AWS AI Research Proposes an Advanced Machine Learning Data Augmentation Pipeline Leveraging Controllable Diffusion Models and CLIP for Enhanced Object Detection
Modern object detection algorithms rely heavily on deep learning models that have been trained end-to-end. Simply training these models with a bigger and more diversified annotated dataset is a somewhat brutish but effective formula for additional performance improvement. Nevertheless, for object detection to work, one needs the names of the items in the images and precise bounding boxes that surround them completely. Training object detection models with such datasets is far more time-consuming and expensive than picture classification due to the additional effort required for curation.
Data augmentation is a way to increase the number of training instances without adding new annotations to the dataset. This is achieved by bootstrapping an existing dataset. To train a more robust model for object detection, the conventional data augmentation method includes manipulating each image in some way, such as rotating, resizing, or flipping it.
As one might expect, generative data augmentation gives the augmented samples more variety, realism, and fresh visual characteristics. Methods for enhancing data that do not generate new information cannot achieve these results. They significantly improve performance in downstream vision tasks, which is not unexpected.
Generative data augmentation using bounding box labels is not as clear-cut as classic data augmentation approaches, where the annotations can be determined easily. Thus, picture classification tasks are the exclusive domain of the study above that employs generative data augmentation.
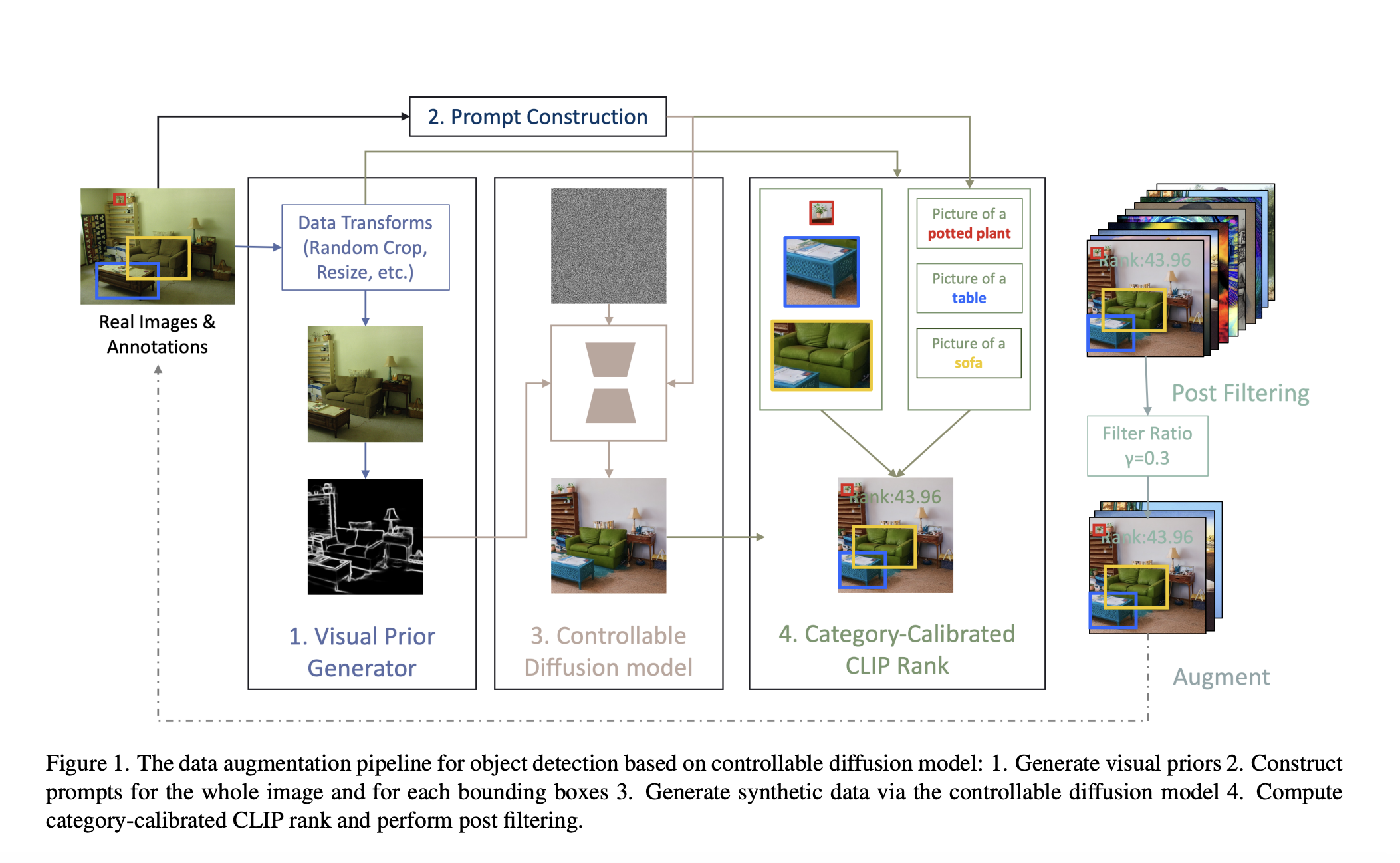
A new study by AWS AI investigates if it’s possible to perform generative data augmentation for object detection via diffusion models with more fine-grained control and without human annotations. The team first planned to utilize diffusion-based inpainting techniques to create the object inside the specified bounding box. The object and its boundary box are both obtained in this manner. The item may not completely encapsulate the bounding box, a small but important consideration.
The researchers utilize visual priors like HED boundaries and semantic segmentation masks extracted from each image in the original annotated dataset in conjunction with configurable diffusion models for guided text-to-image generation. So, the produced image has high-quality bounding box annotation but has new objects, lighting, or styles inside. To exclude photographs where the object within the bounding box does not match the prompt, they also suggest a new method for calculating CLIP scores. When the researchers included their first idea, which uses inpainting-based approaches, into the pipeline, they saw even more speed increases.
To assess how well the method works, the researchers run comprehensive experiments using various downstream datasets, conventional settings with the PASCAL VOC dataset, and few-shot settings with the MSCOCO dataset. The full data settings reflect training scenarios with abundant annotations, while the few-shot settings describe scenarios with minimal annotated data.
Thorough testing of this approach with both sparse and complete datasets, findings show that it is possible to achieve an improvement of 18.0%, 15.6%, and 15.9% in the YOLOX detector’s mAP result for the COCO 5/10/30-shot dataset, 2.9% for the complete PASCAL VOC dataset, and an average improvement of 12.4% for downstream datasets.
The researchers emphasize that the proposed method can be used with other data augmentation approaches to further boost performance, given the synergy between the proposed approach and other methods.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 35k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, LinkedIn Group, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.