Apple ML Researchers Introduce ‘MobileViT’: A Light-Weight And General-Purpose Vision Transformer For Mobile Devices
To learn visual representations, self-attention-based models, particularly vision transformers, offer an alternative to convolutional neural networks (CNNs). ViT breaks an image into a series of non-overlapping patches and then uses multi-headed self-attention in transformers to learn interpatch representations. The typical trend in ViT networks is to increase the number of parameters to improve performance.
These gains in performance come at the expense of model size (network parameters) and latency. Many real-world applications (such as augmented reality and autonomous wheelchairs) necessitate the timely execution of visual recognition tasks (such as object detection and semantic segmentation) on resource-constrained mobile devices.
ViT models for such jobs should be light-weight and quick to be effective. ViT models’ performance is much inferior to light-weight CNNs, even when the model size is reduced to fit the resource limits of mobile devices. DeIT, for example, is 3% less accurate than MobileNetv3 for a parameter budget of roughly 5-6 million. As a result, designing light-weight ViT models is critical.
Many mobile vision tasks have been powered by light-weight CNNs. ViT-based networks, on the other hand, are still a long way from being utilized on such devices. Unlike light-weight CNNs that are simple to optimize and integrate with task-specific networks, ViTs are large (e.g., ViT-B/16 vs. MobileNetv3: 86 vs. 7.5 million parameters), difficult to optimize, require extensive data augmentation and L2 regularisation to avoid over-fitting, and require expensive decoders for downstream tasks, particularly dense prediction tasks.
The lack of image-specific inductive bias, which is inherent in CNNs, is likely the reason for the requirement for more parameters in ViT-based models. Hybrid techniques that mix convolutions and transformers are gaining popularity as a way to develop durable and high-performing ViT models. These hybrid models, however, are still hefty and susceptible to data augmentation. Remove CutMix and DeIT-style data augmentation, for example, and ImageNet accuracy plummets (78.1 percent to 72.4 percent ).
Combining the strengths of CNNs with transformers to develop ViT models for mobile vision tasks is still a work in progress. Mobile vision activities necessitate light-weight, low-latency, and accurate models that meet the device’s resource limits while also being general-purpose enough to be used for a variety of applications (e.g., segmentation and detection). FLOPs aren’t enough for low latency on mobile devices since they overlook various essential inference-related elements like memory access, parallelism, and platform characteristics.

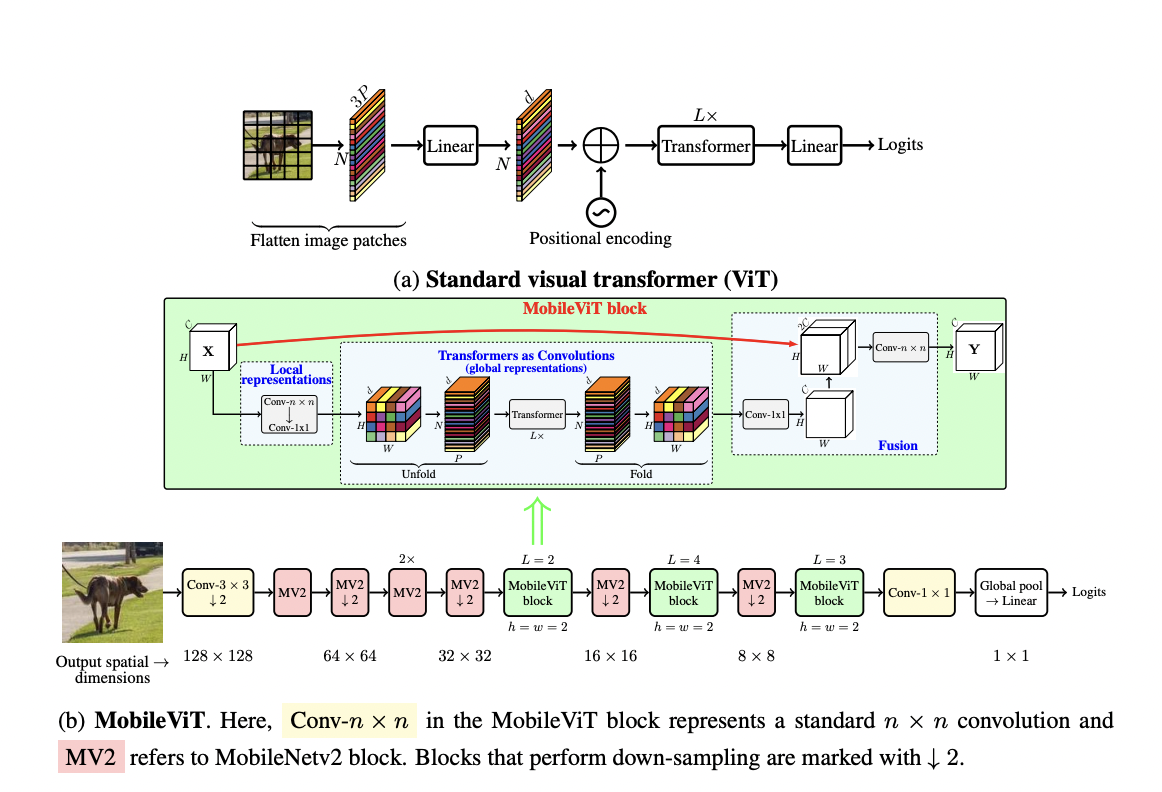
In a recent publication, Apple researchers focus on creating a light-weight, general-purpose, and low-latency network for mobile vision applications rather than optimizing for FLOPs1. MobileViT, which combines the benefits of CNNs (e.g., spatial inductive biases and decreased susceptibility to data augmentation) with ViTs, achieves this purpose (e.g., input-adaptive weighting and global processing). They introduce the MobileViT block, which successfully encodes both local and global information in a tensor.
MobileViT, in contrast to ViT and its derivatives (with and without convolutions), takes a different approach to learning global representations. Unfolding, local processing, and folding are the three steps of standard convolution. In convolutions, the MobileViT block substitutes local processing with global processing via transformers. This gives the MobileViT block CNN and ViT-like features, allowing it to learn better representations with fewer parameters and simpler training recipes (e.g., basic augmentation).
This is the first study to show that light-weight ViTs can attain light-weight CNN-level performance across a variety of mobile vision tasks using basic training recipes. MobileViT achieves a top-1 accuracy of 78.4 percent on the ImageNet-1k dataset for a parameter budget of roughly 5-6 million, which is 3.2 percent higher than MobileNetv3 and has a simple training recipe (MobileViT vs. MobileNetv3: 300 vs. 600 epochs; 1024 vs. 4096 batch size). When MobileViT is employed as a feature backbone in highly optimized mobile vision task-specific designs, researchers see significant performance increases. MNASNet was replaced as the feature backbone in SSDLite with MobileViT, which resulted in a superior (+1.8 percent mAP) and smaller (1.8) detection network.
Conclusion
On mobile devices, researchers have discovered that MobileViT and other ViT-based networks (such as DeIT and PiT) are slower than MobileNetv2. This finding contradicts prior research that found ViTs to be more scalable than CNNs. This disparity is mostly due to two factors. To begin, dedicated CUDA kernels for transformers on GPUs exist, which are used out-of-the-box in ViTs to boost scalability and efficiency on GPUs. Second, numerous device-level enhancements, such as batch normalization fusion with convolutional layers, boost CNNs.
These enhancements reduce latency and improve memory access. Mobile devices, on the other hand, do not currently support such specialized and optimized transformer operations. As a result, the MobileViT and ViT-based networks’ inference graph for mobile devices is sub-optimal. Similar to CNNs, the team anticipates that the inference speed of MobileViT and ViTs will improve in the future with dedicated device-level operations.
Paper: https://arxiv.org/pdf/2110.02178.pdf
Github: https://github.com/apple/ml-cvnets
Suggested
Credit: Source link
Comments are closed.