AWS Researchers Develop ‘TabTransformer’ to Bring the Power of Deep Learning to Data in Tables
The top-performing AI systems have deep neural networks at their core. For instance, Transformer-based language models like BERT are typically the foundation for natural language processing (NLP) applications. Applications that rely on data contained in tables have been an exception to the profound learning revolution, as methods based on decision trees have often performed better.
Researchers at AWS have been focusing on developing TabTransformer, a brand-new, deep, tabular data-modeling architecture for supervised and semi-supervised learning. TabTransformer expands Transformers beyond natural language processing to table data.
TabTransformer may be utilized for classification and regression tasks with Amazon SageMaker JumpStart. The SageMaker JumpStart UI in SageMaker Studio and the SageMaker Python SDK allows access to TabTransformer from Python code. TabTransformer has attracted interest from individuals in various fields. It also has been presented in the Weakly Supervised Learning Workshop of the ICLR 2021. Apart from this, it has been added to the official repository of Keras, a well-known open-source software library for working with deep neural networks.
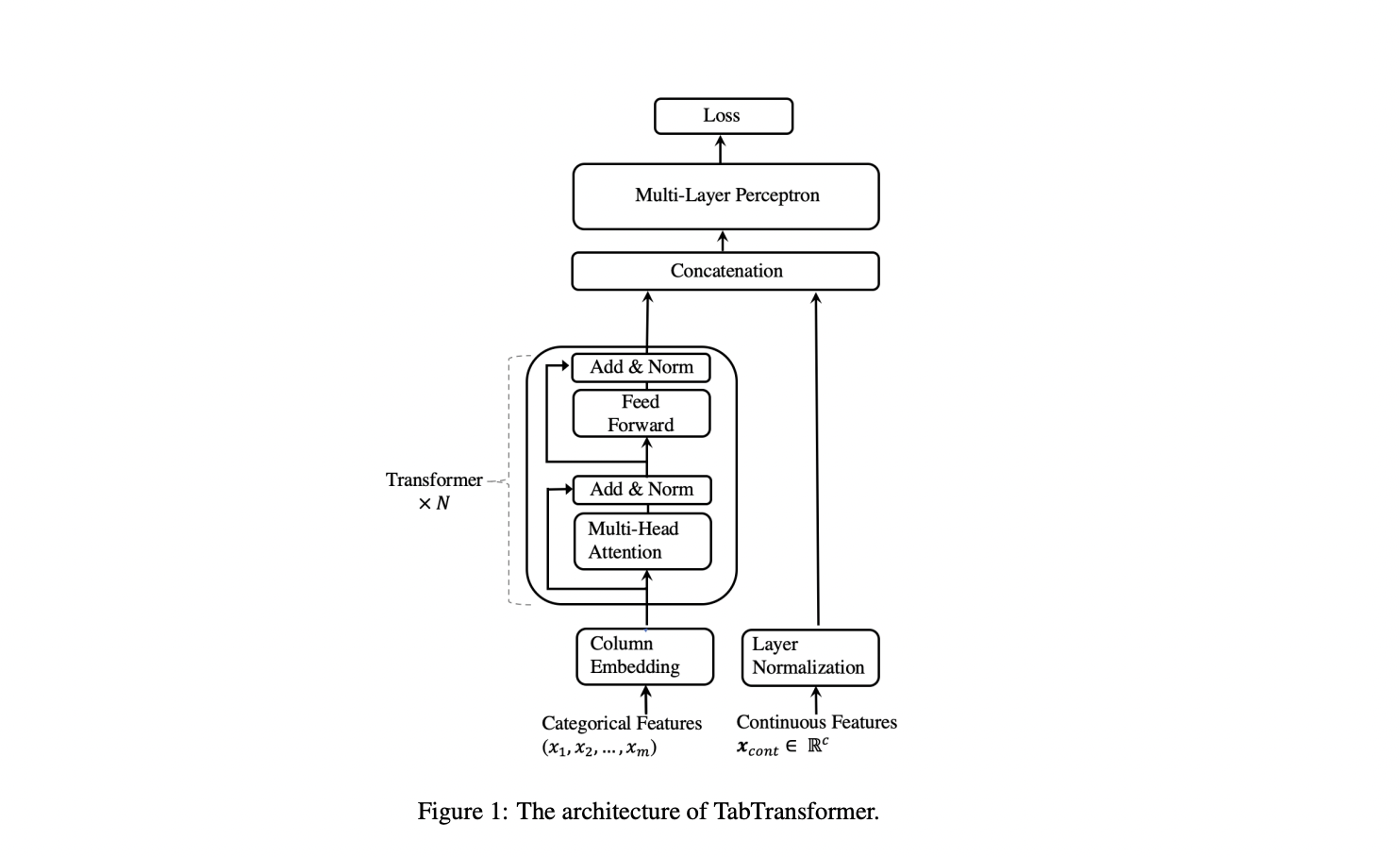
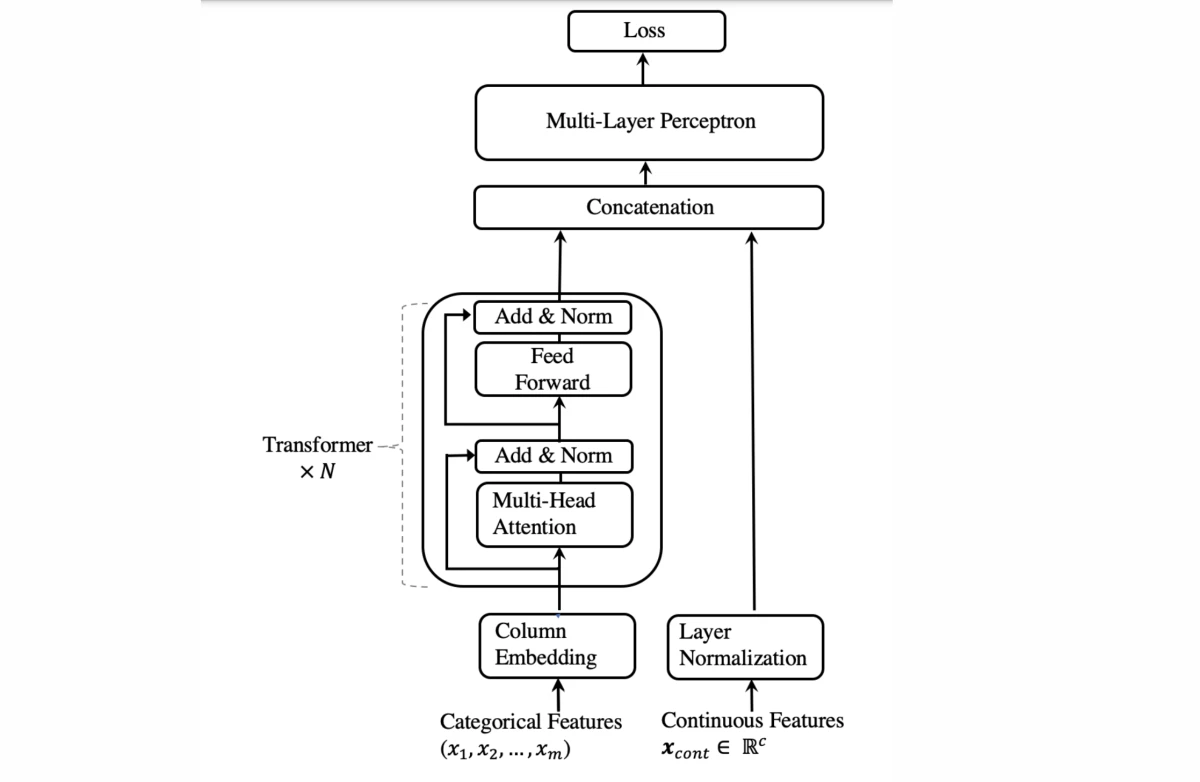
To create reliable data representations, or embeddings, for categorical variables that may take on a limited number of discrete values, like the months of the year, TabTransformer employs Transformers. Numerical values and other continuous variables are handled in parallel streams.
It uses NLP by pretraining a model on unlabeled data to learn a broad embedding scheme and then fine-tune it on labeled data to learn a specific task.
TabTransformer beats state-of-the-art deep-learning algorithms for tabular data in trials on 15 publically accessible datasets by at least 1.0 percent on mean AUC. the area under the receiver-operating curve plots false-positive versus false-negative rate. It also demonstrates that it equals the effectiveness of ensemble models based on trees. DNNs often outperform decision-tree-based models in semi-supervised situations when labeled data is limited because they can better utilize unlabeled data. TabTransformer showed an average AUC lift over the most substantial DNN benchmark of 2.1 percent using the ground-breaking unsupervised pretraining method.
The contextual embeddings learned via TabTransformer are resistant to missing and noisy data characteristics and offer greater interpretability, which we also show in the last section of our analysis. Below is a diagram of TabTransformer’s architecture. In investigations, researchers converted data types, including text, zip codes, and IP addresses, into either numeric or categorical features using typical feature-engineering approaches.
TabTransformer is definitely paving the way bringing the power of deep learning to data in tables.
This Article is written as a summary article by Marktechpost Staff based on the research article ' TABULAR DATA MODELING VIA CONTEXTUAL EMBEDDINGS'. All Credit For This Research Goes To Researchers on This Project. Checkout the paper, github, AWS article. Please Don't Forget To Join Our ML Subreddit
Credit: Source link
Comments are closed.