Apple Researchers Propose A Method For Reconstructing Training Data From Diverse Machine Learning Models By Ensemble Inversion
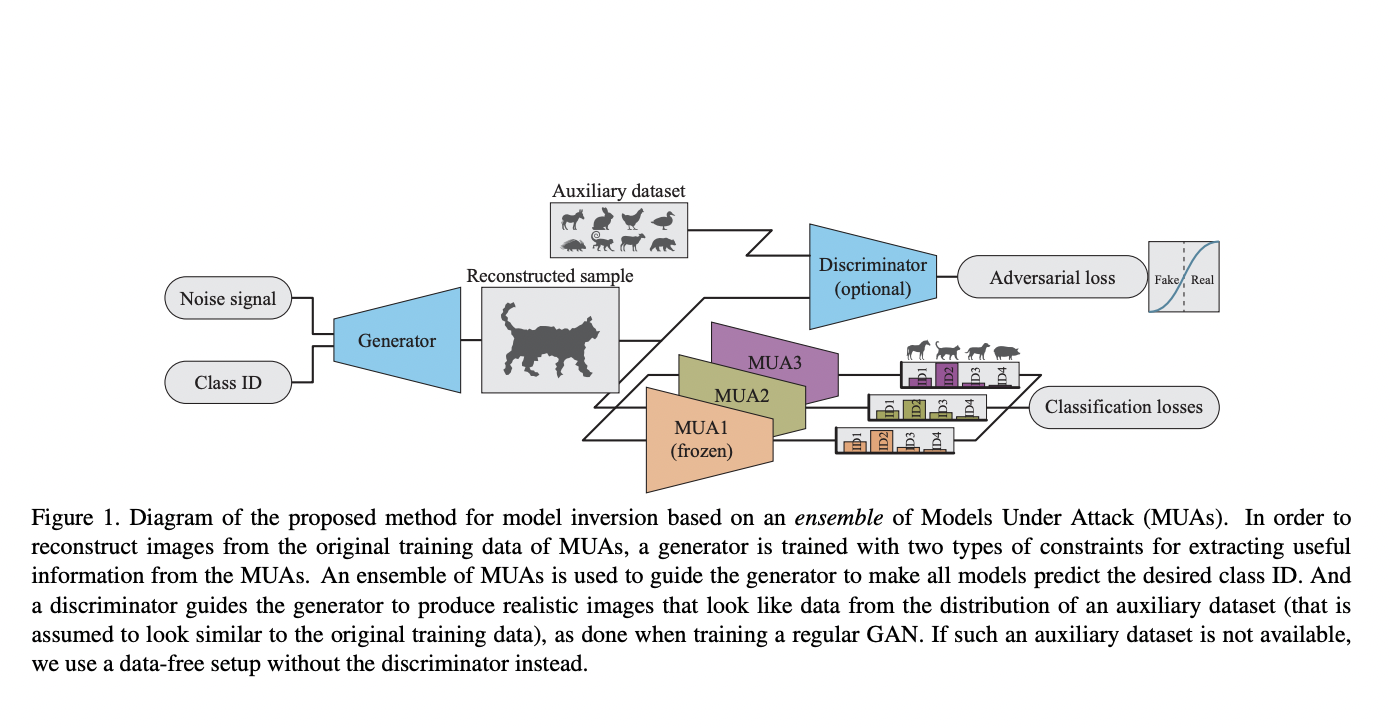

Model inversion (MI), where an adversary abuses access to a trained Machine Learning (ML) model in order to infer sensitive information about the model’s original training data, has gotten a lot of attention in recent years. The trained model under assault is frequently frozen during MI and used to direct the training of a generator, such as a Generative Adversarial Network, to rebuild the distribution of the model’s original training data.
As a result, scrutiny of the capabilities of MI techniques is essential for the creation of appropriate protection techniques. Reconstruction of training data with high quality using a single model is complex. However, existing MI literature does not consider targeting many models simultaneously, which could offer the adversary extra information and viewpoints. If successful, this could result in the disclosure of original training samples, putting the privacy of dataset subjects in jeopardy if the training data contains Personally Identifiable Information.
Apple researchers have presented an ensemble inversion technique that uses a generator restricted by a set of trained models with shared subjects or entities to estimate the distribution of original training data. When compared to MI of a single ML model, this technique results in considerable improvements in the quality of the generated samples with distinguishing properties of the dataset entities. Without any dataset, high-quality results were obtained, demonstrating how using an auxiliary dataset similar to the expected training data improves the outcomes. The impact of model diversity in the ensemble is examined in-depth, and extra constraints are used to encourage sharp predictions and high activations for the rebuilt samples, resulting in more accurate training picture reconstruction.
When compared to attacking a single model, the model shows a significant improvement in reconstruction performance. The effects of model diversity on ensemble inversion performance were investigated, and the farthest model sampling (FMS) method was employed to optimize model diversity in a collected ensemble. The model creates an inversion ensemble and determines a class correspondence between various models. The model output vector’s enhanced information was used to generate better restrictions for distinguishing qualities of the target identities.
Using stochastic training techniques like SGD with mini-batches, mainstream DCNNs can be trained on arbitrarily large training data sets. As a result, DCNN models are sensitive to the training dataset’s initial random weights and statistical noise. Because of the stochastic nature of learning algorithms, different versions of models are created, each of which focuses on distinct features despite being trained on the same dataset. As a result, to reduce variance, researchers typically use ensemble learning, which is a simple technique to improve the results of discriminatively trained DCNNs.

Ensemble learning is a source of inspiration for this study; however, the concept of the ensemble is distinct. In order to do a model inversion, attackers cannot presume that the models under attack have always been trained using ensemble learning. They may, however, be able to collect connected models in order to build an attack ensemble. In other words, the ensemble in the context of the ensemble inversion attack refers to a collection of correlated models that attackers can gather from a variety of sources without requiring that the collected models have been trained using ensemble learning. Researchers or organizations, for example, will continue to get new training data and train and disseminate updates to current models, which may be gathered and utilized as an ensemble by an attacker.
When the proposed strategies are used, the MNIST digit reconstruction accuracy improves by 70.9 percent for the data-free experiment and 17.9 percent for the auxiliary data-based trial. Over the baseline experiment, the accuracy of face reconstruction has been enhanced by 21.1 percent. The goal of this study is to conduct a systemic examination of the presented strategies’ possible impact on model inversion. The development of corresponding protection mechanisms against such ensemble inversion attacks will be the focus of future versions.
Conclusion
The ensemble inversion technique is proposed in the study, which takes advantage of the variety of an ensemble of ML models to improve model inversion performance. In addition, one-hot loss and maximum output activation loss are incorporated, resulting in an even higher level of sample quality. Meanwhile, filtering out generated samples with low maximum activations of the attacked models can help the reconstructions stand out even more. Furthermore, frequent scenarios for getting target model variance are explored and thoroughly investigated in order to determine how to target model diversity affects ensemble inversion performance.
Paper: https://arxiv.org/pdf/2111.03702.pdf
Suggested

Credit: Source link
Comments are closed.