AWS Researchers Introduce Gemini: Pioneering Fast Failure Recovery in Large-Scale Deep Learning Training
A team of researchers from Rice University and Amazon Web Services have developed a distributed training system called GEMINI, which aims to improve failure recovery in the training of large machine learning models. The system deals with the challenges associated with using CPU memory for checkpoints, which ensures higher availability and minimizes interference with training traffic. GEMINI has shown significant improvement over existing solutions, making it a promising advancement in large-scale deep-learning model training.
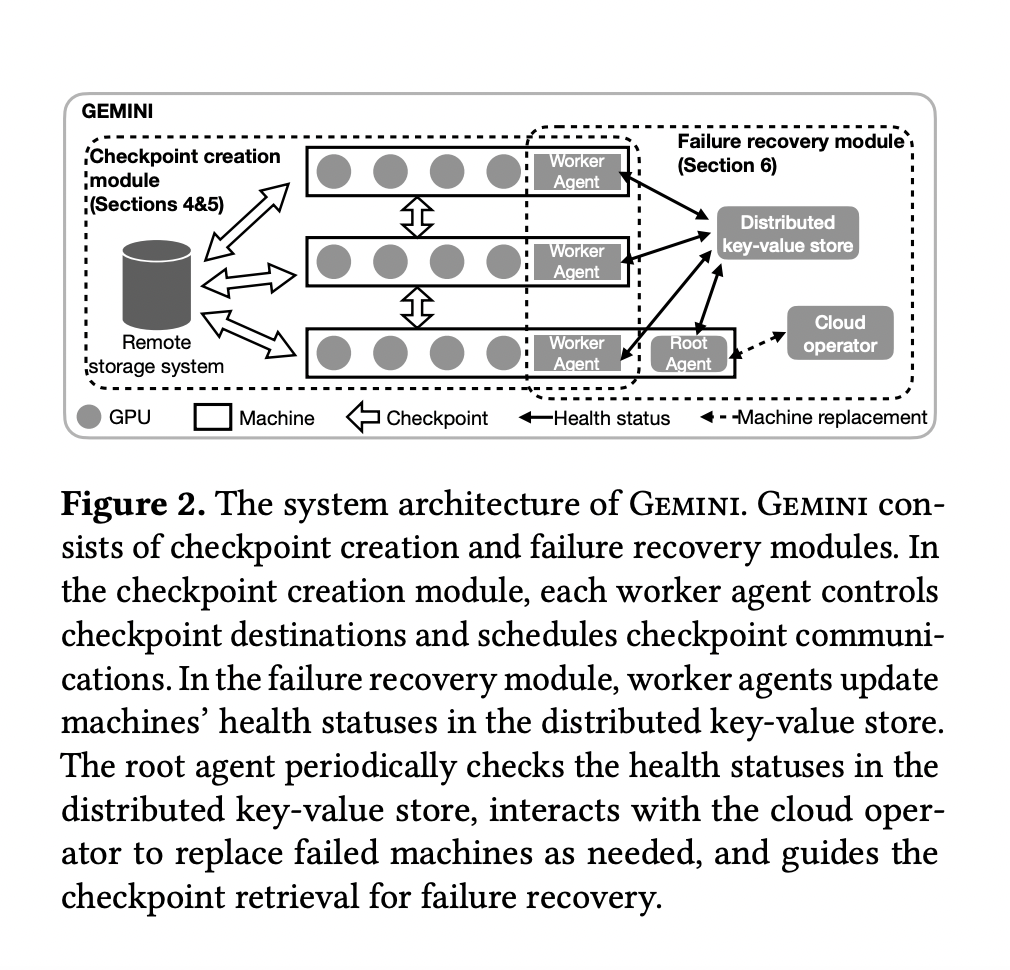
GEMINI has introduced a distributed training system to improve the recovery process in large model training. Previous solutions were limited by bandwidth and storage restrictions, which affected the checkpointing frequency and model accuracy despite checkpointing interfaces being offered by deep learning frameworks like PyTorch and TensorFlow. GEMINI’s approach optimizes checkpoint placement and traffic scheduling, making it a valuable advancement in this field.
Deep learning models, especially large ones, have been recognized for their impressive performance. However, the training of large models often requires improvement due to its complexity and time consumption. The current solutions for failure recovery in large model training are hindered by limited bandwidth in remote storage, which results in significant recovery costs. GEMINI has introduced innovative CPU memory techniques that enable swift failure recovery. GEMINI’s strategies for optimal checkpoint placement and traffic scheduling have led to significantly faster failure recovery than existing solutions. It has made noteworthy contributions in the field of deep learning.
GEMINI is built on Deep-Speed, using the ZeRO-3 setting for distributed training. Amazon EC2 Auto Scaling Groups are used to manage GPU model states. Checkpoints are stored in both CPU memory and remote storage, with a three-hour checkpoint frequency. GEMINI employs a near-optimal checkpoint placement strategy to maximize recovery probability and a traffic scheduling algorithm to reduce interference. The evaluation is performed on NVIDIA GPUs but applies to other accelerators like AWS Trainium.
GEMINI significantly improves failure recovery, outperforming existing solutions by over 13 times. Evaluation results confirm its effectiveness in reducing time wastage without compromising training throughput. GEMINI’s scalability is evident across varying failure frequencies and training scales, showcasing its potential for large-scale distributed training. The traffic interleaving algorithm in GEMINI positively influences training throughput, further enhancing the system’s efficiency.
Existing solutions for failure recovery in large model training are limited by the bandwidth of remote storage, preventing high checkpoint frequencies and leading to significant wasted time. The study focuses on static and synchronous training with fixed computation resources, omitting consideration of elastic and asynchronous training methods. The issue of CPU memory size for storing checkpoint history for purposes other than failure recovery is not addressed in the current research.
In conclusion, GEMINI is an efficient and scalable distributed training system that offers fast and reliable failure recovery through checkpointing to CPU memory and an advanced placement strategy. Its high checkpoint frequencies help to reduce time wastage without affecting training throughput, making it an excellent solution for large-scale distributed training on GPU clusters.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 32k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on Telegram and WhatsApp.
![]()
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.
Credit: Source link
Comments are closed.