Apple Researchers Introduce ByteFormer: An AI Model That Consumes Only Bytes And Does Not Explicitly Model The Input Modality
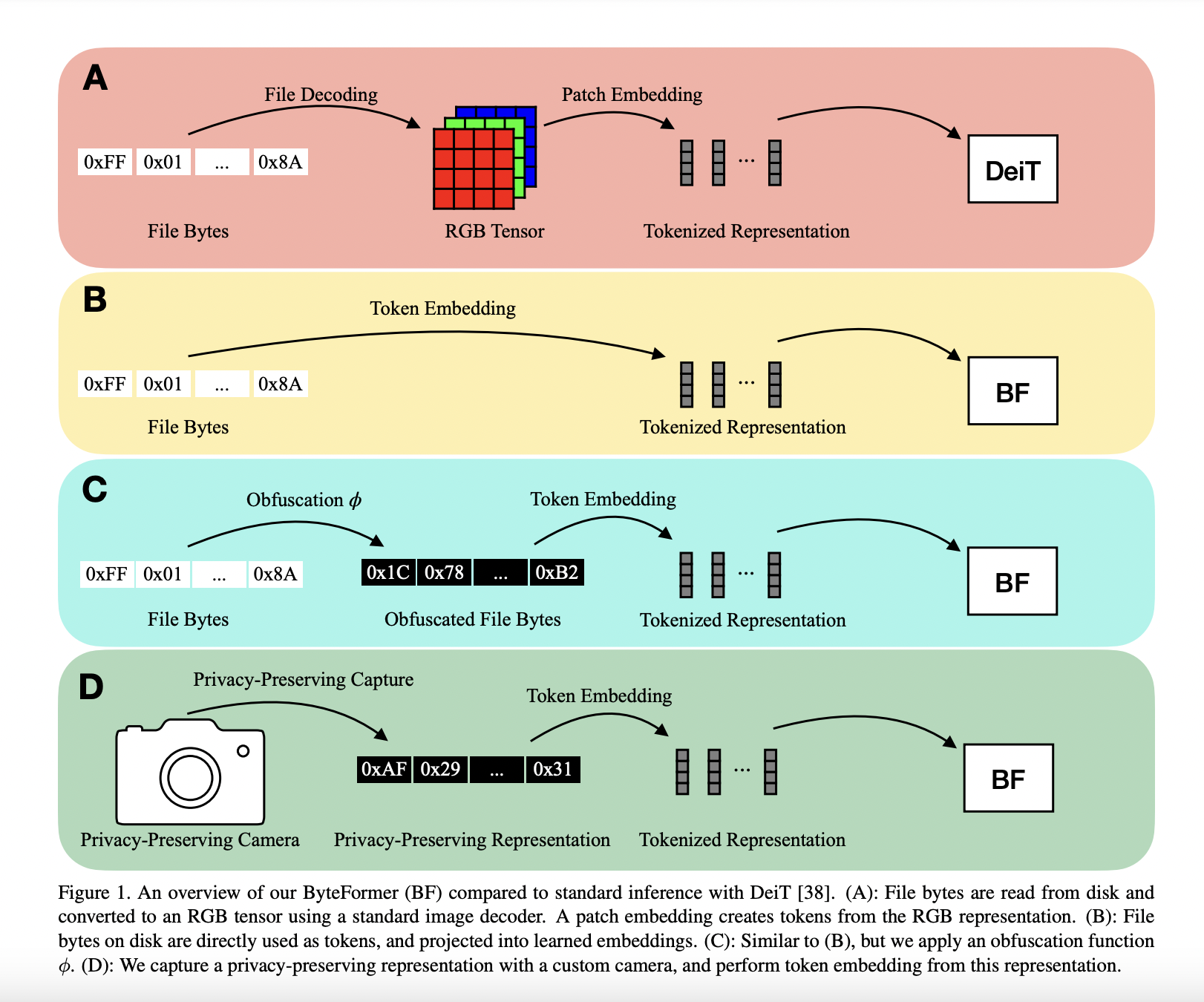
The explicit modeling of the input modality is typically required for deep learning inference. For instance, by encoding picture patches into vectors, Vision Transformers (ViTs) directly model the 2D spatial organization of images. Similarly, calculating spectral characteristics (like MFCCs) to transmit into a network is frequently involved in audio inference. A user must first decode a file into a modality-specific representation (such as an RGB tensor or MFCCs) before making an inference on a file that is saved on a disc (such as a JPEG image file or an MP3 audio file), as shown in Figure 1a. There are two real downsides to decoding inputs into a modality-specific representation.
It first involves manually creating an input representation and a model stem for each input modality. Recent projects like PerceiverIO and UnifiedIO have demonstrated the versatility of Transformer backbones. These techniques still need modality-specific input preprocessing, though. For instance, before sending picture files into the network, PerceiverIO decodes them into tensors. Other input modalities are transformed into various forms by PerceiverIO. They postulate that executing inference directly on file bytes makes it feasible to eliminate all modality-specific input preprocessing. The exposure of the material being analyzed is the second disadvantage of decoding inputs into a modality-specific representation.
Think of a smart home gadget that uses RGB photos to conduct inference. The user’s privacy may be jeopardized if an enemy gains access to this model input. They contend that deduction can instead be carried out on inputs that protect privacy. They make notice that numerous input modalities share the ability to be saved as file bytes to solve these shortcomings. As a result, they feed file bytes into their model at inference time (Figure 1b) without doing any decoding. Given their capability to handle a range of modalities and variable-length inputs, they adopt a modified Transformer architecture for their model.
Researchers from Apple introduce a model known as ByteFormer. They use data stored in the TIFF format to show the effectiveness of ByteFormer on ImageNet categorization, attaining a 77.33% accuracy rate. Their model uses the DeiT-Ti transformer backbone hyperparameters, which achieved 72.2% accuracy on RGB inputs. Additionally, they provide excellent outcomes with JPEG and PNG files. Further, they show that without any modifications to the architecture or hyperparameter tweaking, their classification model can reach 95.8% accuracy on Speech Commands v2, equivalent to state-of-the-art (98.7%).
They can also utilize ByteFormer to work on inputs that maintain privacy because it can handle several input forms. They show that they can disguise inputs without sacrificing accuracy by remapping input byte values using the permutation function ϕ : [0, 255] → [0, 255] (Figure 1c). Even though this does not ensure cryptography-level security, they show how this approach may be used as a foundation for masking inputs into a learning system. By using ByteFormer to make inferences on a partly generated picture, it is possible to achieve greater privacy (Figure 1d). They show that ByteFormer can train on images with 90% of the pixels obscured and achieve an accuracy of 71.35% on ImageNet.
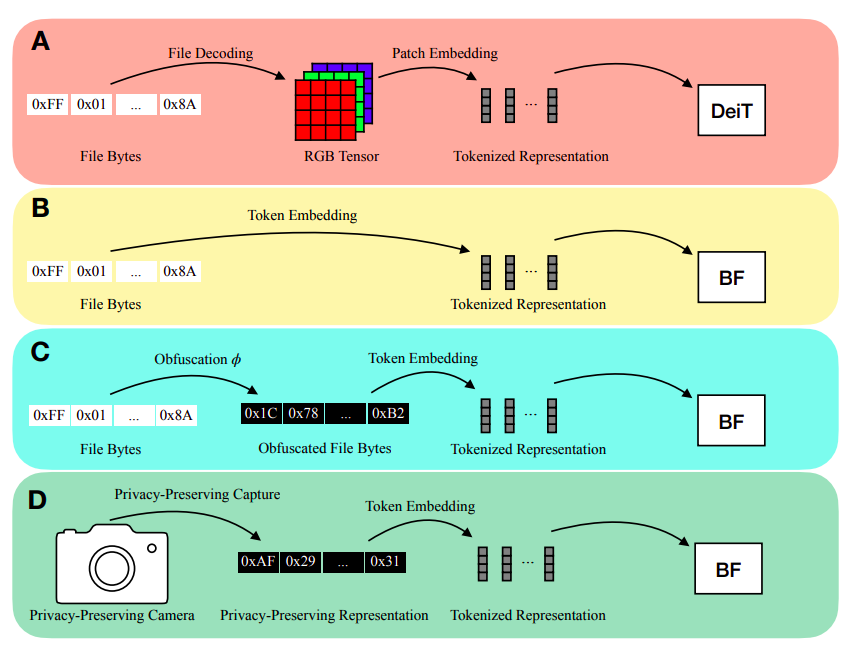
Knowing the precise location of unmasked pixels to use ByteFormer is unnecessary. By avoiding a typical image capture, the representation given to their model ensures anonymity. Their brief contributions are: (1) They create a model called ByteFormer to make inferences on file bytes. (2) They demonstrate that ByteFormer performs well on several picture and audio file encodings without requiring architectural modifications or hyperparameter optimization. (3) They give an example of how ByteFormer may be used with inputs that protect privacy. (4) They look at the characteristics of ByteFormers that have been taught to categorize audio and visual data straight from file bytes. (5) They publish their code on GitHub as well.
Check Out The Paper. Don’t forget to join our 23k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.