Amazon’s 20B-Parameter Alexa Model Sets New Marks In Few-Shot Learning Along With Low Carbon Footprint During Training (One-Fifth of GPT-3’s)
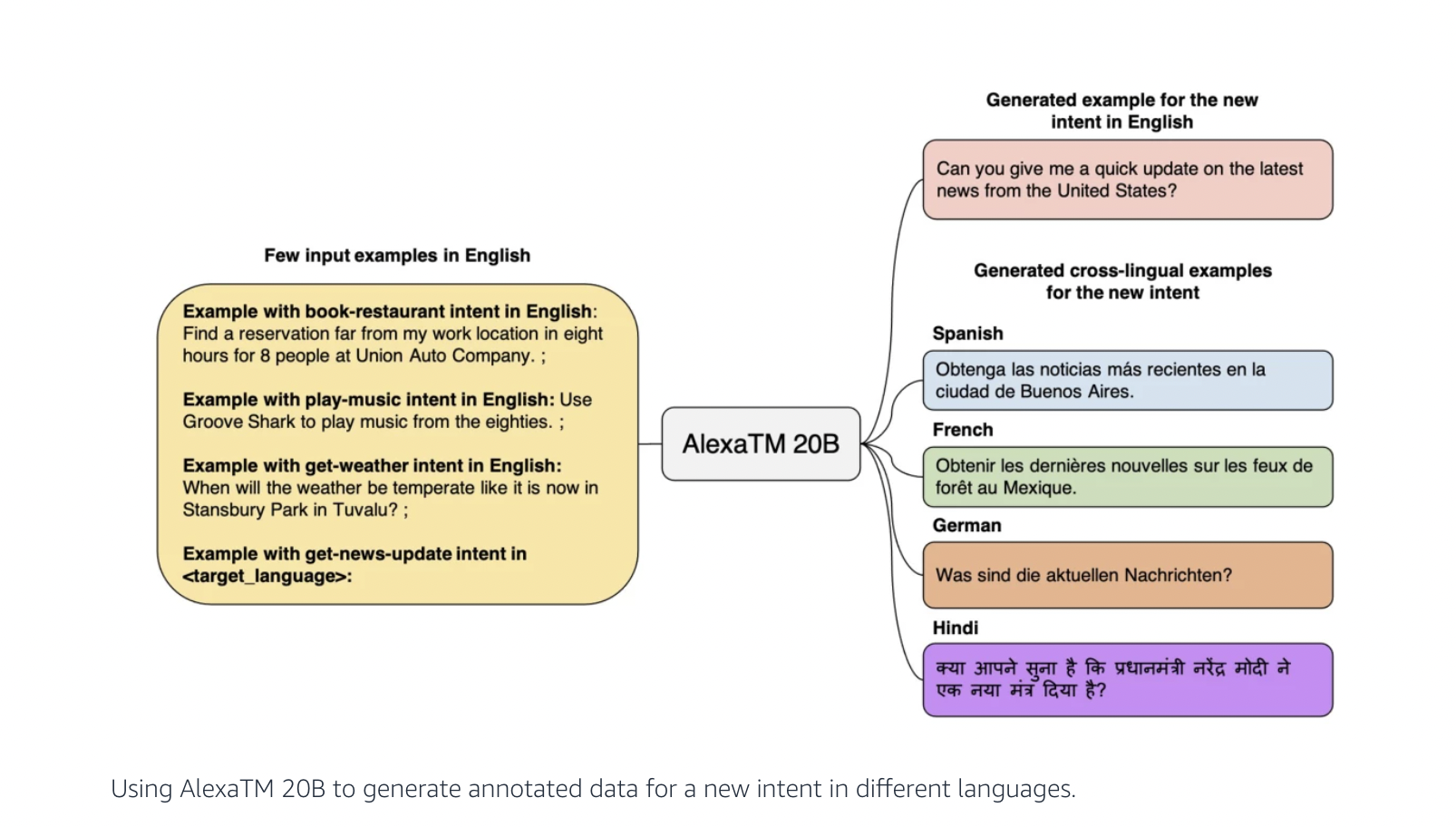
Some of the most significant developments in AI have come through supervised learning. It speaks about computer learning models that have been trained using annotated data. However, reliance on data annotation is increasingly untenable as the size of commercial AI models grows. The new paradigm of generalizable intelligence, in which models can pick up new ideas and transfer knowledge from one language or task to another without much human input, is being investigated by researchers at Alexa AI. These models enable researchers to create new features and enhance Alexa across several languages quickly. As part of this change, Amazon has introduced Alexa Teacher Models (AlexaTM), which are massive transformer-based multilingual language models. Without additional human guidance, AlexaTM can learn a task in a new language with just a few instances and pick it up quickly.
The team recently published a paper that was also presented at the Knowledge Discovery and Data Mining Conference (KDD). They demonstrated how AlexaTM models with ten billion and two billion parameters could outperform current cross-lingual transfer learning techniques and boost Alexa’s accuracy in various regions. The team has advanced their study with a 20-billion-parameter generative model called AlexaTM 20B in a companion publication that will be released soon. The studies described in the study, which only employ publicly available data, demonstrate that AlexaTM 20B can learn new tasks from a small number of instances and transfer what it learns across languages (few-shot learning). The recent work of OpenAI and the creation of the GPT-3 model served as inspiration for the team’s effort. The AlexaTM 20B model differs from other big language models because it uses a sequence-to-sequence (seq2seq) encoder-decoder architecture.
In an encoder-decoder architecture, the encoder employs bidirectional encoding to create a representation of an input text. At the same time, the decoder makes use of that representation to carry out operations like translating the input. The input text is encoded left-to-right (unidirectionally) in the decoder-only model. This is successful for language modeling, where the goal is to predict the subsequent token in a sequence based on the previous ones, but less so for text summarization and machine translation, which are the tasks on which AlexaTM 20B outperforms GPT-3. The linguistic capabilities of AlexaTM 20B place it above GPT-3. Additionally, it has a training carbon footprint of only one-fifth that of GPT-3. A combination of denoising and causal-language-modeling (CLM) tasks were used to train AlexaTM 20B. The model must identify dropped spans and produce the complete version of the input for the denoising operation. The model must continue the input text meaningfully for the CLM task. This is comparable to the training of decoder-only models like GPT-3 and PaLM. Other seq2seq models like T5 and BART are trained in a manner akin to this. AlexaTM 20B can generalize based on the input and generate new text (the CLM task) after training on both pretraining tasks. It also excels at tasks at which seq2seq models are powerful, like summarising and machine translation.
The biggest multilingual seq2seq model with few-shot learning to date is AlexaTM 20B. Amazon also intends to make the model available to the general public for non-commercial use to support the creation and assessment of multilingual big language models (LLMs). The team also discovered that AlexaTM 20B, like previous LLMs, had a chance to repeat damaging stereotypes, poisonous language, and social biases in its training data. In order to properly understand and resolve any potential harm that might result from the model’s use, it is advised that users do a comprehensive task-specific fairness-and-bias study before utilizing it.
In conclusion, the researchers developed a pretraining method that allows seq2seq models to beat much bigger decoder-only LLMs on various tasks, both in a few-shot scenario and with fine-tuning. In their effort, Amazon hopes to make a strong argument for seq2seq models as a potent substitute for decoder-only models for LLM training.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'Alexa teacher model: Pretraining and distilling multi-billion-parameter encoders for natural language understanding systems'. All Credit For This Research Goes To Researchers on This Project. Checkout the paper and reference article from Amazon. Please Don't Forget To Join Our ML Subreddit
![]()
Khushboo Gupta is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Goa. She is passionate about the fields of Machine Learning, Natural Language Processing and Web Development. She enjoys learning more about the technical field by participating in several challenges.
Credit: Source link
Comments are closed.