Apple ML Researchers Propose A Self-Supervised Method For Learning Representations of Geographic Locations From Unlabeled GPS Trajectories to Solve Downstream Geospatial Computer Vision Tasks
Graphs are fundamental data structures in many fields spanning vast applications, be it recommendation systems, communication, social, or biological networks. Road networks, point clouds, and 3D object models are a few examples of geospatial information that may be organically represented as graphs with naturally occurring nodes and edges. For graph analysis, machine learning algorithms need feature vector representations of the nodes, edges, substructures, or entire graph. Recent techniques have concentrated on automatically learning low-dimensional, feature vector representations of graphs (graph embeddings) and their constituent parts instead of manually creating task- and domain-specific features (e.g., node embeddings).
A key idea in graph theory is the reachability of one node to another. Self-supervised learning (SSL), a topic of ongoing study, has demonstrated promising results in computer vision and natural language processing (NLP) applications. SSL frequently employs predetermined pretext tasks to generate supervision signals directly from unlabeled data by training neural networks to anticipate concealed sections or attributes of inputs, bypassing the requirement for massive, clean, labeled datasets, which are costly to prepare in terms of both time and money. SSL aims to learn task-independent, semantically meaningful data representations that can be used as inputs by subsequent (typically supervised) task-specific models.
For NLP applications, context-independent, context-relevant, task-agnostic word embeddings have been learned using SSL. The most common SSL techniques for learning visual representations can be divided into two categories: generative approaches that learn representations while generating images by modeling the data distribution -, and discriminative approaches that use pretext tasks designed to produce labels for inputs quickly (for example, based on heuristics – or contrastive learning,), coupled with a supervised objective.
Self-supervised representation learning approaches use large datasets without semantic annotations to learn universal features that can be easily transferred to perform a range of downstream supervised tasks. In order to complete geospatial computer vision tasks in the future, they propose in this study a self-supervised approach for learning representations of geographic places using unlabeled GPS trajectories. Raster representations of the earth’s surface result in tiles that may be characterized as network nodes or picture pixels. On these nodes, GPS trajectories are described as permissible Markovian routes.
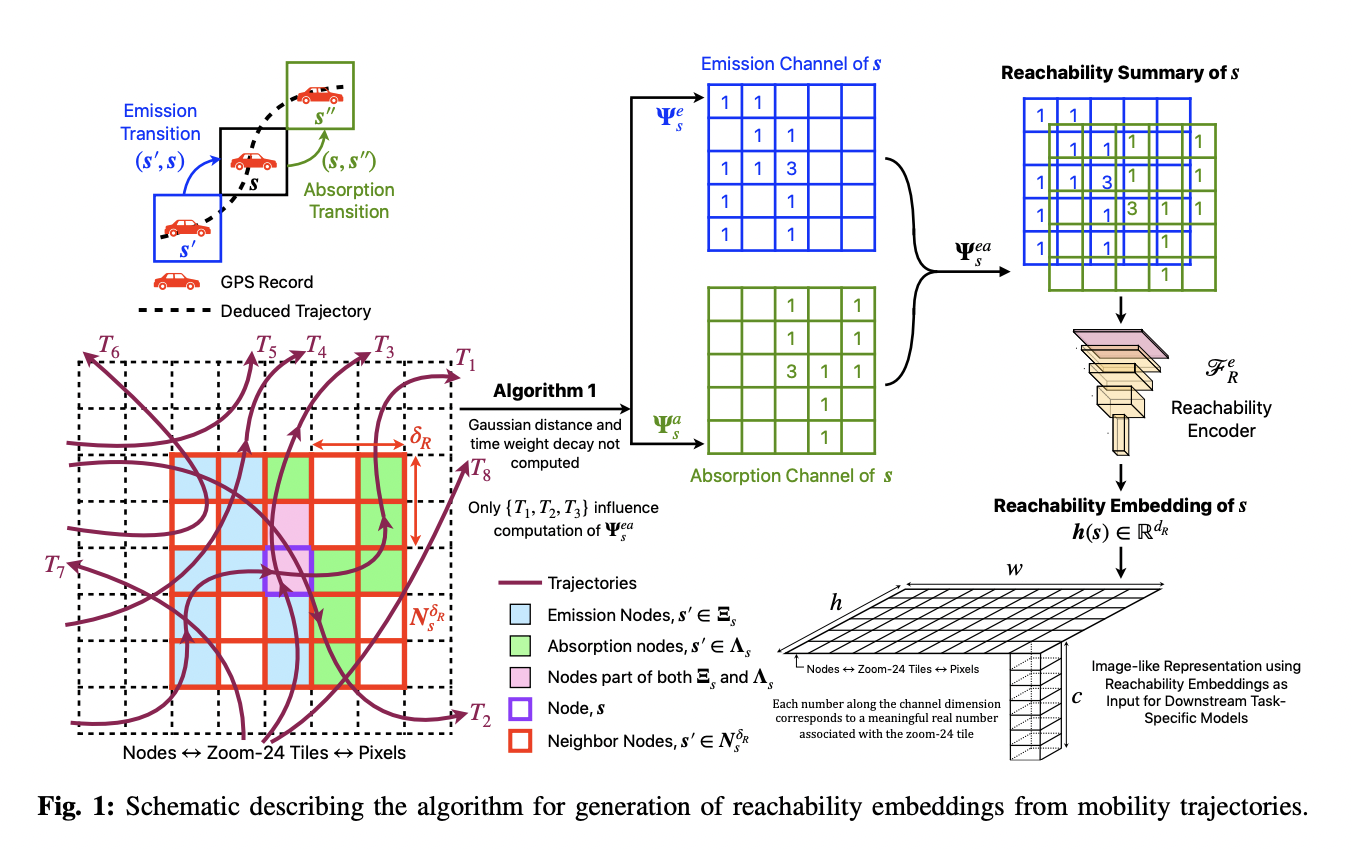
They describe a distributed and scalable technique to calculate reachability summaries. Reachability summaries for each tile are compressed into representations known as reachability embeddings, which a convolutional, contractive autoencoder is taught to learn. These are image-like tensor representations of the spatial connectivity patterns between tiles and their neighbors inferred by the observed Markovian routes. As task-independent feature representations of geographic places, reachability embeddings are helpful.
The spatial connection patterns between tiles and their neighbors suggested by the observed Markovian routes are computed using a scalable and distributed approach to provide reachability summaries, which are image-like tensor representations. In order to learn compressed representations of the reachability summaries for each tile, a convolutional, contractive autoencoder is trained. As task-independent feature representations of geographic places, reachability embeddings are used.
The problem of alignment and fusion in multimodal learning is addressed through the invention of reachability embeddings as pixel representations. Compared to unimodal models for the same tasks, multimodal modeling of three separate downstream geospatial tasks that include data from road network graphs, mobility trajectories, and satellite images results in 2-4 percent performance gains.
Reachability embeddings are intended to support multimodal learning in geospatial computer vision by transforming sequential, spatiotemporal motion trajectory data into semantically significant, image-like tensor representations that can be combined with other data modalities that are (e.g., satellite imagery) or can be transformed (e.g., road network graph, SAR imagery).
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'Reachability Embeddings: Scalable Self-Supervised Representation Learning from Mobility Trajectories for Multimodal Geospatial Computer Vision'. All Credit For This Research Goes To Researchers on This Project. Check out the paper. Please Don't Forget To Join Our ML Subreddit
![]()
Content Writing Consultant Intern at Marktechpost.
Credit: Source link
Comments are closed.