Baidu AI Introduces StereoDistill: A Cross-Modal Distillation Method That Narrows The Gap Between Stereo And LiDAR-Based Approaches For 3D Object Detection
3D detectors equipped with LiDAR points for autonomous driving have exhibited outperforming performance. Unfortunately, LiDAR sensors are often expensive and weather-sensitive, restricting their use. In contrast, stereo cameras are gaining popularity due to their excellent balance of affordability and accuracy. Due to stereo matching’s erroneous depth calculation, there is still a significant performance difference between stereo-based and cutting-edge LiDAR-based 3D detection techniques. Hence, the issue of whether the LiDAR model can assist the stereo model in performing better emerges.
Knowledge distillation (KD), which directs the student model to mirror the knowledge of the instructor model for performance enhancement or model compression, is a potential answer to this problem. The current KD object detection methods can be broadly divided into feature-based and response-based streams. The former performs feature-level distillation to enforce the consistency of feature representations between the teacher-student pair. At the same time, the latter adopts the confident prediction from the teacher model as soft targets in addition to the hard ground truth supervision.
Yet, a straight conversion of the KD above approaches to LiDAR-to-stereo cross-modal distillation is less effective owing to the vast difference between the two modalities. By using fine-grained feature-level distillation while being guided by LiDAR-based models, the groundbreaking study LIGA improved the performance of stereo-based models. Nevertheless, because of the inaccurate and noisy forecasts made by the LiDAR instructor, it found little advantage from the response-based distillation. Contrarily, they contend that the response-level distillation can close the cross-modal domain gap (e.g., LiDAR point cloud and binocular images). To provide an example, they first derive the stereo model’s upper bound by substituting the 3D box regression and classification outputs with the matching LiDAR model outputs (teacher).

Figure 1: By substituting the regression and classification outcomes of the stereo model (student) with the instructor LiDAR model, 3D detection performance (3D mAP) on the KITTI validation set of LIGA was achieved.
Figure 1 illustrates the excellent outcomes produced by the stereo model with the updated regression or classification predictions and exemplifies the possibilities of response-based distillation in the cross-modal domain. The high-confident or high-IoU 3D boxes (box-level) predicted by the LiDAR model are less successful than applying the vanilla response-level distillation directly. There are two causes: Due to the high sparsity of the LiDAR point cloud, much fewer high-IoU or high-confident boxes can be adopted as soft labels in a 3D scene in contrast to dense 2D images; additionally, low-quality boxes that are ignored by one-size-fits-all thresholds often contain overlooked beneficial elements like center, size, or orientation angle.
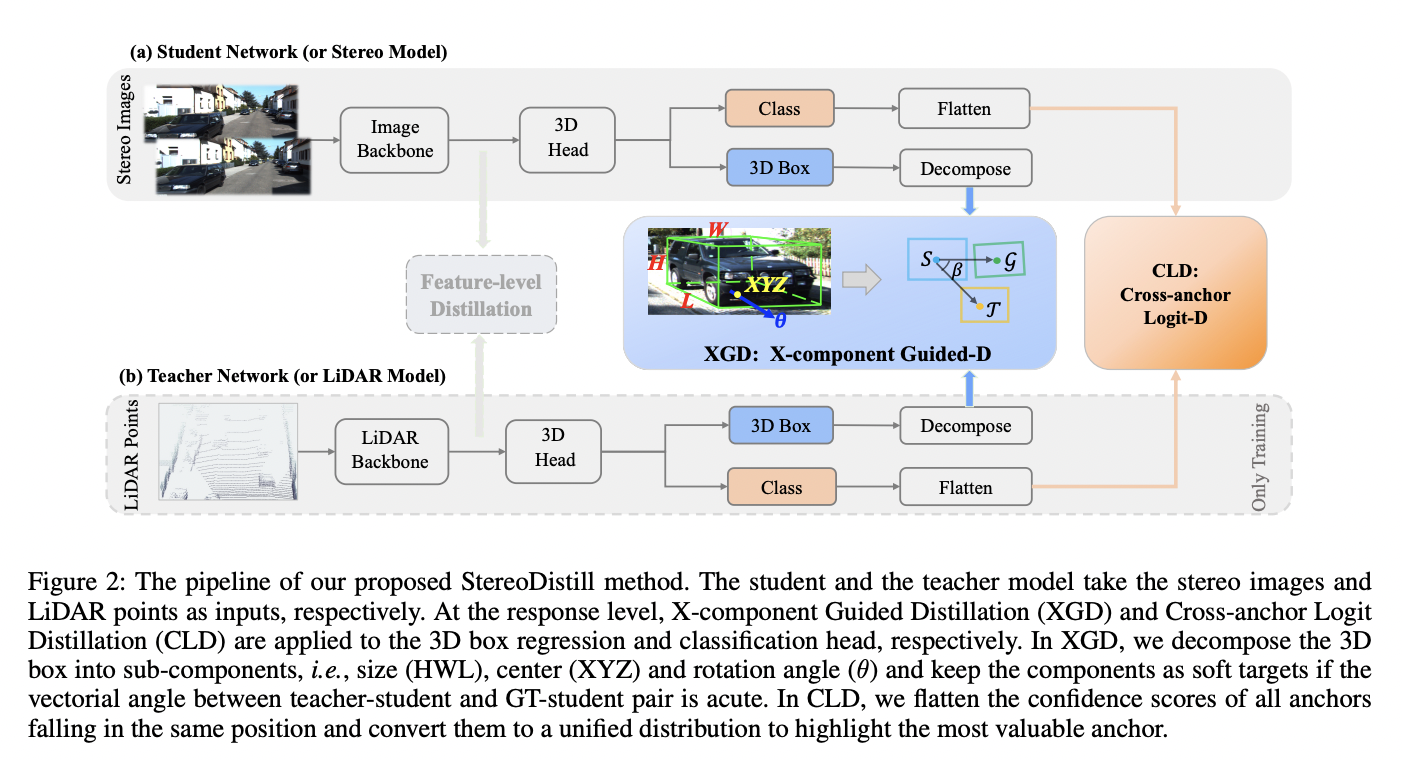
Researchers at Huazhong University and Baidu suggest a unique X-component Guided Distillation (XGD) from the response level to address the issue. The fundamental principle of XGD is to first break down a 3D box into sub-Xcomponents (X can be the center, size, or orientation angle), keeping the useful subcomponent as the soft target if the vector between the teacher’s X-component and the student’s component agrees with the vector between the ground truth and the student’s component, i.e., the two vectors are acutely angled. Because there is typically no overlap between objects in real autonomous driving scenarios, which is different in the 2D domain, they also discover that only one out of all anchors at the same position may be chosen as being in charge of a foreground item in the majority of cases.
The following is a summary of their main contributions:
• The suggested X-component Guided Distillation (XGD) for regression keeps the helpful X-component as soft targets under the guidance of acute-angled vectors, avoiding the detrimental effect of incorrect 3D boxes from the LiDAR model.
• Since objects in autonomous driving scenarios do not overlap, they introduce the straightforward but efficient Cross-anchor Logit Distillation (CLD) for classification to aggregate the probability distribution of all anchors at the same position rather than distilling the distribution at the anchor level.
• They demonstrate that stereo-based 3D object identification performance may be improved by cross-modal knowledge distillation at the response level. This observation led us to develop the quick and efficient Crossanchor Logit Distillation (CLD) for classification distillation in their StereoDistill. This distillation highlights the anchor with the highest probability by combining the confidence distributions of all the anchors into a single distribution.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 15k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.