Are Your AI Models Hungry for Too Much Power? This Paper from Microsoft Introduces Splitwise to Split the Bill
Although large language models (LLMs) have shown impressive capabilities when it comes to language processing, they are computationally expensive and require sophisticated hardware infrastructure. The surge in the popularity of these models has necessitated the deployment of GPUs at an unprecedented rate, posing significant challenges for cloud providers. Since the power to fuel this demand for GPUs is limited, it is not odd for user queries to be rejected, and therefore, researchers are working on improving the existing infrastructure to make it more efficient.
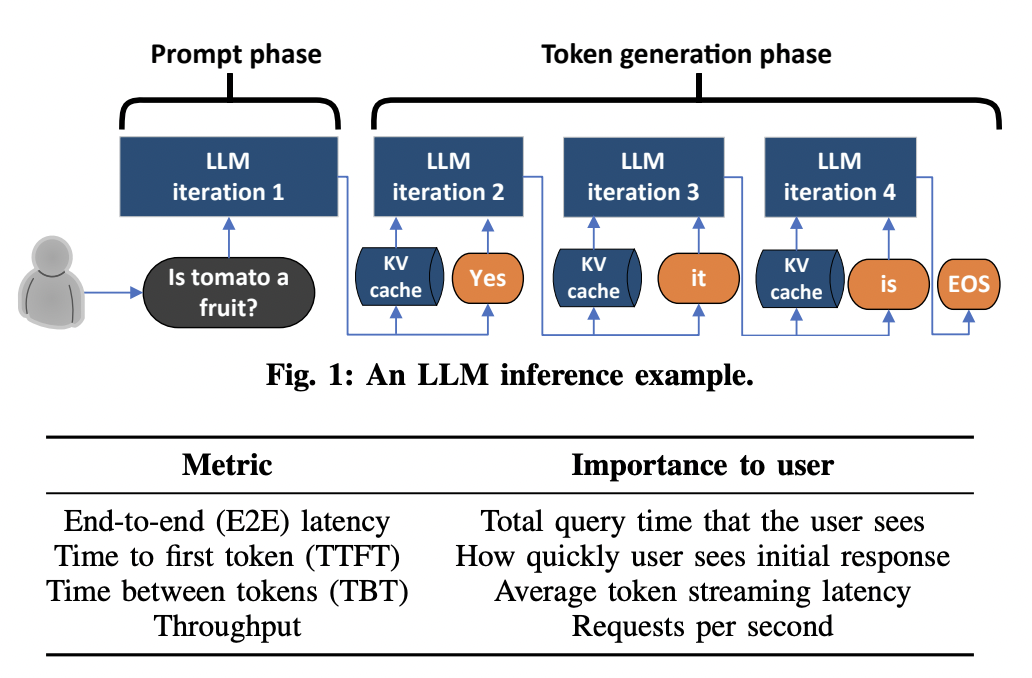
There are two phases associated with an LLM inference process: prompt computation (user enters a prompt) and token generation (LLM generates the output). During the first phase, the input tokens are processed in parallel by the LLM, which is compute-intensive. In the second phase, the output tokens are generated sequentially, which is a memory-intensive task. Such a design leads to low overall hardware utilization and eventually leads to much higher costs for the user.
To address the abovementioned issue, researchers at Microsoft have introduced Splitwise, which is a technique that separates prompt computation and token generation phases onto separate machines, leading to optimal utilization of available hardware. Along with the two machine pools for the two phases of inference, Splitwise also has a third one, which is dynamically sized, i.e., it expands and contracts based on the workload. Additionally, the state context, i.e., the KV-cache, is transferred from the prompt to the token machines via InfiniBand without any perceivable lag.
Splitwise also leverages two-level hierarchical scheduling for routing incoming requests, maintaining the pending queue, and managing batching of requests at each machine. The design of Splitwise is such that it focuses on better latency at a lower request rate and lesser throughput reduction at a higher request rate.
For evaluation, the researchers used Spltwise to design clusters with different GPU specifications. They also optimized the power, cost, and throughput for each query. They considered two uses of Splitwise, i.e., code and conversation using BLOOM-176B and LLaMa-2-70B models. The results show that Splitwise successfully maximizes throughput, minimizes cost, and reduces power. Moreover, the cluster design was able to maximize the throughput at the same cost as an A100 baseline cluster.
Additionally, compared to the baseline cluster, Splitwise delivered much higher performance while operating within the same power constraints. The results also show that Splitwise can adjust based on the workload requirements using the smart scheduler. Furthermore, it is also robust to changes in the LLM model, load, and token distribution.
In conclusion, Splitwise is an effective technique for optimal hardware utilization to speed up the LLM inference process by allowing separate machines to run the two phases of the same. It marks a significant leap toward efficient and high-performance LLM deployment and provides a good groundwork for other researchers to make LLM inference more efficient and sustainable.
Check out the Paper and Blog. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
![]()
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.
Credit: Source link
Comments are closed.