Assessing Natural Language Generation (NLG) in the Age of Large Language Models: A Comprehensive Survey and Taxonomy
The Natural Language Generation (NLG) field stands at the intersection of linguistics and artificial intelligence. It focuses on the creation of human-like text by machines. Recent advancements in Large Language Models (LLMs) have revolutionized NLG, significantly enhancing the ability of systems to generate coherent and contextually relevant text. This evolving field necessitates robust evaluation methodologies to assess the quality of the generated content accurately.
The central challenge in NLG is ensuring that the generated text not only mimics human language in fluency and grammar but also aligns with the intended message and context. Traditional evaluation metrics like BLEU and ROUGE primarily assess surface-level text differences, falling short in evaluating semantic aspects. This limitation hinders progress in the field and can lead to misleading research conclusions. The emerging use of LLMs for evaluation promises a more nuanced and human-aligned assessment, addressing the need for more comprehensive methods.
The researchers from WICT Peking University, Institute of Information Engineering CAS, UTS, Microsoft, and UCLA present a comprehensive study that can be broken into five sections:
- Introduction
- Formalization and Taxonomy
- Generative Evaluation
- Benchmarks and Tasks
- Open Problems
1. Introduction:
The introduction sets the stage for the survey by presenting the significance of NLG in AI-driven communication. It highlights the evolution brought by LLMs like GPT-3 in generating text across various applications. The introduction stresses the need for robust evaluation methodologies to gauge generated content’s quality accurately. It critiques traditional NLG evaluation metrics for their limitations in assessing semantic aspects and the emergence of LLMs as a promising solution for a more nuanced evaluation.
2. Formalization and Taxonomy:
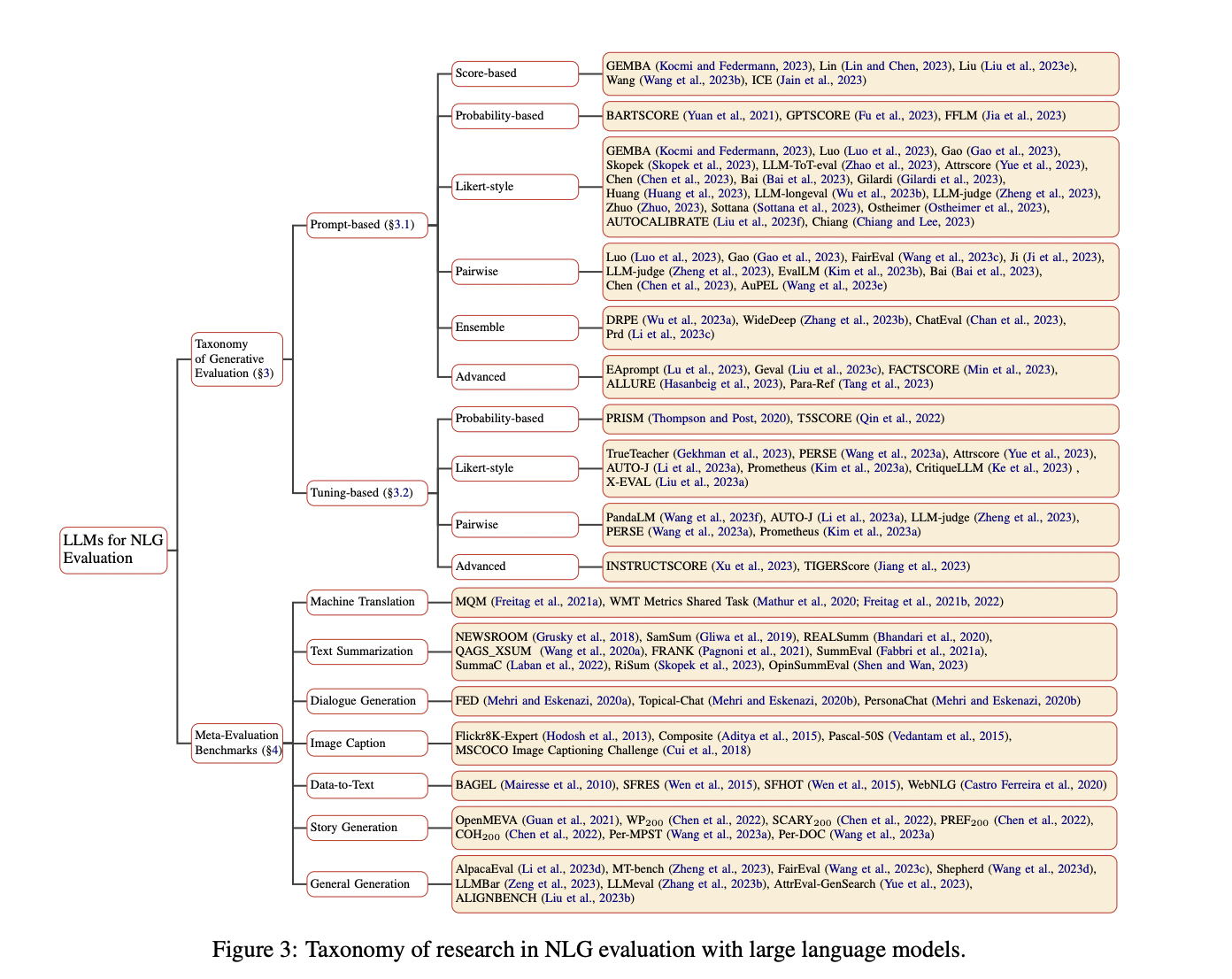
This survey provides a formalization of LLM-based NLG Evaluation tasks. It outlines a framework for assessing candidate generations across dimensions like fluency and consistency. The taxonomy categorizes NLG evaluation into dimensions: evaluation task, evaluation references, and evaluation function. Each dimension addresses various aspects of NLG tasks, offering insights into their strengths and limitations in distinct contexts. The approach classifies tasks like Machine Translation, Text Summarization, Dialogue Generation, Story Generation, Image Captioning, Data-to-Text generation, and General Generation.
3. Generative Evaluation:
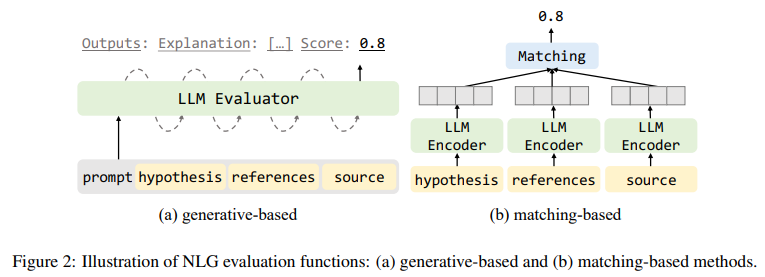
The study explores the high-capacity generative abilities of LLMs in evaluating NLG text, distinguishing between prompt-based and tuning-based evaluations. It discusses different scoring protocols, including score-based, probability-based, Likert-style, pairwise comparison, ensemble, and advanced evaluation methods. The study provides a detailed exploration of these evaluation methods, accompanied by their respective evaluation protocols, and how they cater to diverse evaluation needs in NLG.
4. Benchmarks and Tasks:
This study presents a comprehensive overview of various NLG tasks and the meta-evaluation benchmarks used to validate the effectiveness of LLM-based evaluators. It discusses benchmarks in Machine Translation, Text Summarizing, Dialogue Generation, Image Caption, Data-to-Text, Story Generation, and General Generation. It provides insights into how these benchmarks assess the concurrence between automatic evaluators and human preferences.
5. Open Problems:
The research addresses the unresolved challenges in the field. It discusses the biases inherent in LLM-based evaluators, the robustness issues of these evaluators, and the complexities surrounding domain-specific evaluation. The study emphasizes the need for more flexible and comprehensive evaluation methods capable of adapting to complex instructions and real-world requirements, highlighting the gap between current evaluation methods and the evolving capabilities of LLMs.
In conclusion, The survey of LLM-based methods for NLG evaluation highlights a significant shift in assessing generated content. These methods offer a more sophisticated and human-aligned approach, addressing the limitations of traditional evaluation metrics. Using LLMs introduces a nuanced understanding of text quality, encompassing semantic coherence and creativity. This advancement marks a pivotal step towards more accurate and comprehensive evaluations in NLG, promising to enhance the reliability and effectiveness of these systems in real-world applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
Credit: Source link
Comments are closed.