Artificial Intelligence (AI) Researchers at Standford Propose S4ND, a New Deep Layer Based on S4 that Extends SSMs’ Capacity to Simulate Continuous Signals to Multidimensional Data Such as Photos and Videos
Visual data modeling, such as photographs and videos, is a canonical problem in deep learning. Many current deep learning backbones with good performance on benchmarks like ImageNet have been suggested in recent years. These backbones are diverse and include 1D sequence models like the Vision Transformer (ViT), which handles pictures as patches, and 2D and 3D models that employ local convolutions over images and videos (ConvNets). Dimensions of space and time They would like techniques to recognize the difference between data and signal and directly simulate the underlying continuous signals. This would enable them to modify the model to data gathered at varied resolutions.
Deep state space models (SSM), namely S4, have obtained SotA outcomes in modeling sequence data produced from continuous signals like audio. Parameterizing and learning continuous convolutional kernels, which may subsequently be sampled differently for data at different resolutions, is a logical way to develop such models. However, one significant disadvantage of SSMs is that they were designed for 1D signs and cannot be used directly for visual data obtained from multidimensional “ND” signals. Given that 1D SSMs outperform alternative continuous modeling methods for sequence data and have had preliminary success with picture and video classification, they anticipate that they may be well suited to modeling visual data when adequately adapted to multidimensional signals.
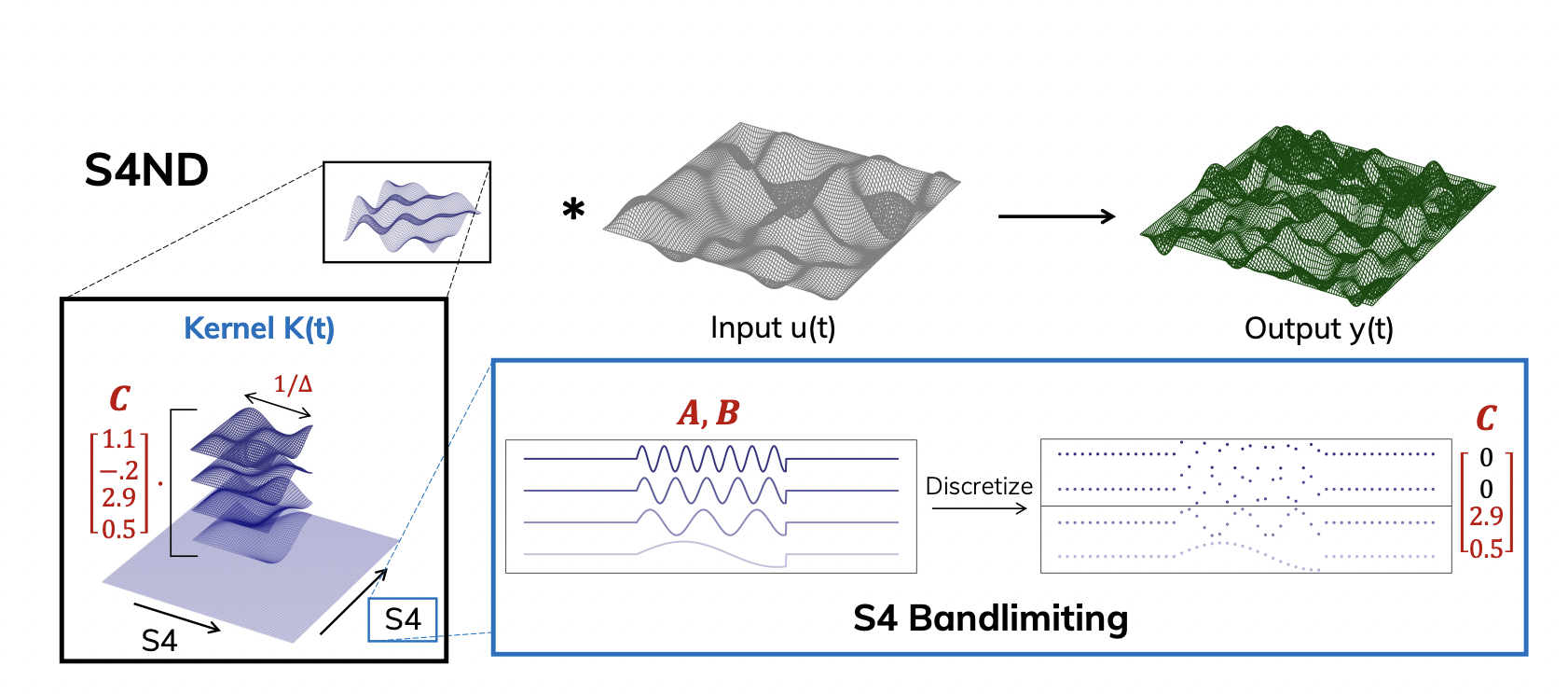
S4ND, a novel deep learning layer that extends S4 to multidimensional signals, is their crucial contribution. The central concept is to convert a typical SSM (a 1D ODE) into a multifaceted PDE regulated by an individual SSM for each dimension. They demonstrate that adding structure to this ND SSM is comparable to an ND continuous convolution that can be factored into a distinct 1D SSM convolution per dimension. As a result, the model is efficient and straightforward to construct, with the usual 1D S4 layer serving as a black box. Furthermore, it may be parameterized by S4, allowing it to describe long-range dependencies and finite windows with a learnable window size that generalizes typical local convolutions.
They demonstrate that S4ND may be utilized as a drop-in replacement in high-performance current vision systems, matching or boosting performance in 1D, 2D, and 3D. With a slight change to the training technique, replacing ViT’s self-attention with S4-1D increases top-1 accuracy by 1.5% while replacing the convolution layers in a 2D ConvNeXt backbone with S4-2D retains ImageNet-1k performance. Simply expanding (temporarily) the pretrained S4-2D-ConvNeXt backbone to 3D improves HMDB-51 video activity categorization scores by 4 points over the pretrained ConvNeXt baseline. Notably, they employ S4ND as global kernels that span the complete input form, allowing it to have global context (both geographically and temporally) at every network layer.
They also suggest a low-pass band-limiting tweak to S4 that enhances smoothness in learned convolutional kernels. While S4ND may be utilized at any resolution, performance worsens when switching between resolutions due to aliasing artifacts in the kernel. This problem has also been highlighted in previous work on continuous models. While S4 can transfer audio data between resolutions, visual data offers a more complex issue because of the scale-invariant features of pictures in space and time since sampled images with more distant objects are more likely to include power at frequencies over the Nyquist cutoff frequency.
S4ND’s continuous-signal modeling capabilities enable the development of new training recipes, such as the ability to train and test at various resolutions. Motivated by this, they suggest a simple criterion for masking off frequencies over the Nyquist cutoff frequency in the S4ND kernel. S4ND degrades by as little as 1.3% when upsampling from low- to high-resolution data (e.g., 128 x 128 -> 160 x 160) on the standard CIFAR-10 and Celeb-A datasets and can be used to facilitate progressive resizing to speed up training by 22% with a 1% drop in final accuracy compared to training at the high resolution alone. They also demonstrate that their unique band-limiting approach is vital to these capabilities, with ablations showing an absolute performance decrease of up to 20%+ in the absence of it.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.