An MIT Research Develops A New Machine Learning Model That Understands The Underlying Relationships Between Objects In A Scene

Deep learning models do not see the world the same way we humans do. Humans have the ability to see objects and interpret their relationships. However, DL models don’t comprehend the complex interactions between individual objects.
To address this issue, researchers from MIT have developed a machine learning approach that understands the underlying relationships between objects in a scene. Firstly, this model illustrates individual relationships one at a time. Then it combines them to describe the complete picture.
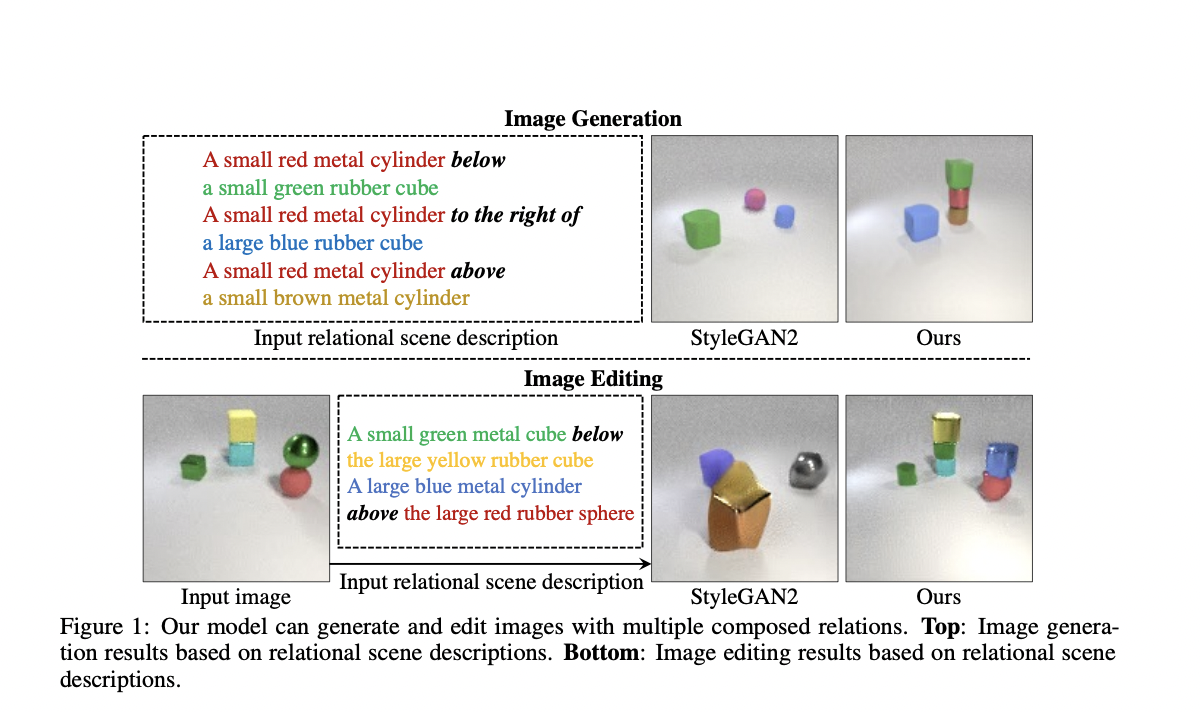
The new framework creates an image of a scene based on a text description of objects and their connections, such as “A wood table to the left of a blue stool.”
To accomplish this, it first breaks these words down into two smaller parts, one for each specific relationship (for example, “a wood table to the left of a blue stool”), and then model each part independently. After that, an optimization method is used to assemble the components, resulting in a scene image. Even when the scene contains several items in varying relationships, the model can build more accurate images from text descriptions.
Most DL systems would consider all relationships holistically and generate the image from the description in a single step. However, these models fail when dealing with out-of-distribution descriptions, such as those including more relations. This is due to the fact that these models can’t actually adopt one shot to generate images with more relationships. According to researchers, their model can simulate a higher number of linkages and adapt to unexpected combinations because it combines these different, smaller models.
To capture the individual object associations in a scene description, the researchers employed a machine-learning technique called energy-based models. Using this model, the method encodes each relational description and then compiles them together, inferring all objects and relationships.
The system can also recombine the lines in a variety of ways by splitting them down into shorter chunks for each relationship, making it better able to adapt to scene descriptions it hasn’t seen before.
What’s more interesting is that the method can also work in reverse, finding text descriptions that fit the relationships between elements in a scene given an image. Furthermore, their model can also alter an image by rearranging the scene’s elements to fulfill a new description.
When evaluated with other DL models while they were given text descriptions and instructed to create visuals depicting the objects and their interactions, the proposed model outperformed the baselines in each case.
Humans were also asked to assess if the generated photos matched the scene description. About 91 percent of participants concluded that the new model performed better in the most challenging situations, where descriptions had three linkages.
When the system is given two related scene descriptions that depicted the same image in various ways, the model is able to recognize that they were equivalent. Researchers state that even when they increase the number of relation descriptions in the phrase from one to two, three, or even four, their approach continues to generate images that are appropriately described by those descriptions, while other methods fail.
This algorithm has the ability to learn from fewer data points while generalizing to more complicated scenarios or image creations. It finds application in real-world situations where robots must perform complex, multistep manipulation tasks. Above everything, this research is highly promising because it moves the field closer to enabling machines to learn from and interact with their environment in the same way humans do.
In the future, the researchers plan to examine how their model performs on more complex real-world photos, such as those with noisy backgrounds and objects that are blocking one another. They also hope to incorporate their model into robotics systems in the future, allowing a robot to deduce item relationships from videos and then use that information to manipulate objects in the real world.
Paper: https://arxiv.org/pdf/2111.09297.pdf
GitHub: https://composevisualrelations.github.io/
Reference: https://news.mit.edu/2021/ai-object-relationships-image-generation-1129
Suggested

Credit: Source link
Comments are closed.