Artificial Intelligence (AI) Researchers from Cornell University Propose a Novel Neural Network Framework to Address the Video Matting Problem

Image and video editing are two of the most popular applications for computer users. With the advent of Machine Learning (ML) and Deep Learning (DL), image and video editing have been progressively studied through several neural network architectures. Until very recently, most DL models for image and video editing were supervised and, more specifically, required the training data to contain pairs of input and output data to be used for learning the details of the desired transformation. Lately, end-to-end learning frameworks have been proposed, which require as input only a single image to learn the mapping to the desired edited output.
Video matting is a specific task belonging to video editing. The term “matting “dates back to the 19th century when glass plates of matte paint were set in front of a camera during filming to create the illusion of an environment that was not present at the filming location. Nowadays, the composition of multiple digital images follows similar proceedings. A composite formula is exploited to shade the intensity of the foreground and background of each image, expressed as a linear combination of the two components.
Although really powerful, this process has some limitations. It requires an unambiguous factorization of the image into foreground and background layers, which are then assumed to be independently treatable. In some situations like video matting, hence a sequence of temporal- and spatial-dependent frames, the layers decomposition becomes a complex task.
This paper’s goals are the enlightenment of this process and increasing decomposition accuracy. The authors propose factor matting, a variant of the matting problem that factors video into more independent components for downstream editing tasks. To address this problem, they then present FactorMatte, an easy-to-use framework that combines classical matting priors with conditional ones based on expected deformations in a scene. The classic Bayes formulation, for instance, referring to the estimation of the maximum a posteriori probability, is extended to remove the limiting assumption on the independence of foreground and background. The majority of the approaches furthermore assume that background layers remain static over time, which is seriously limiting for most video sequences.
To overcome these limitations, FactorMatte relies on two modules: a decomposition network that factors the input video into one or more layers for each component and a set of patch-based discriminators that represent conditional priors on each component. The architecture pipeline is depicted below.
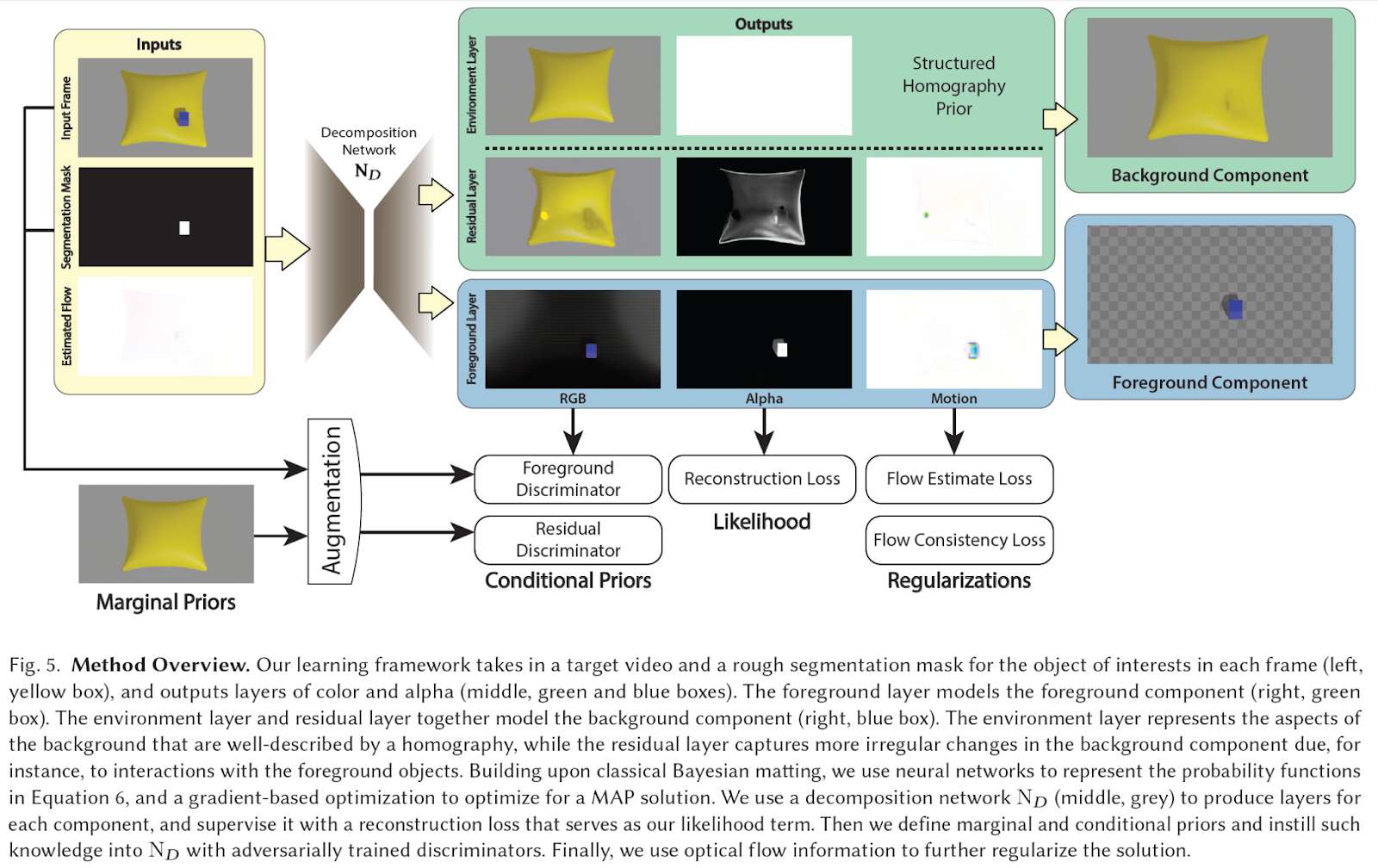
The input to the decomposition network is composed by a video and a rough segmentation mask for the object of interest frame by frame (left, yellow box). With this information, the network produces layers of color and alpha (middle, green and blue boxes) based on a reconstruction loss. The foreground layer models the foreground component (right, green
box), while the environment layer and residual layer together model the background component (right, blue box). The environment layer represents the static-like aspects of the background, while the residual layer captures more irregular changes in the background component due to interactions with the foreground objects (the pillow deformation in the figure). For each of these layers, one discriminator has been trained to learn the respective marginal priors.
The matting outcome for some selected samples is presented in the figure below.

Although FactorMatte is not perfect, the produced results are clearly more accurate than the baseline approach (OmniMatte). In all given samples, background and foreground layers present a clean separation between each other, which can not be asserted for the compared solution. Furthermore, ablation studies have been conducted to prove the effectiveness of the proposed solution.
This was the summary of FactorMatte, a novel framework to address the video matting problem. If you are interested, you can find more information in the links below.
Check out the paper, code, and project All Credit For This Research Goes To Researchers on This Project. Also, don’t forget to join our Reddit page and discord channel, where we share the latest AI research news, cool AI projects, and more.
![]()
Daniele Lorenzi received his M.Sc. in ICT for Internet and Multimedia Engineering in 2021 from the University of Padua, Italy. He is a Ph.D. candidate at the Institute of Information Technology (ITEC) at the Alpen-Adria-Universität (AAU) Klagenfurt. He is currently working in the Christian Doppler Laboratory ATHENA and his research interests include adaptive video streaming, immersive media, machine learning, and QoS/QoE evaluation.
Credit: Source link
Comments are closed.