it doesn’t have access to clear audio as a baseline of comparison during training. A one-second audio segment is classified as no defect, audio hum, audio hiss, audio distortion, or audio clicks by the model, which is based on a pretrained audio neural network.
On Amazon’s proprietary simulated dataset, the model currently achieves a balanced accuracy of 0.986. Their paper “A no-reference model for detecting audio artifacts using pretrained audio neural networks,” which was presented at the IEEE Winter Conference on Applications of Computer Vision, contains more information on the model.

Another typical quality issue is the AV sync or lip-sync flaw, which occurs when the audio and video are not in sync. Audio and video can become out of sync due to problems with transmitting, reception, and replay.
The Amazon team created LipSync, a detector based on the SyncNet architecture from the University of Oxford, to detect lip-sync errors.
A four-second video segment is fed into the LipSync pipeline. It then goes to a shot detection model, which recognizes shot borders; a face detection model that recognizes the faces in each frame; and a face-tracking model that identifies faces in subsequent frames as belonging to the same person.
The SyncNet model takes the face-tracking model’s outputs (known as face tracks) and the linked audio and decides whether the clip is in sync, out of sync, or inconclusive, which means there are either no faces/facial tracks detected or an equal amount of in-sync and out-of-sync predictions.
Future work
These are just a few of the detectors Amazon has on hand. They will continue to refine and improve the algorithms in 2022. They’re constantly retraining the deployed models using active learning, which algorithmically selects particularly informative training samples.
EditGan, a new approach that permits more precise control over the outputs of generative adversarial networks, is being investigated to produce synthetic datasets (GANs). They’re also scaling the flaw detectors and monitoring all live events, and video feeds using our bespoke AWS cloud-native applications and SageMaker implementations.
Source: https://www.amazon.science/blog/how-prime-video-uses-machine-learning-to-ensure-video-quality
Suggested
Credit: Source link
Comments are closed.