ASAPP AI Researchers Propose a Family of Pre-Trained Models (SEW) for Automatic Speech Recognition (ASR) That Could be Significantly Better in Performance-Efficiency Than the Existing Wav2Vec 2.0 Architecture

Recent research in natural language processing and computer vision has aimed to increase the efficiency of pre-trained models to reduce the financial and environmental expenses of training and fine-tuning them. We haven’t seen comparable attempts in speaking for whatever reason. Efficiency advances in speech might mean better performance for similar inference times, in addition to cost savings related to more efficient training of pre-trained models.
Due to a self-supervised training paradigm, Wav2Vec 2.0 (W2V2) is one of the current state-of-the-art models for Automatic Speech Recognition. This training method enables us to pre-train a model using unlabeled data, which is always more readily available. The model may then be fine-tuned for a specific purpose on a given dataset. It has attracted a lot of interest and follow-up work for using pre-trained W2V2 models in various downstream applications, such as speech-to-text translation (Wang et al., 2021) and named entity recognition (Shon et al., 2021). However, researchers believe that the model architecture has several sub-optimal design decisions that render it inefficient. To back up this claim, researchers ran a series of tests on various components of the W2V2 model architecture, revealing the performance-efficiency tradeoff in the W2V2 model design space. Higher performance (lower ASR word mistake rate) necessitates a bigger pre-trained model and poorer efficiency (inference speed).
Is it possible to get a better tradeoff (the same performance with quicker inference)? What can researchers offer as an alternative? A more efficient pre-trained model with improved performance due to its efficiency benefits.
Squeezed and Efficient Wav2vec (SEW)
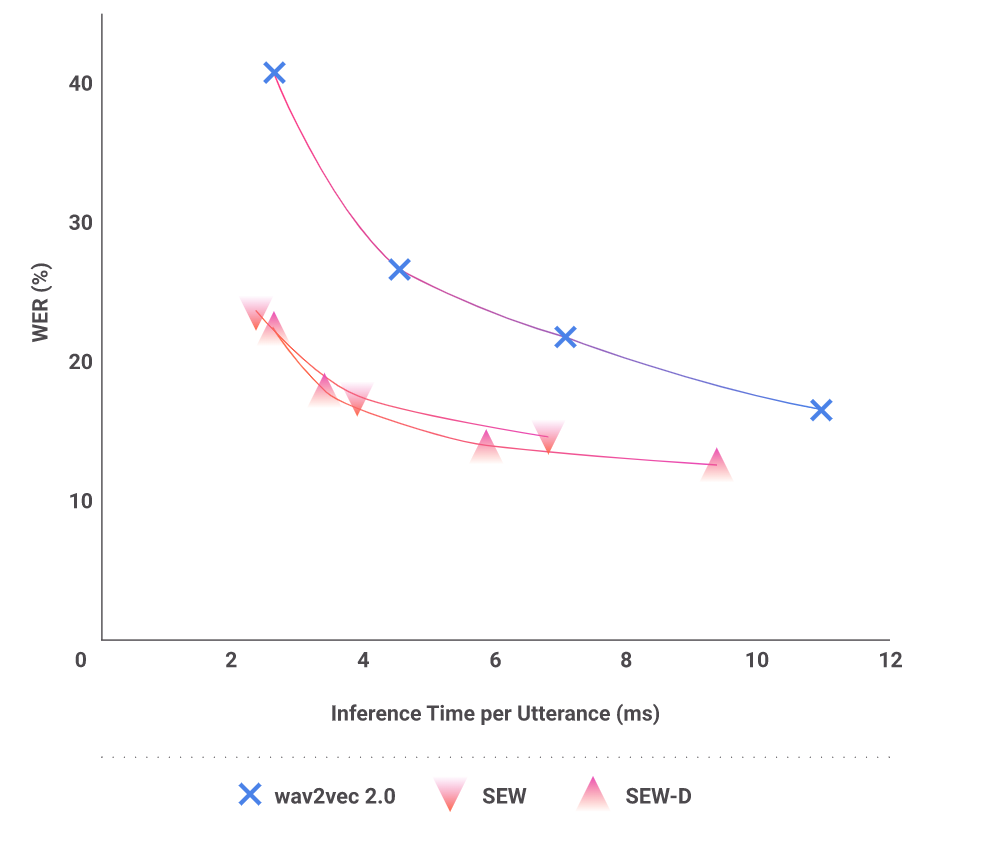
On academic datasets, researchers propose SEW (Squeezed and Efficient Wav2vec) and SEW-D (SEW with Disentangled attention), which can achieve a much better performance-efficiency tradeoff—their smaller SEW-D-mid achieves 13.5 percent WERR (word error rate reduction) compared to W2V2-base with 1.9x speedup during inference. While running at the same speed as the W2V2-base, our bigger SEW-D-base+ model performs similarly to W2V2-large. To outperform the W2V2-base, just 1/4 of the training epochs are required, lowering the pre-training cost considerably.
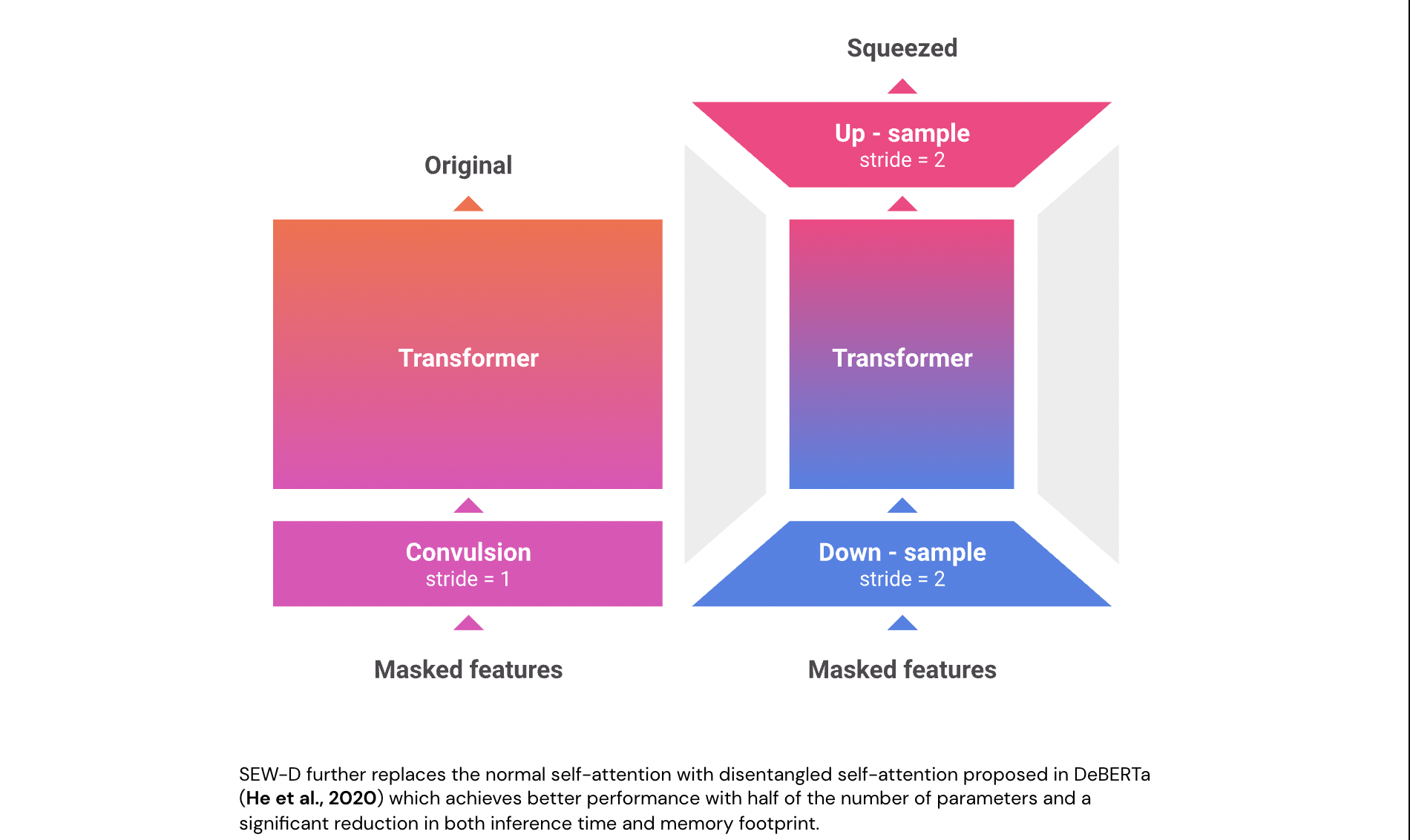
Three essential differences separate SEW from traditional W2V2 models.
- First, researchers present a compact waveform feature extractor that more uniformly distributes work across layers. This improves the model’s performance without compromising speed.
- Second, they propose a “squeeze context network,” which decreases compute and memory utilization by downsampling the audio sequence. This enables us to employ a bigger model without slowing down inference.
- Third, researchers introduce MLP predictor heads during pre-training, which boosts performance without adding overhead to the downstream application because they are destroyed after pre-training.
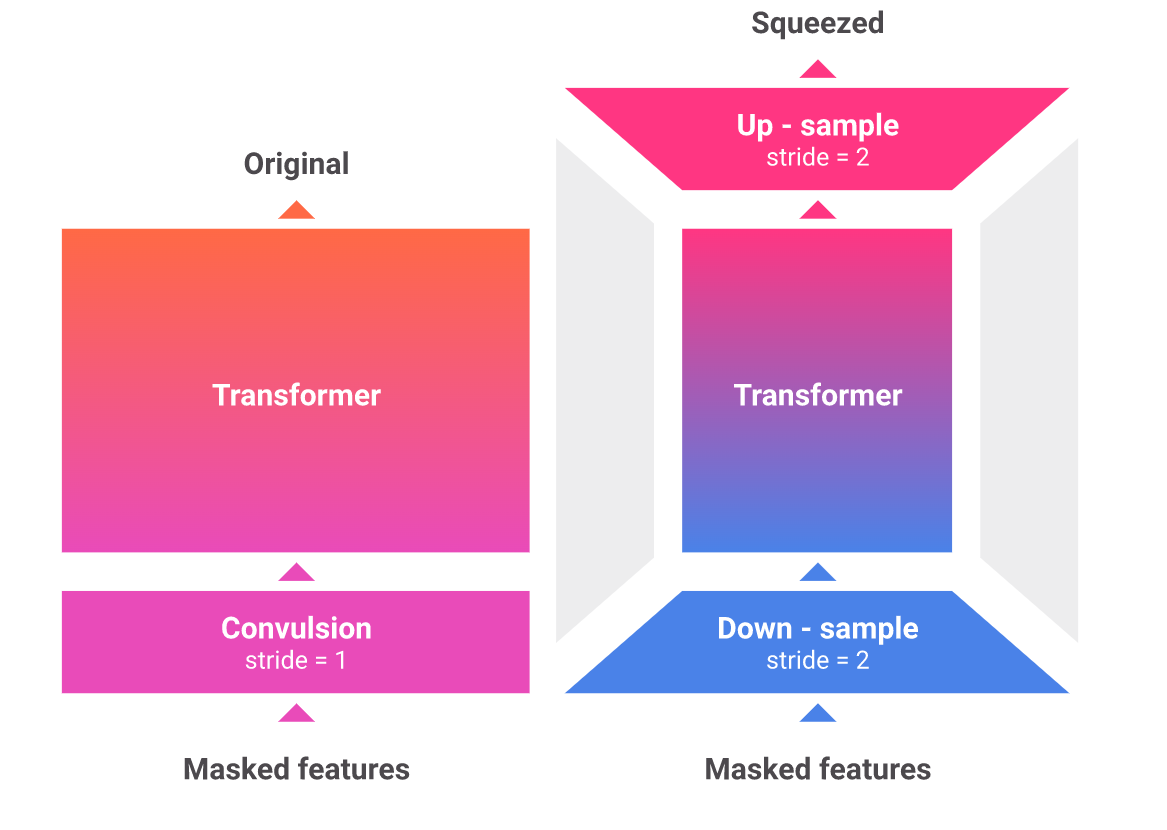
SEW-D also substitutes regular self-attention with DeBERTa’s (He et al., 2020) disentangled self-attention, which provides higher performance with half the number of parameters and a considerable reduction in inference time memory footprint.
Why does it matter?
Conversational AI systems that use the SEW pre-trained models will better recognize what customers are saying, who is saying it, and how they feel and respond quicker. For various downstream models in automatic voice recognition, speaker identification, intent classification, emotion recognition, sentiment analysis, and named entity recognition, these pre-trained models open the door to cost reductions and/or performance benefits. A pre-trained model’s speed can be simply transmitted to downstream models. The fine-tuned downstream model is smaller and quicker because the pre-trained model is smaller and faster. These advances in efficiency lower the time spent training and fine-tuning and the actual delay noticed in products.
Paper: https://arxiv.org/pdf/2109.06870.pdf
Github: https://github.com/asappresearch/sew
Reference: https://www.asapp.com/blog/wav2vec-could-be-more-efficient-so-we-created-our-own-pre-trained-asr-model-for-better-conversational-ai/?utm_source=FBGroup&fbclid=IwAR0RWaQ-9fbuCtZN_uagECFcbdx8e6GOjMsXL7RKKcPFQg1eIHNfXSVAHzk
Suggested

Credit: Source link
Comments are closed.