Are Large Language Models Really Good at Generating Complex Structured Data? This AI Paper Introduces Struc-Bench: Assessing LLM Capabilities and Introducing a Structure-Aware Fine-Tuning Solution
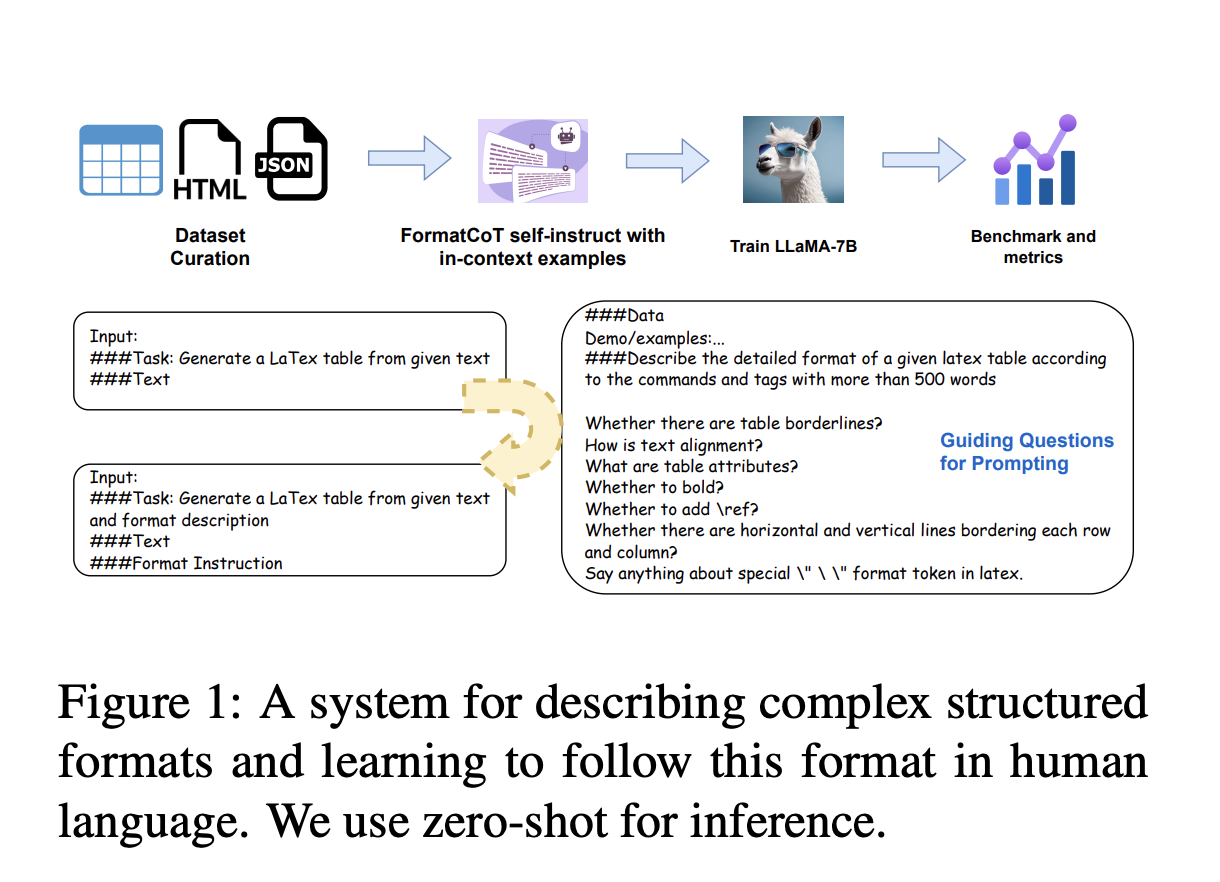
Large Language Models (LLMs) have made significant progress in text creation tasks, among other natural language processing tasks. One of the fundamental components of generative capability, the capacity to generate structured data, has drawn much attention in earlier research. However, LLMs continue to do poorly in producing complicated structured outputs a crucial skill for various applications, from automated report authoring to coding help. Furthermore, relatively little research has been done to assess LLMs’ capacity to produce structured output; most evaluations of LLMs have focused on spontaneous text or code development. This raises the question of how well LLMs can make complicated structured data.
Researchers from Yale University, Zhejiang University, New York University, and ETH Zurich aim to give a thorough analysis and address these open questions in their work. First, more comprehensive research on LLMs’ ability to create complex structured data needs to be done. Prior attempts to evaluate LLMs on structured data concentrated on simple Information Extraction (IE) tasks, such as extracting relations, recognizing events, and identifying named entities. In this instance, the IE tasks’ goal is to gather the extracted data in a well-ordered manner. Older work was significantly more task-centric compared to LLM-centric work. Using pre-trained models like BART and T5, which produce structured data from text, the major focus was on text-to-data issues. Second, there needs to be comprehensive evaluations or metrics of LLM performance.
Existing benchmarks frequently use simple objective metrics like word overlap to gauge how well the content produced by the machine is categorizing information. There might need to be more to determine if LLMs can provide structured output because a proper assessment measure should also consider the format of the information being produced. Third, could present LLMs function better to follow human natural language inputs more accurately and provide outputs with accurate formats and error-free content? This study attempts to fill these gaps in the literature and enhance the training datasets and assessment criteria for LLMs producing structured output.
The following list of their contributions: (1) They created a benchmark called STRUCBENCH that focuses on producing structured texts in raw text, HTML, and LaTeX forms. They also carefully assess the capabilities of well-known LLMs, identifying significant problems with content correctness, formatting, numerical reasoning, and managing lengthy tables. (2) They undertake empirical assessments of well-known LLMs on their structured text generation benchmark, incorporating notable datasets and extending to varied areas, giving a deeper knowledge of the common mistake kinds and dimensions of flaws. Their findings imply that GPT-3.5 and GPT-4 need help producing precisely right outputs, with problems mostly resulting from faulty content, poor formatting, insufficient numerical reasoning skills, and their inability to manage lengthy tables. (3) They use structure-aware instruction tuning to solve these problems, training the LLaMA model to adhere to these formats after utilizing ChatGPT to create format instructions. The positive outcomes on visible and hidden data suggest that it might significantly improve LLMs’ capacity to provide structured outputs.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.