AudioSep : Separate Anything You Describe
LASS or Language-queried Audio Source Separation is the new paradigm for CASA or Computational Auditory Scene Analysis that aims to separate a target sound from a given mixture of audio using a natural language query that provides the natural yet scalable interface for digital audio tasks & applications. Although the LASS frameworks have advanced significantly in the past few years in terms of achieving desired performance on specific audio sources like musical instruments, they are unable to separate the target audio in the open domain.
AudioSep, is a foundational model that aims to resolve the current limitations of LASS frameworks by enabling target audio separation using natural language queries. The developers of the AudioSep framework have trained the model extensively on a wide variety of large-scale multimodal datasets, and have evaluated the performance of the framework on a wide array of audio tasks including musical instrument separation, audio event separation, and enhancing the speech amongst many others. The initial performance of AudioSep satisfies the benchmarks as it demonstrates impressive zero-shot learning capabilities and delivers strong audio separation performance.
In this article, we will be taking a deeper dive into the working of the AudioSep framework as we will evaluate the architecture of the model, the datasets used for training & evaluation, and the essential concepts involved in the working of the AudioSep model. So let’s begin with a basic introduction to the CASA framework.
The CASA or the Computational Auditory Scene Analysis framework is a framework used by developers to design machine listening systems that have the ability to perceive complex sound environments in a way similar to the way humans perceive sound using their auditory systems. Sound separation, with a special focus on target sound separation, is a fundamental area of research within the CASA framework, and it aims to solve the “cocktail party problem” or separating real-world audio recordings from individual audio source recordings or files. The importance of sound separation can be attributed mainly to its widespread applications including music source separation, audio source separation, speech enhancement, target sound identification, and a lot more.
Most of the work on sound separation done in the past revolves mainly around the separation of one or more audio sources like music separation or speech separation. A new model going by the name of USS or Universal Sound Separation aims to separate arbitrary sounds in real world audio recordings. However, it is a challenging & restrictive task to separate every sound source from an audio mixture primarily because of the wide array of different sound sources existing in the world which is the major reason why the USS method is not feasible for real-world applications working in real-time.
A feasible alternative to the USS method is the QSS or the Query-based Sound Separation method that aims to separate an individual or target sound source from the audio mixture based on a particular set of queries. Thanks to this, the QSS framework allows developers & users to extract the desired sources of audio from the mixture based on their requirements that makes the QSS method a more practical solution for digital real-world applications like multimedia content editing or audio editing.
Furthermore, developers have recently proposed an extension of the QSS framework, the LASS framework or the Language-queried Audio Source Separation framework that aims to separate arbitrary sources of sound from an audio mixture by making use of the natural language descriptions of the target audio source. As the LASS framework allows users to extract the target audio sources using a set of natural language instructions, it might become a powerful tool with widespread applications in digital audio applications. When compared against traditional audio-queried or vision-queried methods, using natural language instructions for audio separation offers a greater degree of advantage as it adds flexibility, and makes the acquisition of query information much more easier & convenient. Furthermore, when compared with label query-based audio separation frameworks that make use of a predefined set of instructions or queries, the LASS framework does not limit the number of input queries, and has the flexibility to be generalized to open domain seamlessly.
Originally, the LASS framework relies on supervised learning in which the model is trained on a set of labeled audio-text paired data. However, the main issue with this approach is the limited availability of annotated & labeled audio-text data. In order to reduce the reliability of the LASS framework on annotated audio-text labeled data, the models are trained using the multimodal supervision learning approach. The primary aim behind using a multimodal supervision approach is to use multimodal contrastive pre-training models like the CLIP or Contrastive Language Image Pre Training model as the query encoder for the framework. Since the CLIP framework has the ability to align text embeddings with other modalities like audio or vision, it allows developers to train the LASS models using data-rich modalities, and allows the interference with the textual data in a zero-shot setting. The current LASS frameworks however make use of small-scale datasets for training, and applications of the LASS framework across hundreds of potential domains are yet to be explored.
To resolve the current limitations faced by the LASS frameworks, developers have introduced AudioSep, a foundational model that aims to separate sound from an audio mixture using natural language descriptions. The current focus for AudioSep is to develop a pre-trained sound separation model that leverages existing large-scale multimodal datasets to enable the generalization of LASS models in open-domain applications. To summarize, the AudioSep model is : “A foundational model for universal sound separation in open domain using natural language queries or descriptions trained on large-scale audio & multimodal datasets”.
AudioSep : Key Components & Architecture
The architecture of the AudioSep framework comprises two key components: a text encoder, and a separation model.
The Text Encoder
The AudioSep framework uses a text encoder of the CLIP or Contrastive Language Image Pre Training model or the CLAP or Contrastive Language Audio Pre Training model to extract text embeddings within a natural language query. The input text query consists of a sequence of “N” tokens that is then processed by the text encoder to extract the text embeddings for the given input language query. The text encoder makes use of a stack of transformer blocks to encode the input text tokens, and the output representations are aggregated after they are passed through the transformer layers that results in the development of a D-dimensional vector representation with fixed length where D corresponds to the dimensions of CLAP or the CLIP models while the text encoder is frozen during the training period.
The CLIP model is pre-trained on a large-scale dataset of image-text paired data using contrastive learning which is the primary reason why its text encoder learns mapping textual descriptions on the semantic space that is also shared by the visual representations. The advantage the AudioSep gains by using CLIP’s text encoder is that it can now scale up or train the LASS model from unlabeled audio-visual data using the visual embeddings as an alternative, thus enabling the training of LASS models without the requirement of annotated or labeled audio-text data.
The CLAP model works similar to the CLIP model and makes use of contrastive learning objective as it uses a text & an audio encoder to connect audio & language, thus bringing text & audio descriptions on an audio-text latent space joined together.
Separation Model
The AudioSep framework makes use of a frequency-domain ResUNet model that is fed a mixture of audio clips as the separation backbone for the framework. The framework works by first applying an STFT or a Short-Time Fourier Transform on the waveform to extract a complex spectrogram, the magnitude spectrogram, and the Phase of X. The model then follows the same setting and constructs an encoder-decoder network to process the magnitude spectrogram.
The ResUNet encoder-decoder network consists of 6 residual blocks, 6 decoder blocks, and 4 bottleneck blocks. The spectrogram in each encoder block uses 4 residual conventional blocks to downsample itself into a bottleneck feature whereas the decoder blocks make use of 4 residual deconvolutional blocks to obtain the separation components by upsampling the features. Following this, each of the encoder blocks & its corresponding decoder blocks establish a skip connection that operates at the same upsampling or downsampling rate. The residual block of the framework consists of 2 Leaky-ReLU activation layers, 2 batch normalization layers, and 2 CNN layers, and furthermore, the framework also introduces an additional residual shortcut that connects the input & output of every individual residual block. The ResUNet model takes the complex spectrogram X as the input, and produces the magnitude mask M as the output with the phase residual being conditioned on text embeddings that controls the magnitude of scaling, and rotation of the angle of the spectrogram. The separated complex spectrogram can then be extracted by multiplying the predicted magnitude mask & phase residual with STFT (Short-Time Fourier Transform) of the mixture.

In its framework, AudioSep uses a FiLm or Feature-wise Linearly modulated layer to bridge the separation model & the text encoder after the deployment of the convolutional blocks in the ResUNet.
Training and Loss
During the training of the AudioSep model, developers use the loudness augmentation method, and train the AudioSep framework end-to-end by making use of an L1 loss function between the ground truth & predicted waveforms.
Datasets and Benchmarks
As mentioned in previous sections, AudioSep is a foundational model that aims to resolve the current dependency of LASS models on annotated audio-text paired datasets. The AudioSep model is trained on a wide array of datasets to equip it with multimodal learning capabilities, and here is a detailed description of the dataset & benchmarks used by developers to train the AudioSep framework.
AudioSet
AudioSet is a weakly-labeled large-scale audio dataset comprising over 2 million 10-second audio snippets extracted directly from YouTube. Each audio snippet in the AudioSet dataset is categorized by the absence or presence of sound classes without the specific timing details of the sound events. The AudioSet dataset has over 500 distinct audio classes including natural sounds, human sounds, vehicle sounds, and a lot more.
VGGSound
The VGGSound dataset is a large-scale visual-audio dataset that just like AudioSet has been sourced directly from YouTube, and it contains over 2,00,000 video clips, each of them having a length of 10 seconds. The VGGSound dataset is categorized into over 300 sound classes including human sounds, natural sounds, bird sounds, and more. The use of the VGGSound dataset ensures that the object responsible for producing the target sound is also describable in the corresponding visual clip.
AudioCaps
AudioCaps is the largest audio captioning dataset available publicly, and it comprises over 50,000 10-second audio clips that are extracted from the AudioSet dataset. The data in the AudioCaps is divided into three categories: training data, testing data, and validation data, and the audio clips are humanly-annotated with natural language descriptions using the Amazon Mechanical Turk platform. It’s worth noting that each audio clip in the training dataset has a single caption, whereas the data in the testing & validation sets each have 5 ground-truth captions.
ClothoV2
The ClothoV2 is an audio captioning dataset that consists of clips sourced from the FreeSound platform, and just like AudioCaps, each audio clip is humanly-annotated with natural language descriptions using the Amazon Mechanical Turk platform.
WavCaps
Just like AudioSet, WavCaps is a weakly-labeled large-scale audio dataset comprising over 400,000 audio clips with captions, and a total runtime approximating to 7568 hours of training data. The audio clips in the WavCaps dataset are sourced from a wide array of audio sources including BBC Sound Effects, AudioSet, FreeSound, SoundBible, and more.

Training Details
During the training phase, the AudioSep model randomly samples two audio segments sourced from two different audio clips from the training dataset, and then mixes them together to create a training mixture where the length of each audio segment is about 5 seconds. The model then extracts the complex spectrogram from the waveform signal using a Hann window of size 1024 with a 320 hop size.
The model then makes use of the text encoder of the CLIP/CLAP models to extract the textual embeddings with text supervision being the default configuration for AudioSep. For the separation model, the AudioSep framework uses a ResUNet layer consisting of 30 layers, 6 encoder blocks, and 6 decoder blocks resembling the architecture followed in the universal sound separation framework. Furthermore, each encoder block has two convolutional layers with a 3×3 kernel size with the number of output feature maps of encoder blocks being 32, 64, 128, 256, 512, and 1024 respectively. The decoder blocks share symmetry with the encoder blocks, and the developers apply the Adam optimizer to train the AudioSep model with a batch size of 96.
Evaluation Results
On Seen Datasets
The following figure compares the performance of AudioSep framework on seen datasets during the training phase including the training datasets. The below figure represents the benchmark evaluation results of the AudioSep framework when compared against baseline systems including Speech Enhancement models, LASS, and CLIP. The AudioSep model with CLIP text encoder is represented as AudioSep-CLIP, whereas the AudioSep model with CLAP text encoder is represented as AudioSep-CLAP.

As it can be seen in the figure, the AudioSep framework performs well when using audio captions or text labels as input queries, and the results indicate the superior performance of the AudioSep framework when compared against previous benchmark LASS and audio-queried sound separation models.
On Unseen Datasets
To assess the performance of AudioSep in a zero-shot setting, developers continued to evaluate the performance on unseen datasets, and the AudioSep framework delivers impressive separation performance in a zero-shot setting, and the results are displayed in the figure below.

Furthermore, the image below shows the results of evaluating the AudioSep model against Voicebank-Demand speech enhancement.

The evaluation of the AudioSep framework indicates a strong & desired performance on unseen datasets in a zero-shot setting, and thus makes way for performing sound operation tasks on new data distributions.
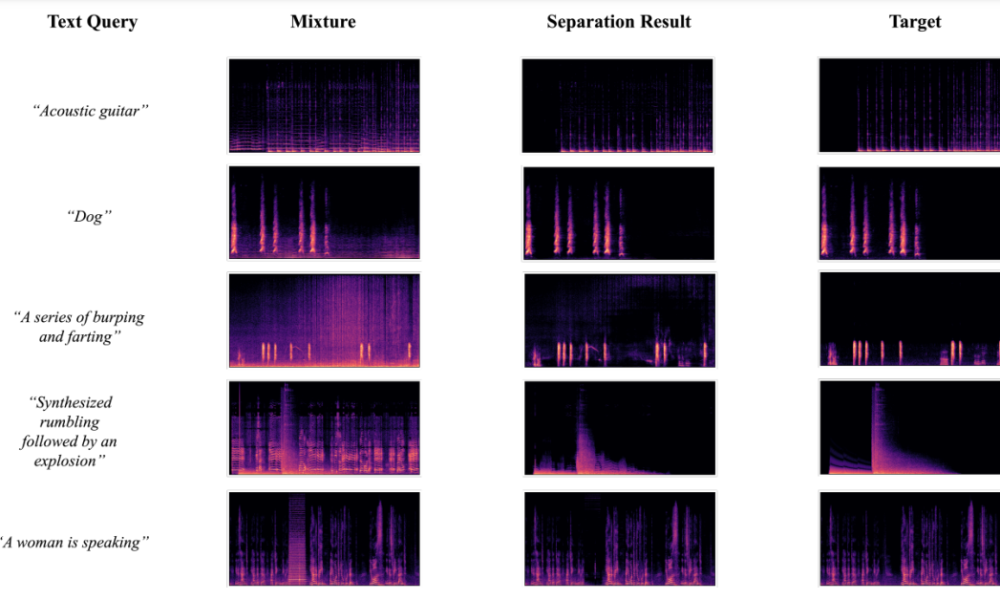
Visualization of Separation Results
The below figure shows the results obtained when the developers used the AudioSep-CLAP framework to perform visualizations of spectrograms for ground-truth target audio sources, and audio mixtures and separated audio sources using text queries of diverse audios or sounds. The results allowed developers to observe that the spectrogram’s separated source pattern is close to the source of the ground truth that further supports the objective results obtained during the experiments.

Comparison of Text Queries
The developers evaluate the performance of AudioSep-CLAP and AudioSep-CLIP on AudioCaps Mini, and the developers make use of the AudioSet event labels , the AudioCaps captions, and re-annotated natural language descriptions to examine the effects of different queries, and the following figure shows an example of the AudioCaps Mini in action.

Conclusion
AudioSep is a foundational model that is developed with the aim of being an open-domain universal sound separation framework that uses natural language descriptions for audio separation. As observed during the evaluation, the AudioSep framework is capable of performing zero-shot & unsupervised learning seamlessly by making use of audio captions or text labels as queries. The results & evaluation performance of AudioSep indicate a strong performance that outperforms current state of the art sound separation frameworks like LASS, and it might be capable enough to resolve the current limitations of popular sound separation frameworks.
Credit: Source link
Comments are closed.